
この記事は、インテル® デベロッパー・ゾーンに公開されている「Tuning Guide for Deep Learning with Intel® AVX512 and Intel® Deep Learning Boost on 3rd Generation Intel® Xeon® Scalable Processors」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
この記事の PDF 版はこちらからご利用になれます。
原文公開日: 2021年8月17日
はじめに
本記事は、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) とインテル® ディープラーニング・ブースト (インテル® DL ブースト) を使用してディープラーニングを行っているユーザー向けです。ほとんどの状況で最高のパフォーマンスを達成するハードウェアとソフトウェアの設定に関する推奨事項を示します。ただし、これらのツールの展開方法はさまざまであり、特定のシナリオに合わせてこれらの設定を慎重に検討する必要があります。
第 3 世代インテル® Xeon® スケーラブル・プロセッサー・プラットフォームは、以下の優位性を持っています。
- 医療用画像処理、GAN、地震解析、ゲノム解読などで使用される 3D-CNN トポロジーなど、メモリー集約型のワークロードを高速に処理します。
- シンプルな
numactlコマンドを活用することで、バッチ数が少ない場合でも柔軟なコア制御とリアルタイム推論が可能です。 - 冗長なデータストレージや高価なキャッシュメカニズムによる追加コストを回避するため、大規模クラスター上でコスト効率の良い分散トレーニングを使用してデータソースで直接計算を行います。
- 同一クラスター上で複数の種類のワークロード (HPC/ビッグデータ/AI) をサポートして TCO を高めます。
- SIMD により高速化します。
- トレーニングと推論に同じインフラストラクチャーを使用できます。
- 開発者、専門家、学習者で構成される活発なエコシステムがあります。
ディープラーニングの段階
典型的なディープラーニング・アプリケーションには、データセットの準備、モデルのトレーニングとチューニング、モデルの最適化と移行学習、モデルの展開の 4 つの段階があります。

各段階では、以下のリソースの割り当てが必要になります。
- 計算能力
- メモリー
- データセットのストレージ
- 計算ノード間の通信リンク
- 最適化されたソフトウェア
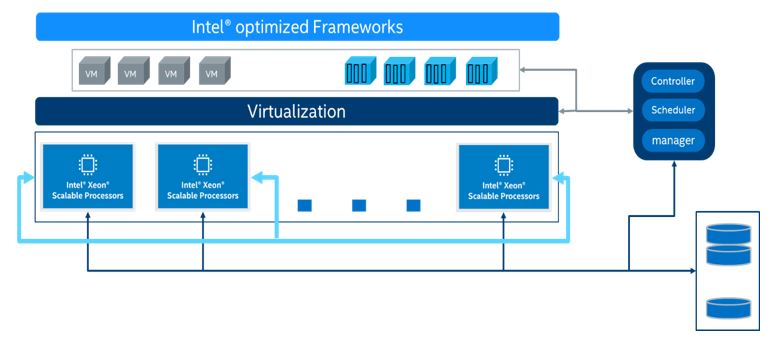
適切なリソースの組み合わせを選択することで、AI サービスの効率が大幅に向上します。データセットの準備、モデルのトレーニング、モデルの最適化、モデルの展開など、すべてのプロセスは、トレーニングと推論を行うマシンラーニング/ディープラーニング・プラットフォームをサポートする、第 3 世代インテル® Xeon® スケーラブル・プロセッサー・プラットフォームに適用できます。以下に、提案するインフラストラクチャーを示します。
インテル® AVX-512 とインテル® DL ブーストの導入
インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) は、x86 プロセッサー・ベースの SIMD (Single Instruction, Multiple Data ― 単一命令複数データ) 命令セットです。従来の「単一命令単一データ」命令と比較して、SIMD 命令では、1 つの命令で複数のデータ演算を実行することが可能です。インテル® AVX-512 は、その名のとおり 512 ビットのレジスター幅を持ち、16 個の 32 ビット単精度浮動小数点数または 64 個の 8 ビット整数をサポートしています。
インテル® Xeon® スケーラブル・プロセッサーは、複雑な AI ワークロードを含むさまざまなワークロードをサポートし、インテル® ディープ・ラーニング・ブースト (インテル® DL ブースト) を使用して AI 計算のパフォーマンスを向上します。インテル® DL ブーストには、インテル® AVX-512 命令セットを拡張したインテル® AVX-512 VNNI (ベクトル・ニューラル・ネットワーク命令) が含まれています。3 つの命令を 1 つにまとめて実行することができ、次世代のインテル® Xeon® スケーラブル・プロセッサーが持つ計算能力を最大限に引き出し、INT8 モデルの推論パフォーマンスを向上します。第 2 世代および第 3 世代のインテル® Xeon® スケーラブル・プロセッサーは、いずれも VNNI をサポートしています。

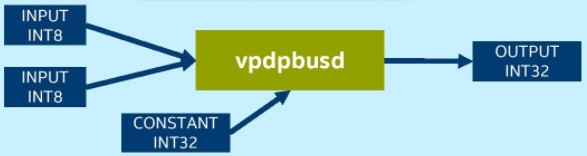
VNNI を使用しないプラットフォームでは、INT8 の畳み込み操作で乗累算を行うため、vpmaddubsw、vpmaddwd、および vpaddd 命令が必要です。

VNNI を使用するプラットフォームでは、INT8 の畳み込み操作には vpdpbusd 命令のみが必要です。
環境
本記事では、以下のハードウェアとソフトウェアを使用しました。
ハードウェア
ハードウェア構成は、第 3 世代インテル® Xeon® プロセッサーをベースにしています。サーバー・プラットフォーム、メモリー、ハードディスク、ネットワーク・インターフェイス・カードは、使用条件に合わせて決定できます。
| ハードウェア | モデル |
|---|---|
| サーバー・プラットフォーム | インテル® サーバー・プラットフォーム開発コード名 Coyote Pass |
| CPU | インテル® Xeon® Platinum 8380 CPU @ 2.30GHz |
| メモリー | 8x64GB DDR4、3200MT/s |
ソフトウェア
| ソフトウェア | バージョン |
|---|---|
| オペレーティング・システム | Ubuntu* 20.04.4 LTS |
| カーネル | 5.4.0 |
注: 本記事で説明するハードウェア構成は、第 3 世代インテル® Xeon® プロセッサーをベースにしています。サーバー・プラットフォーム、メモリー、ハードディスク、ネットワーク・インターフェイス・カードは、使用条件に応じて決定できます。
BIOS 設定
| 設定項目 | 推奨値 |
|---|---|
| プロセッサーの設定: インテル® ハイパースレッディング・テクノロジー | 有効 |
| SNC (Sub NUMA) | 無効 |
| ブート・パフォーマンス・モード | 最大パフォーマンス |
| インテル® ターボ・モード | 有効 |
| 電力とパフォーマンス: ハードウェア P ステート | ネイティブモード |
メモリー
すべての利用可能なメモリーチャネルを使用します。
