
この記事は、インテル® AI Blog に公開されている「Accelerating Deep Learning Training and Inference with System Level Optimizations」(https://www.intel.ai/accelerating-deep-learning-training-inference-system-level-optimizations/) の日本語参考訳です。
インテル® Neon™ Deep Learning Framework は、業界最先端のパフォーマンスを提供するため Nervana Systems によって開発されました。2018 年の時点で、インテル® Neon™ Deep Learning Framework のサポートは終了しています。代わりに、ここで紹介するインテルにより最適化されているフレームワークの使用を推奨します。
深い畳み込みニューラル・ネットワーク (CNN) のトレーニングは大変な作業です。ResNet-50、GoogLeNet-v1、Inception-v3 などの一般的な CNN の例では、数十万回もの反復ごとに数百回もの計算集約型関数を実行する必要があります。
一般的なディープラーニング・フレームワークに対するインテルの最適化は、プロセッサー・レベルのパフォーマンスを大幅に向上しますが、さらなるパフォーマンスの向上が可能です。特にシステムレベルの最適化は、ディープラーニングやハイパフォーマンス・コンピューティング (HPC) アプリケーションで使用されるインテル® Xeon® プロセッサーおよびインテル® Xeon Phi™ プロセッサー上で CNN ワークロードのパフォーマンスを向上できます。
これらの最適化と一般的な手法 (BKM) については、インテル コーポレーション AI 製品グループの Deepthi Karkada、Vamsi Sripathi、Dr. Kushal Datta、Ananth Sankaranarayanan 著のホワイトペーパー「インテル® Xeon プロセッサーおよびインテル® Xeon Phi™ プロセッサー・ベースのプラットフォーム上でディープラーニングのトレーニングと推論のパフォーマンスを向上する」 (https://software.intel.com/en-us/articles/boosting-deep-learning-training-inference-performance-on-xeon-and-xeon-phi) で取り上げています。ホワイトペーパーでは、オープンソースの TensorFlow* (英語) と Caffe* 向けの現在のソフトウェアの最適化と比較して、フレームワークのコードを変更することなくディープラーニングのトレーニングと推論のパフォーマンスを最大 2 倍向上できることを示しています。
ディープラーニングのトレーニングと推論のパフォーマンスを最大化
