
この記事は、インテル® AI Blog に公開されている「The Difference Between Artificial Intelligence, Machine Learning and Deep Learning」の日本語参考訳です。
この記事の PDF 版はこちらからご利用になれます。
インテルで人工知能 (AI) 戦略の責任者を務めている著者は、この急速に進歩するテクノロジーの基本的な背景について尋ねられることがよくあると言います。この度、皆さんに AI の基本情報を提供するため、「AI 101」シリーズを開始することになりました。シリーズ最初の記事では、AI、マシンラーニング、およびディープラーニングの関係性と、現在のディープラーニングの爆発的な普及を後押しする主な要因を説明します。
AI とは、機械が高度な人間の能力を模倣することを可能にする幅広いシステムを指します。AI の使用例はあらゆる業界に存在し、現在最も普及しているものには、以下のようなものがあります (図 1)。
- 画像認識 – 例: Facebook の写真の自動タグ付け機能
- 動画分類 – 例: 防犯カメラによる人物の自動判別
- 音声テキスト化 – 例: スマートフォンの音声テキスト入力
- 自然言語処理 – 例: Google Translate*
- 表形式および時系列のデータ・アプリケーション – 例: パーソナライズ広告、メールのスパムフィルター、お勧め映画

図 1. AI の一般的な使用例