CPU
インテル® AVX-512 アクセラレーション・モジュールの「FMA」は、計算パフォーマンスを引き出す重要なコンポーネントです。より高い計算パフォーマンスを達成するには、1 コアあたり 2つのインテル® AVX-512 計算モジュールを搭載したインテル® Xeon® Gold 6XXX プロセッサー以上を使用してください。
注: インテル® AVX-512 が CPUによってサポートされていることを確認するには、以下のコマンドを入力し、「flags」セクションで avx512 を探します。
$ cat /proc/cpuinfo
ネットワーク
ノード間にまたがるトレーニング・クラスターが必要な場合、25G/100G などの高速ネットワークを選択するとスケーラビリティーが向上します。
ハードドライブ
I/O 効率を高めるには、SSD や読み書き速度の速いドライブを使用します。
Linux* オペレーティング・システムの最適化
処理を高速化するには、Linux* オペレーティング・システムを並列プログラミング向けに最適化します。
OpenMP* パラメーターの設定
OpenMP* (英語) は並列プログラミングの仕様です。以下の環境変数を設定します。
- OMPNUMTHREADS = N (N はコンテナー内の CPU コア数)
- KMP_BLOCKTIME = 1 または 0 (実際のモデルに応じて設定)
- KMP_AFFINITY = 粒度 (粒度には、fine、verbose、compact、1、0 から指定)
CPU コア数
使用する CPU コアの数は、推論パフォーマンスに次のように影響します。
- バッチサイズが小さい場合 (オンラインサービスなど)、CPU コア数が増えると推論スループットの向上は徐々に小さくなります。使用するモデルにもよりますが、サービス展開では 8~16 CPU コアが推奨されます。
- バッチサイズが大きい場合 (オフラインサービスなど)、CPU コア数が増えると推論スループットは直線的に増加する可能性があります。サービス展開では 20 CPU コア以上が推奨されます。
# taskset -C xxx-xxx -p pid (サービスで使用する CPU コア数を制限する)
NUMA 構成
NUMA ベースのサーバーでは、同じノードで NUMA を構成すると、異なるノードで使用する場合と比較して、通常 5~10% パフォーマンスが向上します。
#numactl -N NUMA_NODE -l command args ... (サービスで動作する NUMA ノードを制御する)
Linux* パフォーマンス・ガバナ―
効率性を重視します。最高のパフォーマンスを達成するため、CPU 周波数をピークに設定します。
# cpupower frequency-set -g performance
CPU C ステートの設定
各 CPU には、C ステートまたは C モードと総称されるいくつかの電力モードが用意されています。CPU がアイドル状態のときに消費電力を抑えるため、CPU を低電力モードにすることができます。C ステートを無効にすることで、パフォーマンスが向上する可能性があります。
#cpupower idle-set -d 2,3
TensorFlow* 向けインテル® オプティマイゼーション
TensorFlow* は、大規模なマシンラーニング (ML) とディープラーニング (DL) アプリケーションで使用されているディープラーニング・フレームワークの 1 つです。2016年から、インテルと Google* のエンジニアは、インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) を使用して、インテル® Xeon® スケーラブル・プロセッサー・プラットフォーム上で TensorFlow* パフォーマンスの最適化と、トレーニングおよび推論パフォーマンスの高速化に取り組んできました。
TensorFlow* 向けインテル® オプティマイゼーションの展開
ステップ 1: Python* 3.x 環境をインストールします。以下の例は、Anaconda* を使用して Python* 3.6 をビルドする方法を示します。
参考資料: https://www.anaconda.com/products/individual (英語)
Anaconda* の最新バージョンをダウンロードしてインストールします。
# wget https://repo.anaconda.com/archive/Anaconda3-2020.02-Linux-x86_64.sh # sh Anaconda3-2020.02-Linux-x86_64.sh # source /root/.bashrc # conda install python=3.6 (create a Python3.6 environment) #(base) [root@xx]# python -V Python 3.6.10
ステップ 2: TensorFlow* 向けインテル® オプティマイゼーション (intel-tensorflow) をインストールします。
最新バージョン (2.x) をインストールします。
# pip install intel-tensorflow
tensorflow1.x をインストールする必要がある場合は、第 3 世代インテル® Xeon® スケーラブル・プロセッサー・プラットフォームのパフォーマンス・アクセラレーションを利用するため、以下のバージョンをインストールすることを推奨します。
# pip install https://storage.googleapis.com/intel-optimized-tensorflow/intel_tensorflow-1.15.0up2-cp36-cp36m-manylinux2010_x86_64.whl
ステップ 3: ランタイム最適化パラメーターを設定します。
参考資料:
https://github.com/IntelAI/models/blob/master/docs/general/tensorflow/GeneralBestPractices.md (英語)
通常、推論には以下の 2 つの方法があり、それぞれ異なる最適化設定を用います。
バッチ推論: バッチサイズ > 1。1 秒間に処理可能な入力テンソル数を測定します。通常、同じ CPU ソケット内のすべての物理コアをバッチ推論に使用することで、最高のパフォーマンスが得られます。
オンライン推論 (リアルタイム推論とも呼ばれる): バッチサイズ = 1。1 つの入力テンソルを処理するのに必要な時間を表します (バッチサイズ = 1の場合)。リアルタイム推論では、最適なスループットを達成するため、複数のインスタンスを同時に実行します。
システムの物理コア数を取得します。