TensorFlow* や Caffe* などのディープラーニング・フレームワークは、CNN の実行中に CPU コアを最大限に活用していません。これは、ユーザー制御可能なパラメーターとして、マルチソケットのインテル® Xeon® プロセッサー・ベースのプラットフォームで最適なパフォーマンスを達成するのに必要な NUMA 構成に関するマイクロアーキテクチャーの情報を提供していないためです。CPU ソケットと NUMA 構成に関する情報がないと、(スレッドプールのように) 単純なスレッド・アフィニティーは最適なパフォーマンスにつながりません。CPU ベースのプラットフォーム上で CNN ワークロードに対して最高のパフォーマンスを達成するには、システムレベルの最適化が必要です。
インテル® Xeon® プロセッサー・ベースのシステムでディープラーニングのトレーニング向けにコアの使用率を最適化する
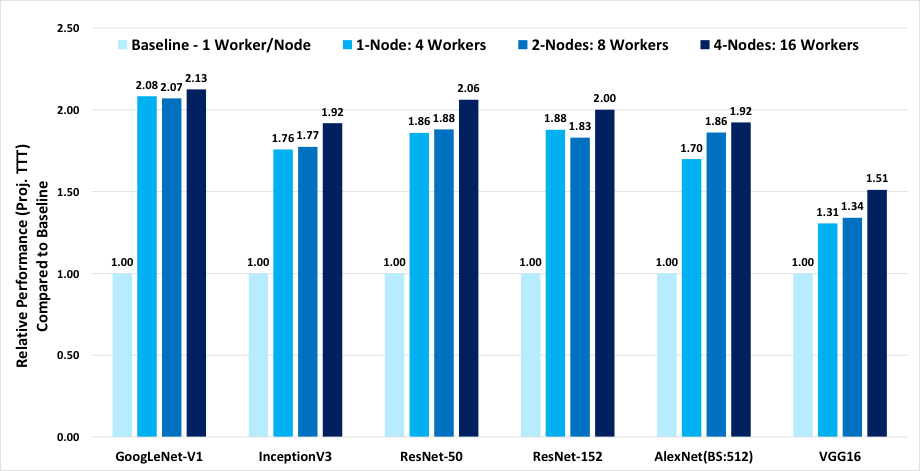
BKM で説明されているように、プラットフォーム上のソケットとコアをコンピューティング・デバイスとして分割し、それぞれで個別のディープラーニングのトレーニングのインスタンスを同時に実行できます。これらのインスタンスは同期により連携して動作し、各インスタンスは入力データのローカルバッチを実行します。各インスタンスは、コア・アフィニティー設定を使用して、システムの合計コアのサブセットにプロセスがバインドされます。コア・アフィニティーとメモリーの局所性の最適化により、シングルノード、4 ワーカー/ノードで、TensorFlow* 1.4.0 を使用する現在の最適化と比較して、パフォーマンスが最大 2 倍向上します。図 1 は、6 つのディープラーニング・ベンチマーク・トポロジーでこれらの最適化を使用することで得られたトレーニング・パフォーマンスの結果です。
インテル® Xeon® Platinum 8168 プロセッサー: TensorFlow* マルチノード & ソケットごとに複数のワーカー
トレーニング: TensorFlow* 1.4、BS=64、画像データセット、grpc/10GB イーサネット、
各ノードにパラメーター・サーバーがある場合
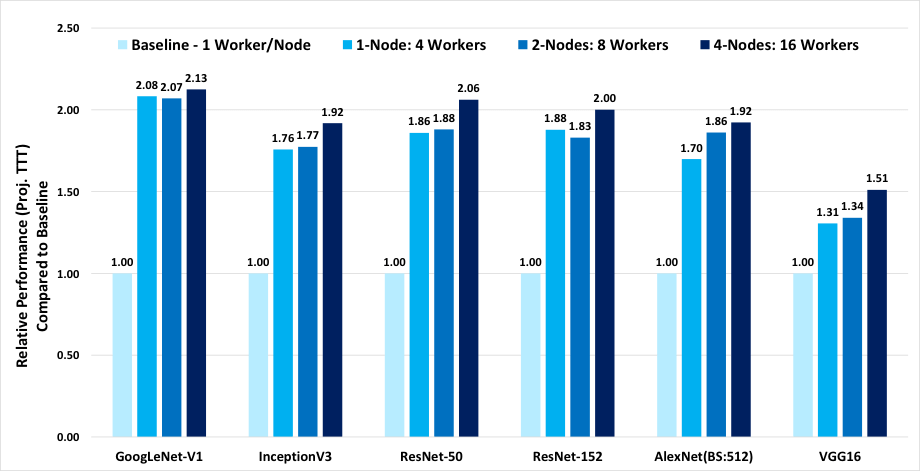
図 1: ノードごとに 1 ワーカーのベースラインと比較した、ノードごとに 4 ワーカーを使用して、アフィニティーによりコアとメモリーの局所性を最適化した TensorFlow* 1.4 トレーニング・パフォーマンス (予想トレーニング時間 (TTT)) の向上プラットフォーム構成: 2 ソケットのインテル® Xeon® Platinum 8168 プロセッサー @ 2.70GHz (24 コア)、インテル® ハイパースレッディング・テクノロジー有効、インテル® ターボ・ブースト・テクノロジー無効、intel_pstate ドライバーによりスケーリング・ガバナーは “performance” に設定、192GB DDR4-2666 ECC RAM。CentOS* Linux* 7.3.1611 (Core)、Linux* カーネル 3.10.0-514.10.2.el7.x86_64。SSD: インテル® SSD DC S3700 シリーズ。10Gbit イーサネットで接続された複数のノード。Tensorflow* 1.4.0、GCC 6.2.0、ディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN)。トレーニングは SSD の画像データで測定。出典: 2017 年 12 月に実施したインテル社内でのテスト。