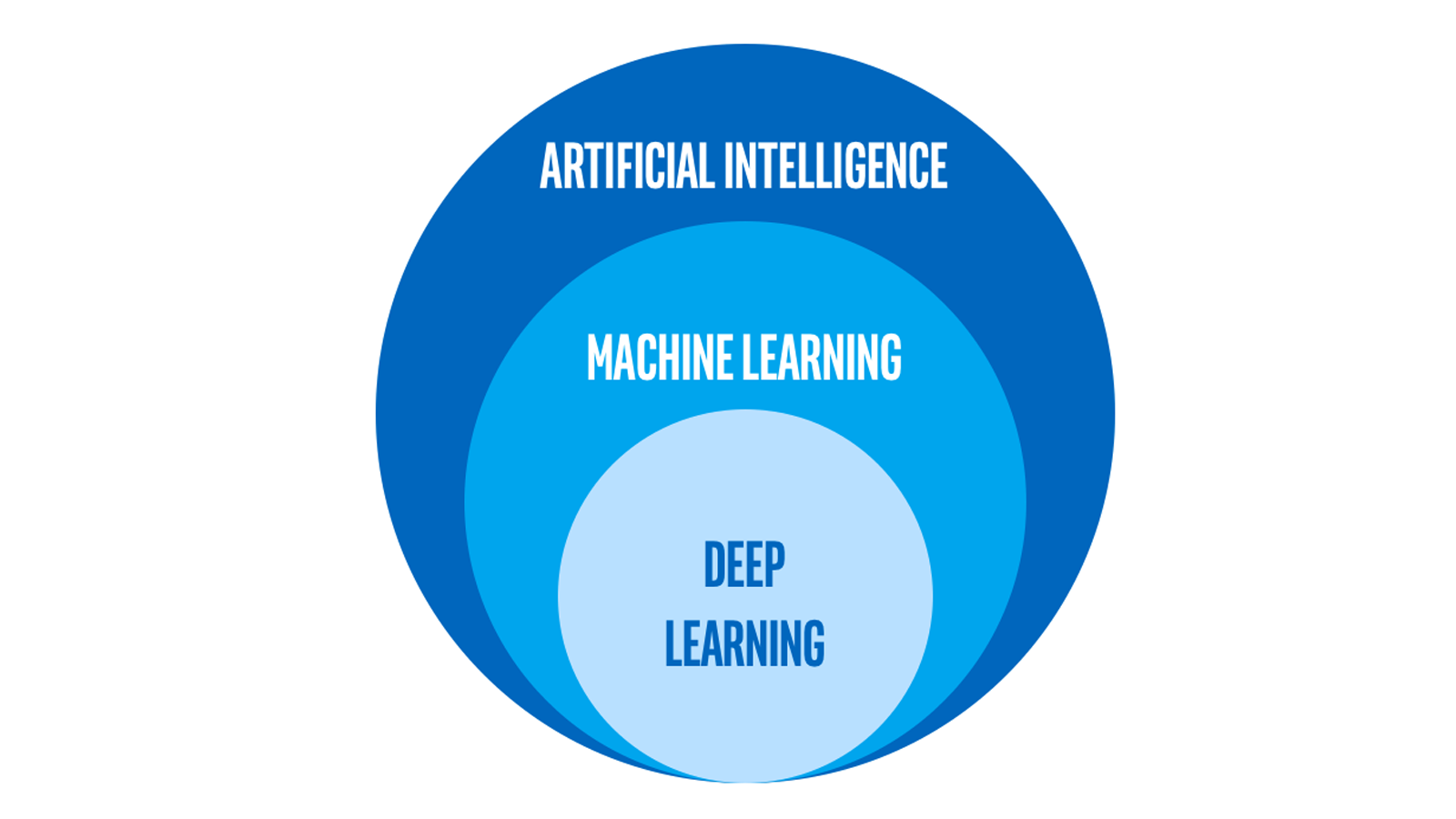
AI は、さまざまな方法で実現できます。例えば、一連の if/then 文とその他のルールを使用して、症状から病気を診断する「エキスパート・システム」を作成できます。マシンラーニングでは、マシンが既知の例のコレクションを分析することで、これらのルールを自動的に「学習」します。マシンラーニングは、現在 AI を実現する最も一般的な方法であり、ディープラーニングは、特殊なタイプのマシンラーニングです。図 2 は、この AI、マシンラーニング、およびディープラーニングの関係性を示しています。
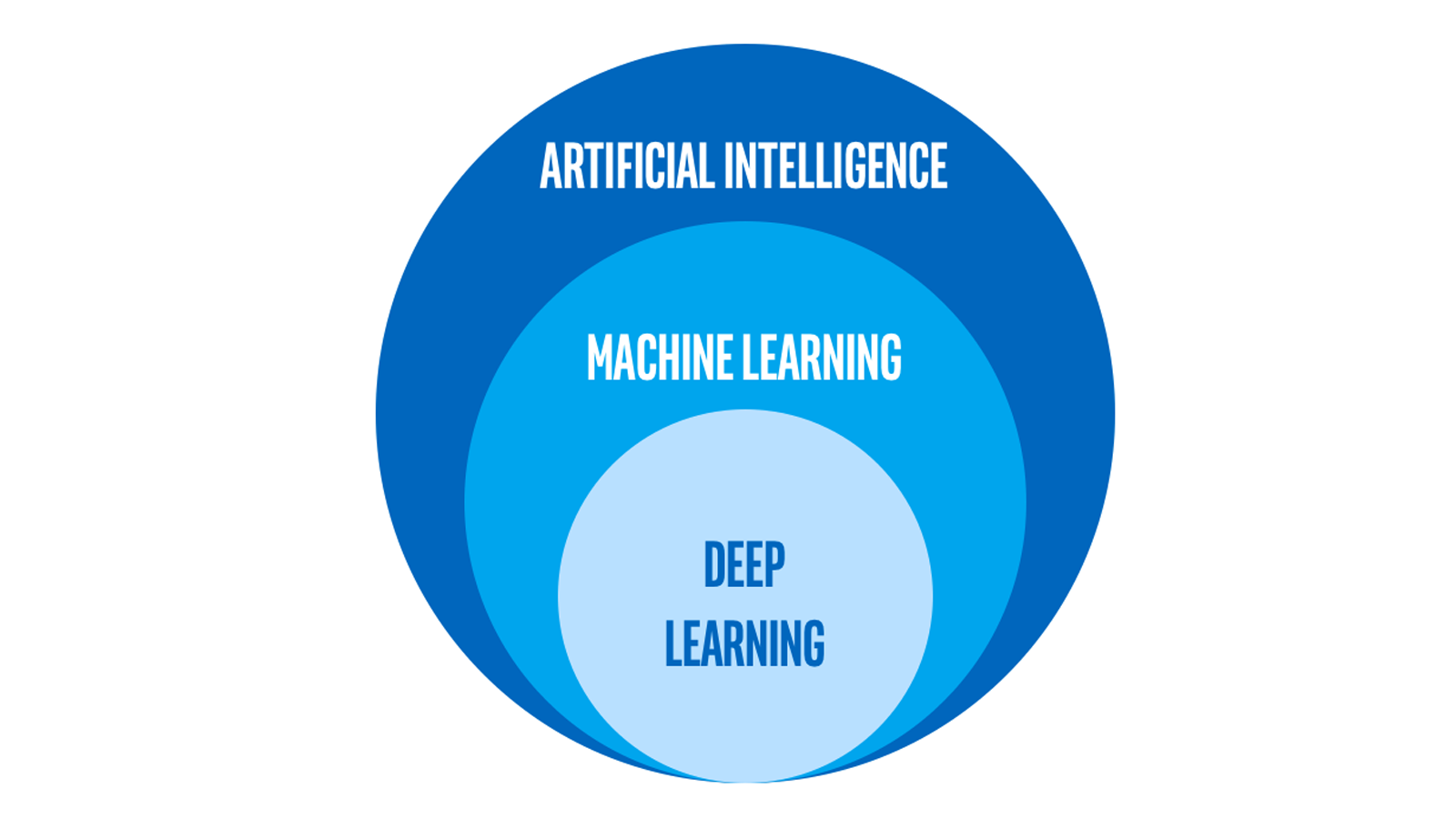
図 2. AI とマシンラーニングとディープラーニングの関係性
マシンラーニングとディープラーニング
マシンラーニングとディープラーニングの違いについて、もう少し詳しく見てみましょう。マシンラーニングは、既存のデータからのパラメーターを使用して、類似する新しいデータの結果を予測する統計的手法の一種です。例えば、ある都市の住宅販売履歴から、マシンラーニングを使用して、その都市の別の住宅の販売価格を予測するモデルを作成できます。
伝統的に、マシンラーニングは、データセット内で重要と考えられる「特徴」セットに依存します。住宅販売の例では、住宅の価格に関連する特徴として、寝室の数、敷地面積、学区の標準テストのスコアなどが挙げられます。マシンラーニングに特徴を組み込むプロセスは、「特徴エンジニアリング」と呼ばれ、これには対象分野 (ここでは住宅不動産) についての深い専門知識とかなりの労力を必要とします。