現在の物理コア数を確認するには、以下のコマンドを使用することを推奨します。
# lscpu | grep "Core(s) per socket" | cut -d':' -f2 | xargs
このコマンドは、すべてのソケットのすべての物理コアの一覧を取得するのにも使用できます。
$ lscpu -b -p=Core,Socket | grep -v '^#' | sort -u | wc -l
この例では、物理コアを 8 個と仮定します。
最適化パラメーターを設定します。
最適化パラメーターは、以下の 2 つの方法で設定します。ニーズに合わせて設定方法を選択できます。
方法 1: 環境パラメーターを直接設定します。
export OMP_NUM_THREADS=physical cores export KMP_AFFINITY="granularity=fine,verbose,compact,1,0" export KMP_BLOCKTIME=1 export KMP_SETTINGS=1
方法 2: 実行中の Python* コードに環境変数を追加します。
import os os.environ["KMP_BLOCKTIME"] = "1" os.environ["KMP_SETTINGS"] = "1" os.environ["KMP_AFFINITY"]= "granularity=fine,verbose,compact,1,0" if FLAGS.num_intra_threads > 0: os.environ["OMP_NUM_THREADS"]= # <physical cores> config = tf.ConfigProto() config.intra_op_parallelism_threads = # <physical cores> config.inter_op_parallelism_threads = 1 tf.Session(config=config)
FP32/INT8 対応の TensorFlow* 向けインテル® オプティマイゼーションの DL モデルを使用した推論
ここでは、主に ResNet50 での推論ベンチマークの実行方法について説明します。その他のマシンラーニング/ディープラーニング・モデルを使った推論については、以下を参考にしてください。
参考資料: https://github.com/IntelAI/models/blob/master/docs/image_recognition/tensorflow/Tutorial.md (英語)
例えば、ResNet50 の推論ベンチマークでは、モデル推論で FP32、BFloat16、INT8 がサポートされています。
参考資料: https://github.com/IntelAI/models/blob/master/benchmarks/imagerecognition/tensorflow/resnet50v15/README.md
FP32 ベースのモデル推論:
https://github.com/IntelAI/models/blob/master/benchmarks/imagerecognition/tensorflow/resnet50v15/README.md#fp32-inference-instructions
INT8 ベースのモデル推論:
https://github.com/IntelAI/models/blob/master/benchmarks/imagerecognition/tensorflow/resnet50v15/README.md#int8-inference-instructions
FP32/INT8 対応の TensorFlow* 向けインテル® オプティマイゼーションの DL モデルを使用したトレーニング
ここでは、主に ResNet50 でのトレーニング・ベンチマークの実行方法について説明します。その他のマシンラーニング/ディープラーニング・モデルを使ったトレーニングについては、以下を参考にしてください。
FP32 ベースのトレーニング:
https://github.com/IntelAI/models/blob/master/benchmarks/imagerecognition/tensorflow/resnet50v15/README.md#fp32-training-instructions
アプリケーション – TensorFlow* 向けインテル® オプティマイゼーションのワイド & ディープモデルを使用した推論とトレーニング
データセンターにおける代表的なアプリケーションは、ユーザーと注目するコンテンツをマッチングするためレコメンデーション・システムを利用します。レコメンデーション・システムは情報フィルタリングの一種で、プロフィールや過去の行動記録からユーザーの興味を学習し、与えられたアイテムに対する評価や嗜好を予測するシステムです。ビジネスとユーザーのコミュニケーション方法を変え、インタラクションを強化します。
ディープラーニングを利用すると、大量の複雑な生データから、従来の仕組みでは表現が困難な特徴間の深い相互作用を、人工特徴エンジニアリングを用いて見つけることができます。その結果、ワイド & ディープ、DeepFM、FNN、DCN などのモデルが得られます。
例えば、ワイド & ディープモデルの場合、線形モデルの記憶能力と DNN モデルの一般化能力の両方を活用し、トレーニング時にこれらのモデルのパラメーターを同時に最適化します。これにより、モデル全体の予測能力が向上します。その構造を以下に示します。
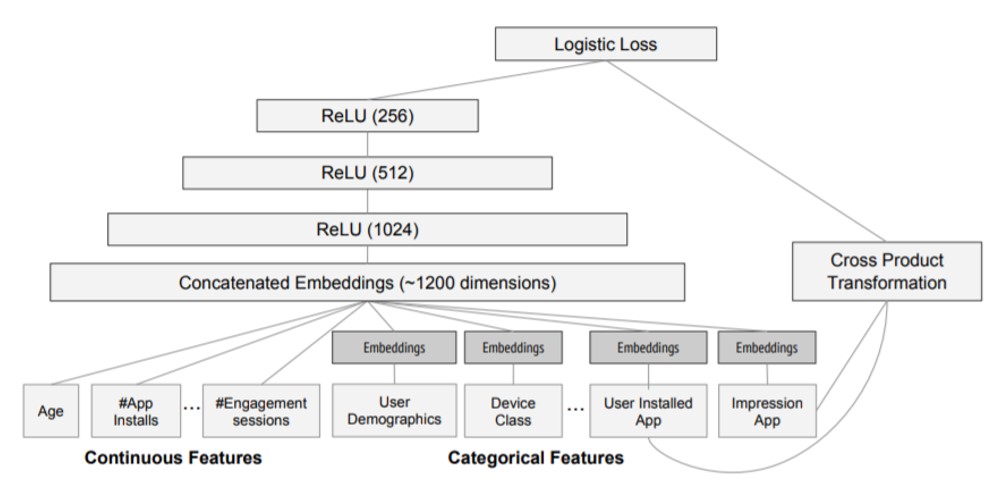
ワイド
「ワイド」は、一般化線形モデルであり、その入力は主にオリジナル特徴と対話的特徴です。クロス積変換を使用して、K グループの対話的特徴を構築できます。
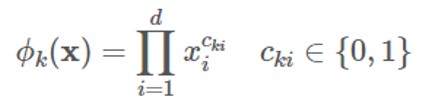
ディープ
「ディープ」は DNN モデルであり、各層の計算は次のように行われます。
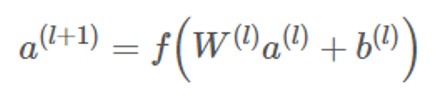
共トレーニング
ワイド & ディープモデルは、統合の代わりに、共トレーニング (co-training) を使用します。共トレーニングは損失関数を共有し、モデルのいずれかの部分のパラメーターを同時に更新するのに対し、統合は N 個のモデルを個別にトレーニングしてから融合するという違いがあります。そのため、モデル の出力は次のようになります。
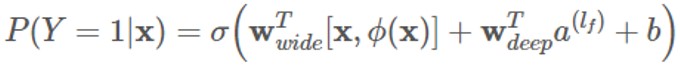
ワイド & ディープモデルの推論ベンチマークを実行する方法については、以下を参照してください。
参考資料:
https://github.com/IntelAI/models/blob/master/docs/recommendation/tensorflow/Tutorial.md (英語)
