
この記事は、Medium に公開されている「Is Transfer Learning Magic or Pure Genius?」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
転移学習とは、既存のモデルの学習結果を新しいモデルに利用することです。これは、膨大なデータセットで事前にトレーニングされた大規模な視覚モデルや言語モデルでよく行われます。これらのモデルは、数百万から数十億の学習パラメーターを持つことが多く、トレーニングには膨大な計算能力を必要とします。
2018年、Google は BERT (Bidirectional Encoder Representations from Transformers) をオープンソース化しました。BERT は、英語版 Wikipedia と Google の BooksCorpus (合計約 33 億語) を使って事前にトレーニングされた画期的な言語モデルです。BERT は、Google によって、64 個の TPU (Tensor Processing Units) で 4 日間かけてトレーニングされました。Google Cloud 上の V4-TPU のオンデマンド・コストは 3.22ドル/時間なので、BERT をゼロから訓練する概算コストは 19,800 ドル (1 ドル 148 円換算で 300 万円近く) になります。

画像の出展 (英語)
幸運なことに、BERT は転移学習の原理を使用して、増え続ける検索可能なコンテンツとクエリーに適応し、ユーザーの仕様に合わせてファイン・チューニングできます。転移学習の最大のメリットは、必要なトレーニング・データが大幅に少なく、通常はモデルの層の小さなチャンクの重みの更新に限定されるため、トレーニング時間と計算コストが軽減できます。
高レベルの概念を確認してみましょう
ゼロからの学習は、ネットワークの重みをゼロ、ランダム、または事前定義された値で初期化する従来のディープラーニング (DL) 手法です。モデルはバックプロパゲーション (誤差逆伝播) を使用して、目的関数とオプティマイザーに基づいてモデルの重みを更新します。このタイプのトレーニングは一般に計算コストが高く、GPU や HPU などのアクセラレーターを必要とし、完了までに数時間、数日、または数週間かかる場合があります。
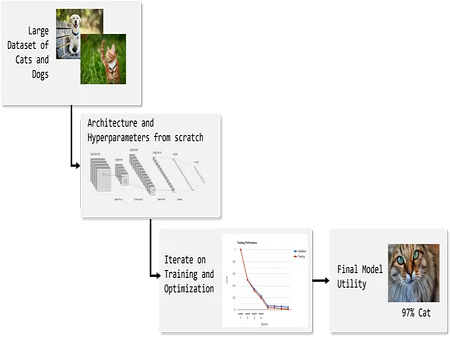
例: 猫と犬の大規模なデータセットを取得し、ニューラル・ネットワークを設計し、種に基づいて犬と猫に分類するようにゼロからトレーニングします。
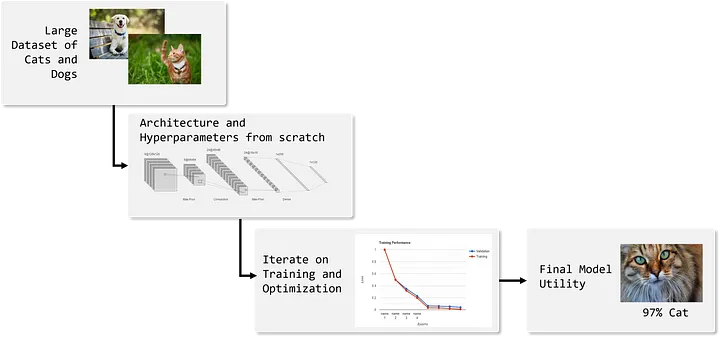
図 1: ゼロからの学習の例 — 出典: 著者による画像ドメイン適応型転移学習は、元のデータセットで事前にトレーニングされたモデルから開始し、全く異なるデータセットでモデルを再トレーニングします。これにより、モデルが新しい問題に適応し、以前のデータセットからの学習が転送されます。
例: ImageNet でトレーニングされた VGGNet (英語) などの事前トレーニング済みモデルから重みをロードし、モデルの浅い層を固定し、まったく異なるドメインで使用できるようにモデルをトレーニングします。以下は、製造ラインで不良品を検出する (英語) VGG-16 モデルの転移学習の例です。