ディープラーニングは、近年注目を集めているマシンラーニングの一種です。ディープラーニングでは、アルゴリズムに重要な特徴を知らせる必要はありません。代わりに、「ニューラル・ネットワーク」と呼ばれるものを使用して、データから特徴を検出できます。「ニューラル・ネットワーク」という名前は、(脳のニューロンのように) 入力の組み合わせがしきい値を超えると「放出」される人工ニューロンと呼ばれる数学的物体に発想を得ています。人工ニューロンは、脳のニューロンと同様に、層状に配置されています。ディープラーニングは、複数の層の人工ニューロンを持つ「ディープ (深い)」ニューラル・ネットワーク (DNN) を使用します。
DNN 中の人工ニューロンは互いに結合されており、2 つのニューロン間の結合強度は「重み」と呼ばれる数値で表現されます。この重みを決定するプロセスは「トレーニング」と呼ばれます。DNN のトレーニングについては、今後の記事で取り上げます。
例: 顔認識
マシンラーニングとディープラーニングの違いをよく理解するため、顔の画像から人物を識別するように設計されたシステムについて考えます (図 3)。
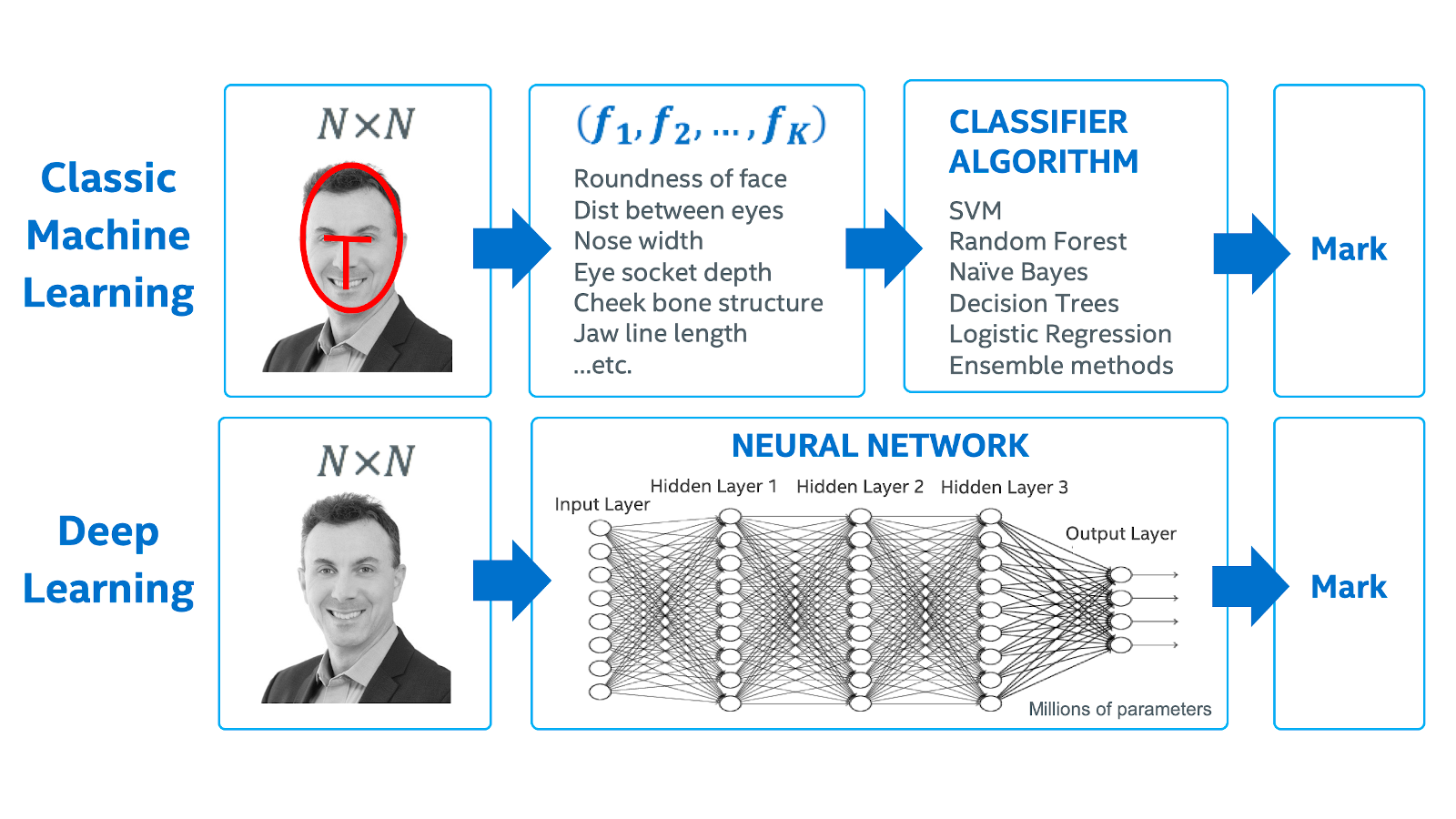
図 3. 顔認証におけるマシンラーニングとディープラーニングの比較