データセットの準備:
https://github.com/IntelAI/models/tree/master/benchmarks/recommendation/tensorflow/widedeeplarge_ds#Prepare-dataset (英語)
FP32 ベースのモデル推論:
https://github.com/IntelAI/models/tree/master/benchmarks/recommendation/tensorflow/widedeeplarge_ds#fp32-inference-instructions (英語)
INT8 ベースのモデル推論:
https://github.com/IntelAI/models/tree/master/benchmarks/recommendation/tensorflow/widedeeplarge_ds#int8-inference-instructions (英語)
FP32 ベースのトレーニング:
https://github.com/IntelAI/models/tree/master/benchmarks/recommendation/tensorflow/widedeeplarge_ds#fp32-training-instructions (英語)
インテル® マス・カーネル・ライブラリー (インテル® MKL) のスレッドプール・ベースの TensorFlow* (オプション)
TensorFlow* 2.3.0 から、新しい機能が追加されました。TensorFlow* のソースコードをコンパイルする際に、-config=mkl ではなく、-config=mkl_threadpool コンパイラー・オプションを使用することで、OpenMP* ではなく Eigen Threadpool を TensorFlow* のマルチスレッド・サポートに選択できるようになりました。
TensorFlow* 1.15 でこの機能を試す場合は、インテルによって移植および最適化されたソースコードをダウンロードしてコンパイルする必要があります (Bazel* 0.24.1 がインストールされていなければなりません)。
# git clone https://github.com/Intel-tensorflow/tensorflow.git # git checkout -b tf-1.15-maint remotes/origin/tf-1.15-maint # bazel --output_user_root=$BUILD_DIR build --config=mkl_threadpool -c opt --copt=-O3 //tensorflow/tools/pip_package:build_pip_package bazel-bin/tensorflow/tools/pip_package/build_pip_package $BUILD_DIR
上記の手順が正常に完了すると、TensorFlow* wheel ファイルが $BUILD_DIR パス 以下に生成されます (例: tensorflow-1.15.0up2-cp36-cp36m-linux-x86_64.whl)。インストール手順を以下に示します。
# pip uninstall tensorflow # pip install $BUILD_DIR/<filename>.whl --user
PyTorch* ディープラーニング・フレームワークの使用
PyTorch* の展開
参考資料: https://www.intel.com/content/www/us/en/developer/articles/guide/getting-started-with-intel-optimization-of-pytorch.html (英語)
環境: Python* 3.6 以上
ステップ 1: PyTorch* の公式ウェブサイト https://pytorch.org/ (英語) にアクセスします。
ステップ 2: CPU を選択します。
現在、インテル® oneDNN は PyTorch* の公式バージョンに統合されているため、追加のインストールなしで、インテル® Xeon® スケーラブル・プロセッサー・プラットフォームで優れたパフォーマンスを発揮できます。CUDA* は [None] を選択します。詳細は下図を参照してください。
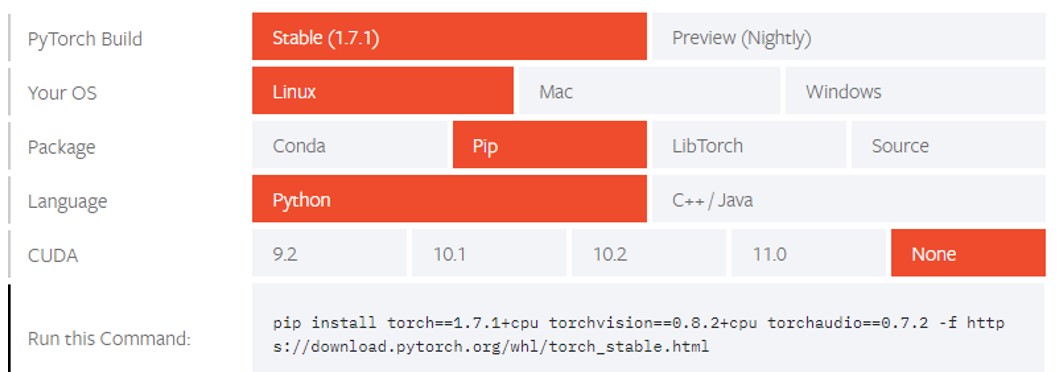
ステップ 3: インストールします。
pip install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
PyTorch* ベースのディープラーニング・モデルのトレーニングと推論における最適化の推奨事項
インテル® Xeon® スケーラブル・プロセッサー・プラットフォーム上での PyTorch* の最適化パラメーター設定については、以下のサイトを参照してください。
参考資料: https://www.intel.com/content/www/us/en/developer/articles/technical/how-to-get-better-performance-on-pytorchcaffe2-with-intel-acceleration.html (英語)
PyTorch* 向けインテル® エクステンションの使用
PyTorch* 向けインテル® エクステンションは、インテル® Xeon® プロセッサー上で PyTorch* の計算パフォーマンスを向上することを目的とした PyTorch* の Python* 拡張です。追加の機能に加えて、新しいインテル® ハードウェア向けのパフォーマンスの最適化を提供します。
PyTorch* 向けインテル® エクステンションの GitHub* リンク:
https://github.com/intel/intel-extension-for-pytorch (英語)
https://github.com/oneapi-src/oneAPI-samples/tree/master/AI-and-Analytics/Features-and-Functionality/IntelPyTorchExtensionsAutoMixedPrecision
インテル® DL ブーストの VNNI によるレコメンデーション・システムにおけるベクトルリコールの高速化
レコメンデーション・システムにおいて解決すべき問題は、与えられたユーザーに対して、その興味やニーズにできるだけマッチした (高精度)、長さ K のレコメンデーション・リストをできるだけ高速 (低レイテンシー) に生成することです。従来の推薦システムには、「ベクトルリコール」と「ランキング」という 2 つのコンポーネントがあります。「ベクトルリコール」は、膨大なレコメンデーション・プールからユーザーが最も興味を持ちそうな数百、数千のアイテムを大まかにフィルタリングし、その結果をランキングモジュールに渡してソートしてから、最終的なレコメンデーション結果を生成します。