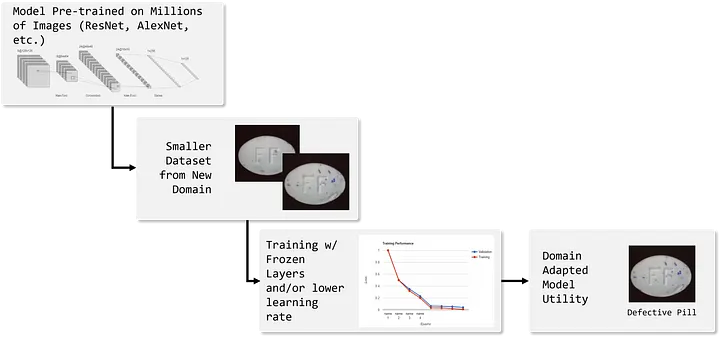
図 2: ドメイン適応型の例 — 出典: 著者による画像ファイン・チューニングは転移学習のサブカテゴリーであり、ドメインを切り替えるのではなく、既存のモデルを新しいデータで更新します。転移学習手法を通じて重みの一部を保持することを正当化できるように、元のデータセットは新しいデータよりもかなり大きくなければなりません。データセットが類似している場合は、新しいモデルをゼロからトレーニングする価値があるかもしれません。
例: オリジナルの BERT モデルを改良して、ツイートをユーモラスなものと攻撃的なものに分類したい場合、何千ものサンプルツイートを収集したら、それらを使用してオリジナルのモデルをチューニングし、新しいソースからのデータを分類できます。
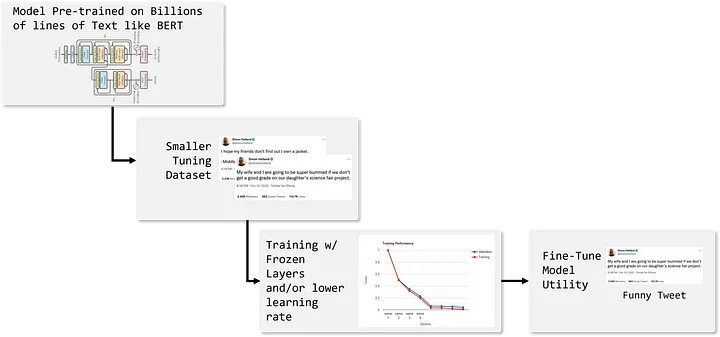
図 3: ファイン・チューニングの例 — 出典: 著者による画像
実際には、転移学習では通常、事前にトレーニングされたモデルのいくつかの基本層を固定し、ニーズに合わせて出力層 (ヘッド/分類器層とも呼ばれる) を調整する必要があります。場合によっては、層を固定する代わりに、または層の固定と並行して、非常に小さな学習率を使用することができます。学習率を小さくすることで、事前にトレーニングされた重みを維持しつつ、新しいデータセットからの微調整が可能になります。これらの手法の適用は簡単ですが、フレームワークごとに異なることに注意してください。
Keras (英語) と PyTorch* (英語) でいくつかの例を確認できます。
まとめと考察
転移学習は魔法ではなく、特殊能力と言えます。転移学習により、以前にトレーニングされたモデルの「スキル」をほかのデータセットで活用できるようになります。ただし、これは万能ではなく、慎重な計画性が求められることを覚えておいてください。
転移学習の主な利点
- トレーニング時間の短縮
- トレーニング・データセット要件の軽減
- 高価な高速ハードウェアではなく、一般的なハードウェアを活用できる柔軟性
- 新しいアプリケーション向けにアーキテクチャーを大幅に再設計する必要がない
転移学習の主な課題
- ターゲット・アプリケーション向けに、適切なレベルの関連性と複雑性を備えた事前トレーニング済みモデルの選択
- 十分なデータ量の判断
- 事前トレーニング済みの重みをどの程度摂動させるかの定義
法務上の注意書き: The definitions of transfer learning, domain adaptation, and fine-tuning are not clearly defined across the professional and academic community. At times people will use “fine-tuning” when referring to both fine-tuning and domain adaptive transfer learning. It is ultimately up to the individual to communicate the machine learning techniques they intend to apply.