典型的なマシンラーニングでは、データ・サイエンティストは、顔の丸みや両目の間隔など、与えられた顔を一意に表す特徴のセットを識別する必要があります。次に、マシンラーニングの分類アルゴリズムを適用して、与えられた特徴のパターンを一意の人物に関連付けることを学習します。
このアプローチの難しさは、多くの場合、特定の問題に対して有用な特徴が明確でないことです。また、重要な特徴が分かっていても、それを計算するのは困難な場合があります。例えば、目と目の間隔を計算するには、まず画像内の目の位置を特定する必要がありますが、それ自体複雑な処理です。髪型などの特徴を組み込むことを想像してみてください。滑らかな髪、分け目のある髪、ツンツンした髪がどのように見えるかということは分かっていますが、アルゴリズムで処理するには、どのように定義して測定したら良いでしょうか? 特徴エンジニアリングは、非常に時間のかかる作業であり、特徴値の計算が困難な場合、最終的に結果の精度が制限されます。
ディープラーニングを利用することで、特徴エンジニアリングを完全に回避できます。十分な量の「ラベル付けされたデータ」 (既知の顔の画像) と適切なチューニングにより、ディープラーニング・モデルはデータから最も関連性の高い特徴を識別します。
ディープラーニングは、「最適な特徴を作成するには?」から「モデルが最適な特徴を見つけられるようにするには?」への発想の転換を表しています。
ディープラーニング: なぜ今注目されているのか?