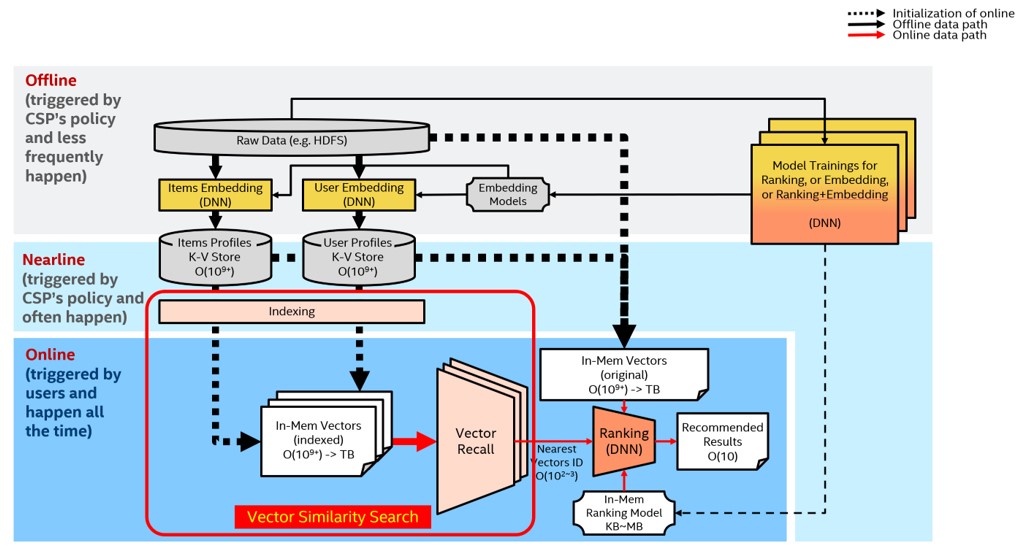
ベクトルリコールは高次元ベクトル類似性探索問題に変換できます。
HNSW (Hierarchical Navigable Small World) アルゴリズムは、グラフ構造に基づく近似最近傍 (ANN) ベクトル類似性探索アルゴリズムの一種であり、最も高速かつ高精度なアルゴリズムの 1 つです。
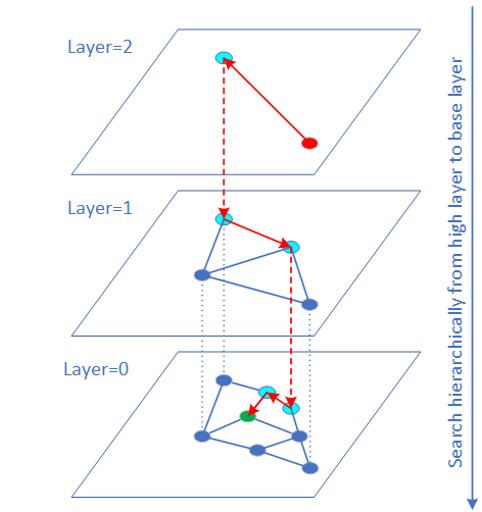
通常、生ベクトルデータのデータ型は FP32 です。多くのアプリケーション (画像検索など) では、ベクトルデータは INT8/INT6 で表現でき、量子化誤差が最終的な検索結果に与える影響は限定的です。「VNNI 組込み」命令は、INT8/INT6 ベクトルに対する内積計算に使用できます。多くの実験から、QPS のパフォーマンスが大幅に向上し、再現率はほとんど変わらないことが分かっています。QPS のパフォーマンスが向上した理由は、INT8/INT16 のメモリー帯域幅比が FP32 よりも小さいことと、VNNI 命令によって距離計算が高速化されたことによります。
現在、最適化されたソースコードは、オープンソース・プロジェクトである HNSWLib[10] をベースに実装されています。また、業界で広く使われているフレームワーク Faiss[1] にもすでに移植されています。
最適なパフォーマンスを得るため、以下を推奨します。
- NUMA をバインドする
- 各物理 CPU コアが 1 つのクエリープロセスを実行する
リファレンス・コマンド (例えば、1 ソケット、24 コアを使用する場合):
# numactl -C 0-23 <test_program>
データセットが大きい場合 (例えば、1 億から数十億の範囲)、従来のアプローチは、データセットをいくつかの小さなデータセットにスライスして、各データセットの topK を別々に取得し、最後にそれらをマージして戻します。マシン間の通信量が増えるため、レイテンシーも増加し、QPS のパフォーマンスは低下します。大規模データセットに対する HNSW の経験から、可能であればデータセットをスライスせず、完全なデータセットに対してインデックスを作成して検索を実行するほうが、高いパフォーマンスが得られることが分かっています。データセットが大きすぎて DDR 領域 (ローカルメモリー領域など) に収まらない場合、PMem (インテル® Optane™ パーシステント・メモリー) の利用を検討することもできます。
HNSW layer0 のデータを PMEM に保存することで、対応可能なデータセットのサイズが大幅に増加します (1 つのソケットで最大 40 億レコード @d=100 の INT8 データベースをサポート可能)。永続性により、大量のデータの読み込む必要がないため、初期化にかかる時間を大幅に短縮できます。
AI ニューラル・ネットワーク・モデルの量子化
AI ニューラル・ネットワークの量子化処理
ニューラル・ネットワークの計算は、主に畳み込み層と全結合層に集約されます。この 2 つの層での計算は次のように表すことができます: Y = X * 重み + バイアス。したがって、パフォーマンスを最適化するため、行列乗算に注目するのは自然なことです。ニューラル・ネットワーク・モデルの量子化は、パフォーマンスと精度 (限定的) の向上のトレードオフです。行列演算を 32 ビット浮動小数点数から低精度整数に置き換えることで、計算を高速化するだけでなく、モデルを圧縮し、メモリー帯域幅を節約できます。
ニューラル・ネットワーク・モデルの量子化には、3 つのアプローチがあります。
- PTQ (Post-Training Quantization): ほとんどの AI フレームワークでサポートされています。
- QAT (Quantization-Aware-Training): トレーニングが収束した時点で FP32 モデルに FakeQuantization ノードを挿入します。これは量子化によって発生するノイズを増加させます。トレーニングのバックプロパゲーション (誤差逆伝播) 段階で、モデルの重みが有限区間内になるため、量子化の精度が向上します。
- DQ (Dynamic Quantization): PTQ と非常によく似ています。どちらもトレーニング後のモデルに対して使用される量子化手法です。違いは、DQ では活性化層での量子化係数がニューラル・ネットワーク・モデルの実行時に使用するデータ範囲によって動的に決定されるのに対し、PTQ では小規模な前処理済みデータセットのサンプルを用いて活性化層でのデータ分布と範囲情報を取得し、新たに生成した量子化モデルに恒久的に記録します。後述するインテル® ニューラル・コンプレッサーの onnxruntime はこの方式をバックエンドのみでサポートしています。
ニューラル・ネットワークのトレーニング後の量子化の基本的な手順は、以下のとおりです。
- FP32 OP を INT8 OP に融合します。例えば、MatMul、BiasAdd、ReLU は、全結合層で 1 つの量子化 OP である QuantizedMatMulWithBiasAndRelu に融合できます。ニューラル・ネットワークのフレームワークによって、融合可能な OP は異なります。後述するインテル ® ニューラル・コンプレッサーの場合、TensorFlow* でサポートされる融合可能な OP の一覧は以下のページで確認できます。
https://github.com/intel/neural-compressor/blob/master/neural_compressor/adaptor/tensorflow.yaml (英語) -
重みを量子化し、量子化されたモデルに保存します。
-
キャリブレーション・データセットをサンプリングして入力/活性化層を量子化し、活性化層のデータの分布と範囲情報を取得し、新しく生成された量子化モデルに記録します。
-
再量子化 OP は、対応する INT8 OP に融合され、最終的な量子化モデルが生成されます。
pyTorch* でサポートされる融合可能な OP の一覧は以下のページで確認できます。
https://github.com/intel/neural-compressor/blob/master/neuralcompressor/adaptor/pytorchcpu.yaml (英語)
例えば、2 層の MatMul を含む簡単なモデルでは、量子化プロセスは以下のようになります。
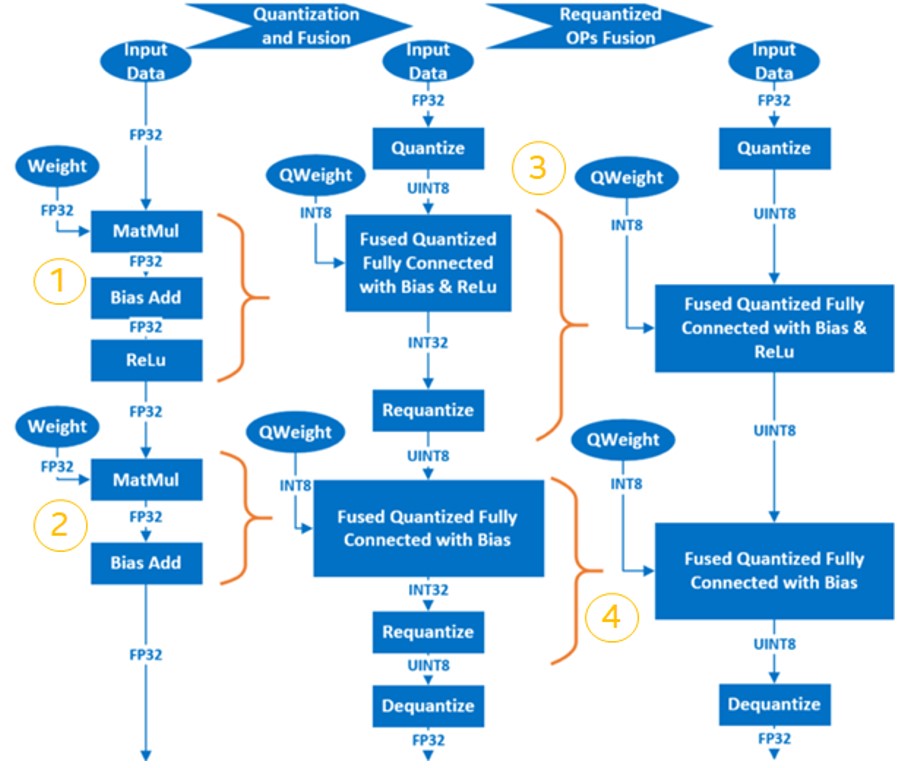
インテル® ニューラル・コンプレッサー
インテル® ニューラル・コンプレッサー (英語) は、インテル® oneAPI AI アナリティクス・ツールキットの主要な AI ソフトウェア・コンポーネントの 1 つで、インテルの CPU と GPU 上で動作するオープンソースの Python* ライブラリーです。このツールキットは、量子化、プルーニング、知識蒸留などの一般的なネットワーク圧縮技術に対して、複数のディープラーニング・フレームワークにわたる統一されたインターフェイスを提供します。このツールは、ユーザーが最適な量子化モデルを素早く見つけられるように、精度を意識した自動チューニングをサポートしています。また、事前に定義された目標を使用してプルーニングしたモデルを生成するため、異なるウェイト・プルーニング・アルゴリズムを実装し、教師モデルから生徒モデルへの知識の蒸留を支援します。
参考資料: https://github.com/intel/neural-compressor (英語)
インテル® ニューラル・コンプレッサーは、現在、インテルにより最適化された以下のディープラーニング・フレームワークをサポートしています。
- Tensorflow* (英語)
- PyTorch* (英語)
- Apache* MXNet (英語)
- ONNX* ランタイム (英語)
すでに検証済みのフレームワークとそのバージョンを以下に示します。
| OS | Python* | フレームワーク | バージョン |
| CentOS* 7.8 | 3.6 | TensorFlow* | 2.2.0 |
| Ubuntu* 18.04 | 3.7 | 1.15.0 UP1 | |
| 1.15.0 UP2 | |||
| 2.3.0 | |||
| 2.1.0 | |||
| 1.15.2 | |||
| PyTorch* | 1.5.0 + cpu | ||
| Apache* MXNet | 1.7.0 | ||
| 1.6.0 | |||
| ONNX* ランタイム | 1.6.0 |
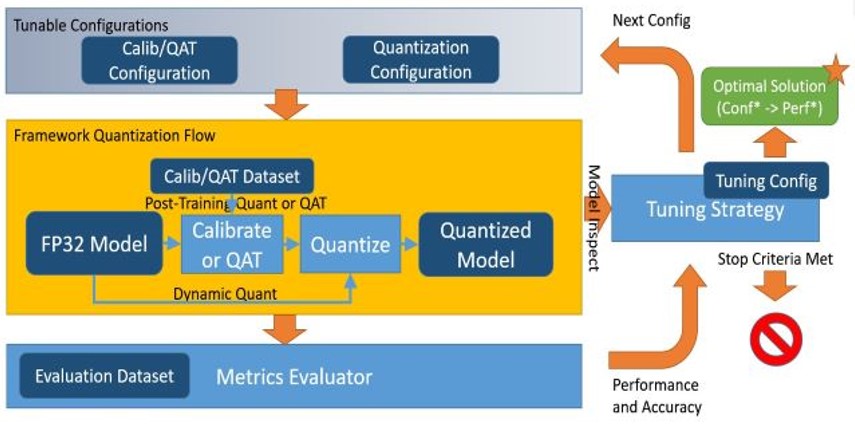
インテル® ニューラル・コンプレッサーは以下のチューニング手法をサポートしています。
インテル® ニューラル・コンプレッサーのワークフローを以下に示します。設定されたチューニング手法に応じて、精度損失目標に合致するモデル量子化パラメーターが自動的に選択され、量子化モデルが生成されます。
インテル® ニューラル・コンプレッサーのインストール
インストールに関する詳細は、https://github.com/intel/neural-compressor#installation (英語) を参照してください。
ステップ 1: Anaconda* を使用して、lpot という名前で Python* 3.x の仮想環境を作成します。この例では、Python* 3.7 を使用しています。
# conda create -n lpot python=3.7 # conda activate lpot
ステップ 2: lpot をインストールします。以下の 2 つのインストール方法があります。
バイナリーファイルを使用してインストールします。
# pip install lpot
ソースコードからインストールします。
# git clone https://github.com/intel/neural-compressor.git # cd lpot # pip install –r requirements.txt # python setup.py install
インテル® ニューラル・コンプレッサーの使用
ここでは、ResNet50 v1.0 を例に量子化を行う方法を説明します。
データセットの準備
ステップ 1: ImageNet 検証用データセットをダウンロードして展開します。
# mkdir –p img_raw/val && cd img_raw # wget http://www.image-net.org/challenges/LSVRC/2012/dd31405981ef5f776aa17412e1f0c112/ILSVRC2012_img_val.tar # tar –xvf ILSVRC2012_img_val.tar -C val
ステップ 2: 画像ファイルをラベル順に子ディレクトリーに移動します。
# cd val # wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash
ステップ 3: prepare_dataset.sh (英語) スクリプトを使用して生データを TFrecord 形式に変換します。
# cd examples/tensorflow/image_recognition # bash prepare_dataset.sh --output_dir=./data --raw_dir=/PATH/TO/img_raw/val/ --subset=validation
モデルの準備
# wget https://storage.googleapis.com/intel-optimized-tensorflow/models/v1_6/resnet50_fp32_pretrained_model.pb
チューニング
examples/tensorflow/imagerecognition/resnet50v1.yaml ファイルを編集します。quantization: の calibration: 以下、および evaluation: の accuracy: と performance: 以下のデータセットのパスを、ユーザーの実際のローカルパスに設定します。これは、データ準備段階で生成された TFrecord データが配置されている場所である必要があります。
# cd examples/tensorflow/image_recognition/tensorflow_models/quantization/ptq # bash run_tuning.sh --config=resnet50_v1.yaml \n --input_model=/PATH/TO/resnet50_fp32_pretrained_model.pb \n --output_model=./lpot_resnet50_v1.pb
ベンチマークの実行
# bash run_benchmark.sh --input_model=./lpot_resnet50_v1.pb --config=resnet50_v1.yaml
以下に出力を示します。パフォーマンス・データは参考値です。
Accuracy mode benchmark result:
Accuracy is 0.739
Batch size = 32
Latency: (results will vary)