多くの基本的なディープラーニングの概念は、1940 年代から存在していましたが、いくつかの要因が最近のディープラーニングの進化に弾みをつけました (図 4)。
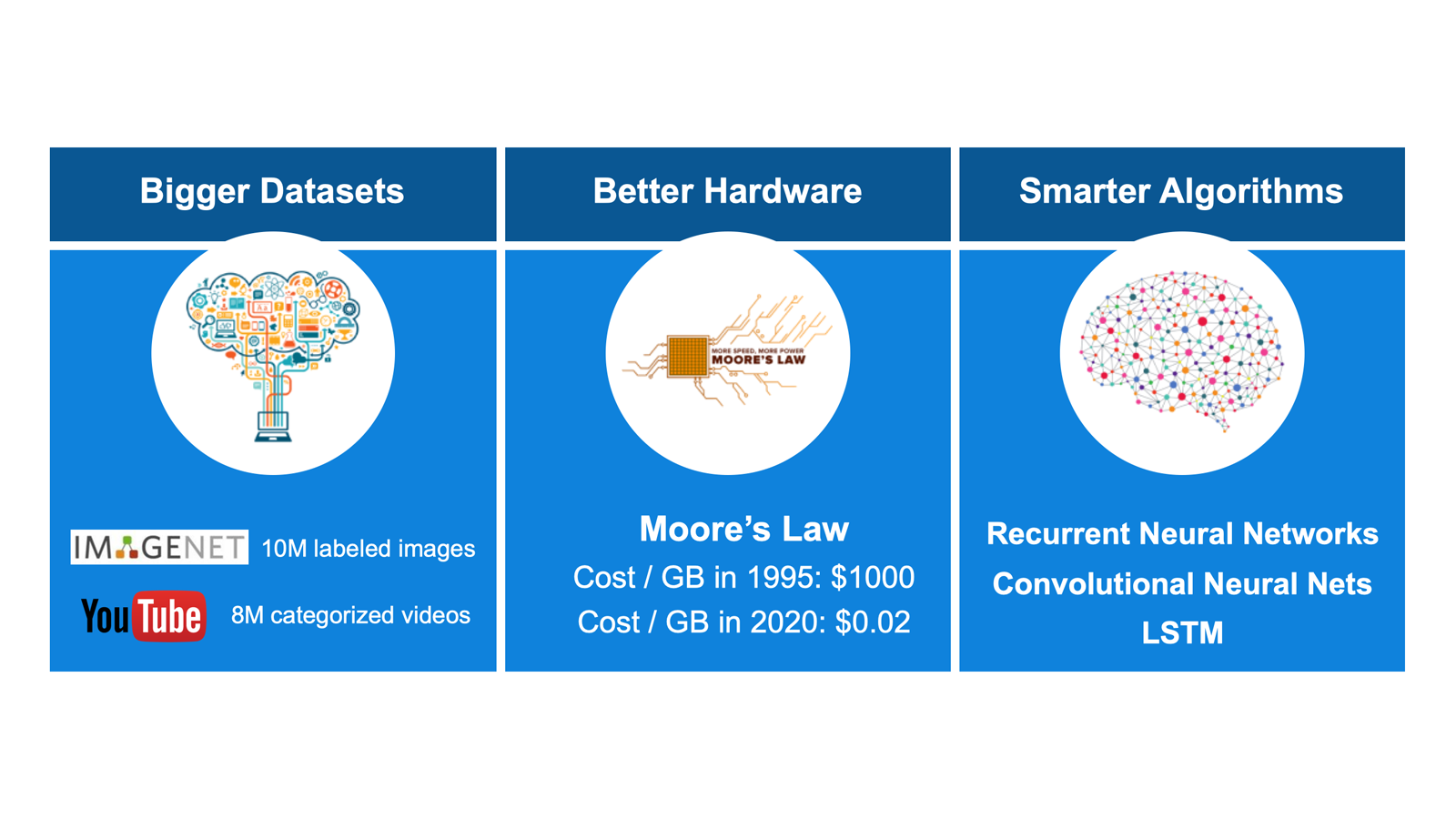
図 4. 最近のディープラーニングの進化を推進する要因
次の要因が含まれます。
- より大きなデータセット – 利用可能なデータが劇的に増加し、正確なモデルの開発に必要な十分な入力が得られるようになりました。例えば、ImageNet は 1000 万枚の手動でラベル付けされた画像からなるオープン・データセットで、Alphabet は 800 万本のカテゴリーラベル付きの YouTube* ビデオをリリースしています。
- ハードウェアの進化 – 1 つのディープラーニング・モデルのトレーニングには、約 10 EXAFLOPS の計算量 (1018 または 100 京の浮動小数点演算) が必要です。ムーアの法則により、このタスクをコスト的にも時間的にも効率良く実行できるハードウェアが存在するようになりました。
- より洗練されたアルゴリズム – Google や Amazon などのクラウド・サービス・プロバイダーは、AI の価値に気付き、その分野の基礎研究に多額の投資を行っています。新しいアルゴリズムが次々と公開され、その多くは無料で利用できます。