Throughput: (results will vary)
Performance mode benchmark result:
Accuracy is 0.000
Batch size = 32
Latency: (results will vary)
Throughput: (results will vary)
インテル® ディストリビューションの OpenVINO™ ツールキットによる推論の高速化
インテル® ディストリビューションの OpenVINO™ ツールキット
製品ウェブサイトとダウンロード:
https://www.xlsoft.com/jp/products/intel/openvino/index.html
オンライン・ドキュメント:
https://docs.openvino.ai/latest/index.html (英語)
インテル® ディストリビューションの OpenVINO™ ツールキットは、コンピューター・ビジョンやディープラーニング・アプリケーション開発を加速します。インテル® Xeon® プロセッサー・プラットフォーム上の CPU、GPU、FPGA、インテル® Movidius™ VPU など、さまざまなアクセラレーターでディープラーニング・アプリケーションをサポートし、ヘテロジニアス実行も直接サポートします。
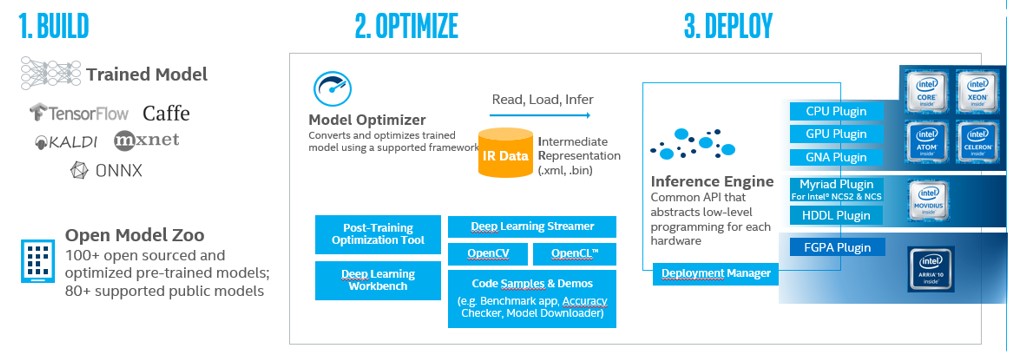
インテル® ディストリビューションの OpenVINO™ ツールキットは、コンピューター・ビジョン処理およびディープラーニング推論ソリューションのパフォーマンス向上と開発期間の短縮を目的として設計されたツールキットです。コンピューター・ビジョンとディープラーニング開発キットの 2 つのコンポーネントが含まれています。
インテル® ディープラーニング・デプロイメント・ツールキット (インテル® DLDT) は、ディープラーニングの推論パフォーマンスを高速化するクロスプラットフォーム・ツールで、以下のコンポーネントが含まれます。
- モデル・オプティマイザー: Caffe*、TensorFlow*、MXNet などのフレームワークでトレーニングしたモデルを中間表現 (IR) に変換します。
- 推論エンジン: CPU、GPU、FPGA、VPU などのハードウェア上で IR を実行します。ハードウェア・アクセラレーション・キットを自動的に呼び出して、推論パフォーマンスを高速化します。
インテル® ディストリビューションの OpenVINO™ ツールキットのワークフローを以下に示します。
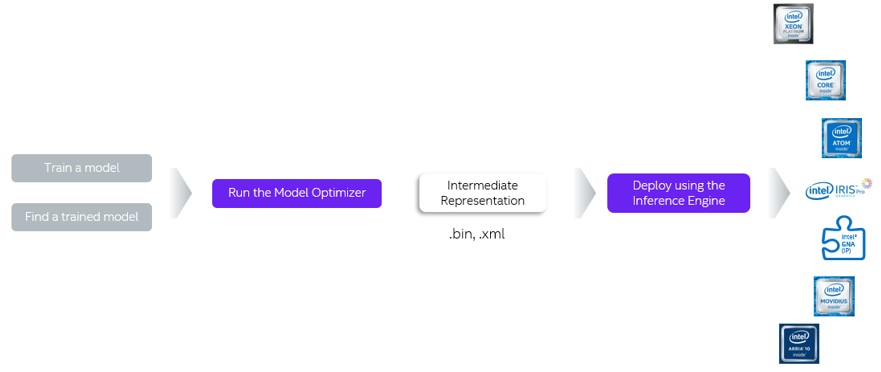
インテル® ディストリビューションの OpenVINO™ ツールキットによる INT8 推論の高速化
INT8 ベースのモデルで推論を行い、インテル® Xeon® スケーラブル・プロセッサー・プラットフォームのインテル® DL ブーストで高速化することで、推論効率を大幅に向上できます。同時に、計算リソースを節約し、消費電力を抑えることができます。インテル® ディストリビューションの OpenVINO™ ツールキット 2020 以降では、FP32 ベースのモデルの量子化をサポートする INT8 量子化ツールを提供しています。
この INT8 ベースのモデル量子化ツールは、Post-training Optimization Toolkit (POT) を使用して、トレーニング済みモデルの最適化と量子化を行います。モデルの再トレーニングや微調整、モデル構造の変更は必要ありません。インテル® ディストリビューションの OpenVINO™ ツールキットを使用して、新しいモデルを最適化するプロセスを以下に示します。
ステップ 0: トレーニング・モデルを取得します。
ステップ 1: POT を生成して最適化します。
ステップ 2: [オプション] 精度を高めるため、実際の状況に応じてモデルの微調整を行うかどうかを決定します。
ステップ 3: インテル® ディストリビューションの OpenVINO™ ツールキットでモデルの推論を行います。
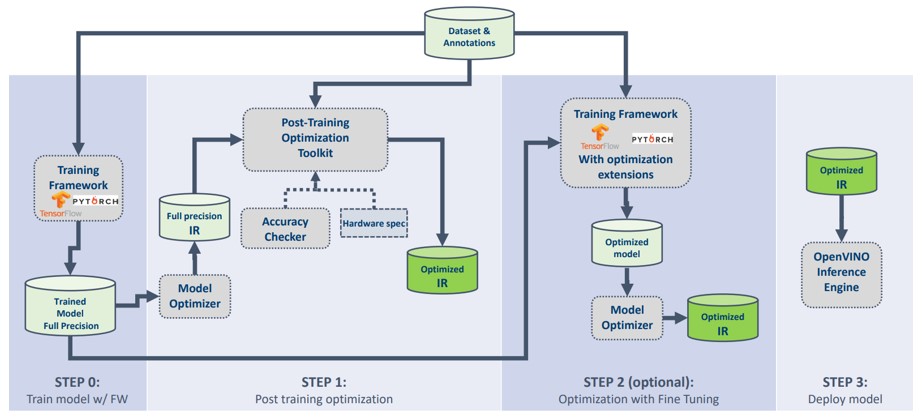
POT は独立したコマンドライン・ツールと Python* API を提供し、主に以下の機能をサポートします。
- 2 種類のトレーニング後の INT8 量子化アルゴリズム: 高速な DefaultQuantization (英語) と高精度の AccuracyAwareQuantization (英語)
- TPE (Tree-structured Parzen Estimator) によるトレーニング後の量子化パラメーターのグローバルな最適化
- 対称/非対称の量子化をサポート
- 複数のハードウェア・プラットフォーム (CPU、GPU) に対応した圧縮をサポート
- 畳み込み層と全結合層のすべてのチャネルの量子化
- コンピューター・ビジョン、レコメンデーション・システムなど、さまざまなアプリケーションに対応可能
- 提供される API により、カスタマイズされた最適化手法を提供
操作方法や使用方法については、以下のウェブサイトを参照してください。
Post-Training Optimization Toolkit の概要 (英語)
Post-training Optimization Toolkit のベスト・プラクティス (英語)
Post-training Optimization Toolkit の FAQ (英語)
OpenVINO™ ディープラーニング・ワークベンチ (DL Workbench) のウェブ・インターフェイスを使用した INT8 量子化と最適化 (https://docs.openvino.ai/latest/workbench_docs_Workbench_DG_Int_8_Quantization.html)
インテル® DAAL によるマシンラーニングの高速化
現在、マシンラーニングは人工知能 (AI) の 1 つの分野として大きな注目を集めており、マシンラーニングを利用したアナリティクスも人気を集めています。その理由は、ほかのアナリティクスと比較した場合、マシンラーニングは IT スタッフ、データ・サイエンティスト、そして多くのビジネスチームと組織が、AI の強みを素早く発揮するのに役立つからです。さらに、マシンラーニングは多くの新しい商用およびオープンソースのソリューションを提供しており、開発者に大きなエコシステムを提供しています。開発者は、scikit-learn*、Cloudera*、Spark* MLlib など、さまざまなオープンソースのマシンラーニング・ライブラリーから選択することができます。
インテル® ディストリビューションの Python*
インテル® ディストリビューションの Python* は、AI ソフトウェア開発者向けの Python* 開発ツールキットです。インテル® Xeon® スケーラブル・プロセッサー・プラットフォーム上で Python* の計算を高速化できます。Anaconda* で利用できるほか、Conda、PIP、APT GET、YUM、Docker* などでインストールして利用することが可能です。
リファレンスとダウンロード・サイト: https://www.intel.com/content/www/us/en/developer/tools/oneapi/distribution-for-python.html (英語)
インテル® ディストリビューションの Python* の機能:
- すぐに使えます。Python* アプリケーションを高速化ため、ソースコードの変更は全く、あるいはほとんど必要ありません。
- インテル® パフォーマンス・ライブラリーが統合されています。インテル® マス・カーネル・ライブラリー (インテル® MKL)、インテル® データ・アナリティクス・アクセラレーション・ ライブラリー (インテル® DAAL) などにより、NumPy*、SciPy*、scikit-learn* を高速化できます。
- 最新のベクトル命令およびマルチスレッド命令を使用できます。Numba と Cython を組み合わせることで、並行処理やベクトル化効率を向上できます。
インテル® DAAL
インテル® データ・アナリティクス・アクセラレーション・ライブラリー (インテル® DAAL) は、データ・サイエンティスト向けに設計されており、データ・アナリティクスを高速化し、予測の効率を高めます。特に、膨大なデータを扱うアプリケーションでは、ベクトル化やマルチスレッド化を最大限に活用できるほか、インテル® Xeon® スケーラブル・プロセッサー・プラットフォーム上では、マシンラーニングの全体的なパフォーマンスを向上するほかのテクノロジーも活用できます。
インテル® DAALは、データ・サイエンティストやアナリストが、データの前処理から、データの特徴エンジニアリング、データモデリング、展開までを迅速に構築できるように設計された完全なエンドツーエンドのソフトウェア・ソリューションです。マシンラーニングやアナリティクスの開発に必要なさまざまなデータ・アナリティクスや、アルゴリズムに必要なハイパフォーマンスのビルディング・ブロックを提供します。現在、線形回帰、ロジスティック回帰、LASSO、AdaBoost、ベイズ分類器、サポート・ベクトル・マシン、K 近傍法、K 平均法クラスタリング、DBSCAN クラスタリング、各種決定木、ランダムフォレスト、勾配ブースティング、その他の古典的マシンラーニング・アルゴリズムをサポートしています。これらのアルゴリズムは、インテル® プロセッサーで高いパフォーマンスを発揮できるように高度に最適化されています。例えば、ビッグデータ・アナリティクス技術とサービスを提供する大手企業は、これらのリソースを利用して、データマイニング・アルゴリズムのパフォーマンスを数倍向上しています。
インテル・ベースの環境で、開発者がマシンラーニング・アプリケーションでインテル® DAAL を簡単に使用できるように、インテルはプロジェクト全体を https://github.com/intel/daal (英語) でオープンソース化しており、さまざまなビッグデータのシナリオに対応したフルメモリー、ストリーミング、分散アルゴリズムのサポートを提供しています。例えば、DAAL Kmeans は Spark* と組み合わせることで、Spark* クラスター上でマルチノード・クラスタリングを実行できます。さらに、インテル® DAAL は C++、Java*、Python* 向けのインターフェイスを提供しています。
DAAL4py
Python* で最も広く使用されている scikit-learn* のサポートを強化するため、インテル® DAAL は非常にシンプルな Python* インターフェイスである DAAL4py を提供しています。詳細は、オープンソースのウェブサイト https://github.com/IntelPython/daal4py (英語) を参照してください。DAAL4py は scikit-learn* とシームレスに使用でき、マシンラーニング・アルゴリズムを基盤となる層で高速化します。
開発者は scikit-learn* のソースコードを修正することなく、自動ベクトル化とマルチスレッド化の利点が得られます。DAAL4py は現在、scikit-learn* の以下のアルゴリズムに対応しています。
- Sklearn Linear Regression (線形回帰)、Sklearn Ridge Regression (リッジ回帰)、ロジック回帰
- PCA
- K 平均法
- pairwise_distance
- SVC (SVM 分類)
インテル® ディストリビューションの Python* とインテル® DAAL のインストール
インテル® ディストリビューションの Python* をダウンロードしてインストールする場合 (インテル® DAAL は同梱されています) (英語)
インテル® DAL デベロッパー・ガイド (英語)
インテル® DAAL の使用
インテル® DAAL を使用して scikit-learn* を高速化する方法は 2 つあります。
方法 1: コマンドラインを使用します。
# python -m daal4py <your-scikit-learn-script>
方法 2: ソースコードに追加します。
import daal4py.sklearn
daal4py.sklearn.patch_sklearn('kmeans')
参考文献
[1] Open source of Faiss project: https://github.com/facebookresearch/faiss (英語)関連情報
インテル® AVX-512 に関する情報: https://colfaxresearch.com/skl-avx512/ (英語)
インテル® Optimized AI Frameworks: https://www.intel.com/content/www/us/en/developer/tools/frameworks/overview.html (英語)
インテル® ディストリビューションの OpenVINO™ ツールキット: https://docs.openvino.ai (英語)
インテル® Analytics Zoo: https://github.com/intel-analytics/analytics-zoo (英語)
オープンソースの HNSWLib プロジェクト: https://github.com/nmslib/hnswlib (英語)
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