その結果、AI 製品やスタートアップが爆発的に増え、画像認識や音声認識の精度が飛躍的に向上しました。ディープラーニングのお陰で、機械は人間よりも優れた精度を日常的に発揮するようになりました (図 5)。
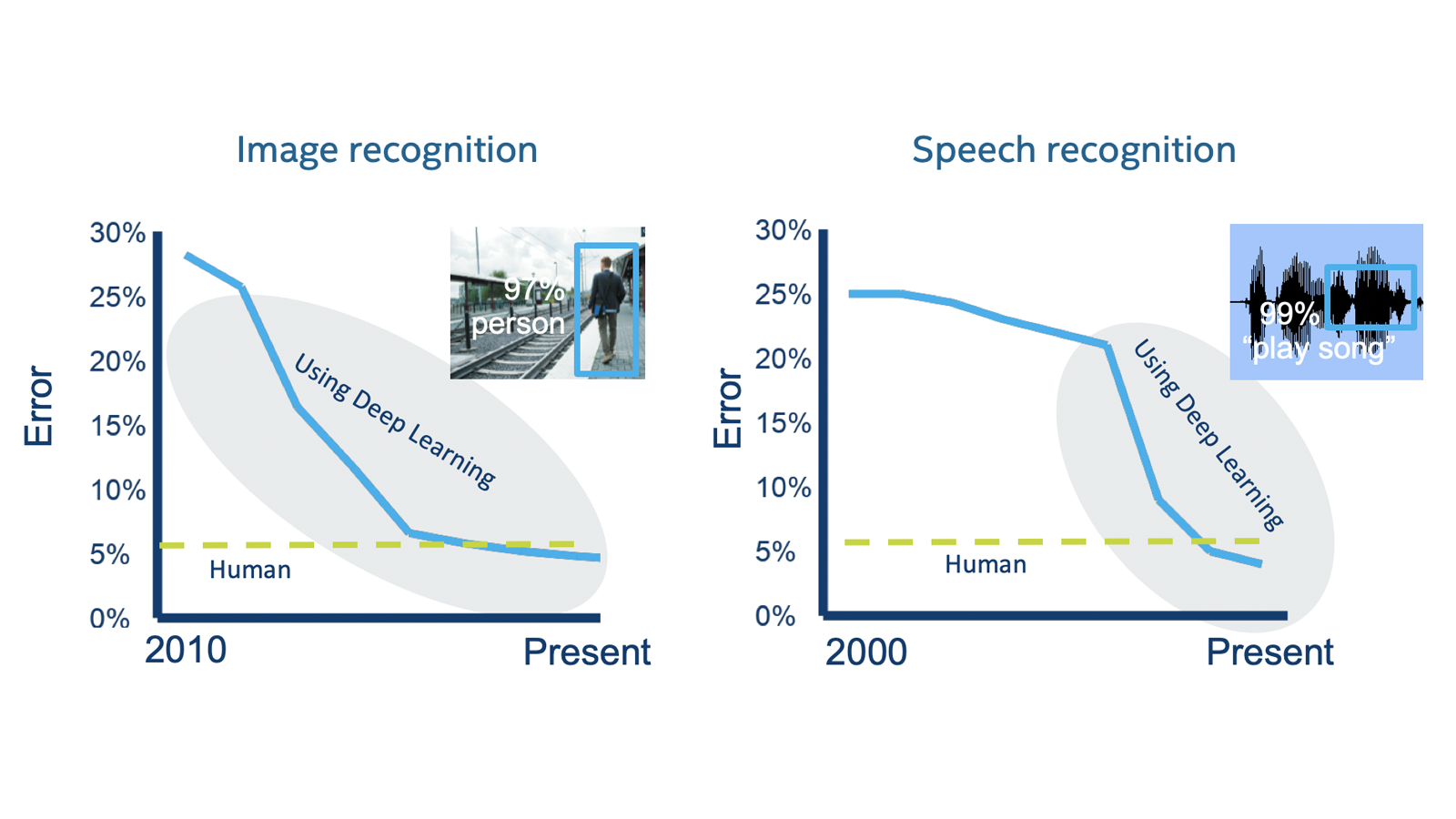
図 5. 特定のアプリケーションでは機械が人間と同等またはそれ以上の精度を達成
次の「AI 101」記事では、ディープラーニングのトレーニングと推論の違いを説明します。AI、ディープラーニング、およびマシンラーニングの最新情報は、@IntelAI (英語) と @IntelAIResearch (英語) をフォローしてください。
法務上の注意書き
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。
絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
実際の費用と結果は異なる場合があります。
© Intel Corporation. Intel、インテル、Intel ロゴは、アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