インテル® Xeon® プロセッサー・ベースのシステムでディープラーニングの推論向けにコアの使用率を最適化する
同じアプローチをディープラーニングの推論にも適用できます。独立した複数のディープラーニング推論フレームワークのインスタンスを作成し、各インスタンスのアフィニティーをシングルまたはマルチソケット・システムの分割したコアのセットとメモリーの局所性に設定します。システムレベルの最適化により、ディープラーニングの推論パフォーマンスは TensorFlow* 1.4.0 を使用する最適化と比較して最大 2.7 倍向上します。図 2 は、5 つのディープラーニング・ベンチマーク・トポロジーでこれらのシステムレベルの最適化を使用することで得られた推論パフォーマンスの向上を示しています。
インテル® Xeon® Platinum 8168 プロセッサー: TensorFlow* シングル & マルチノード・ワーカーによる推論
TensorFlow* 1.4、画像データセット、forward_only
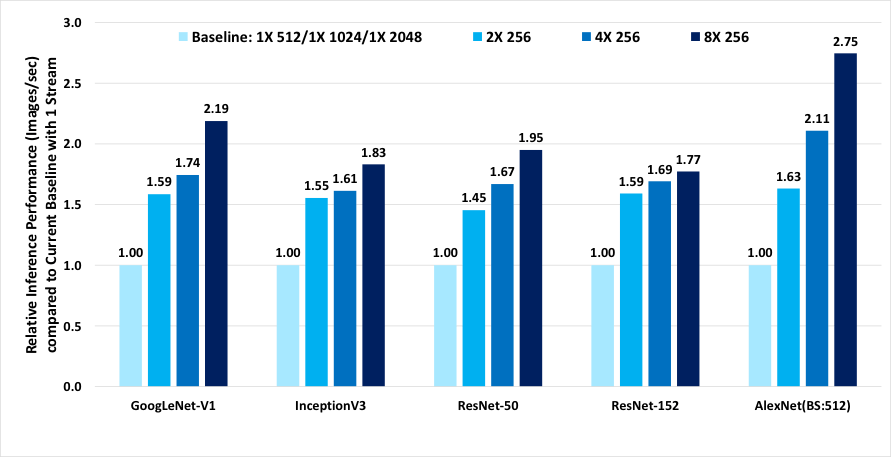
図 2. 等価なバッチサイズで 1 ストリームを使用するベースラインと比較した、2、4、8 ストリームを同時に使用し、アフィニティーによりコアとメモリーの局所性が最適化された TensorFlow* 推論パフォーマンス (画像/秒) の向上。プラットフォーム構成: 2 ソケットのインテル® Xeon® Platinum 8168 プロセッサー @ 2.70GHz (24 コア)、インテル® ハイパースレッディング・テクノロジー有効、インテル® ターボ・ブースト・テクノロジー無効、intel_pstate ドライバーによりスケーリング・ガバナーは “performance” に設定、192GB DDR4-2666 ECC RAM。CentOS* Linux* 7.3.1611 (Core)、Linux* カーネル 3.10.0-514.10.2.el7.x86_64。SSD: インテル® SSD DC S3700 シリーズ。Tensorflow* 1.4.0、GCC 6.2.0、ディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN)。推論は –forward_only で測定。SSD の画像データを使用。出典: 2017 年 12 月に実施したインテル社内でのテスト。
まとめ
ここで紹介したシステムレベルの最適化とそのサンプルコードについては、「インテル® Xeon プロセッサーおよびインテル® Xeon Phi™ プロセッサー・ベースのプラットフォーム上でディープラーニングのトレーニングと推論のパフォーマンスを向上する」 (https://software.intel.com/en-us/articles/boosting-deep-learning-training-inference-performance-on-xeon-and-xeon-phi) を参照してください。
インテルは、ビッグデータ解析、シミュレーション、モデリングなどのワークロードに使用されている多用途のインテル® アーキテクチャー・ベースのシステムで優れたディープラーニング・パフォーマンスを提供します。皆さんが AI の可能性を最大限に引き出せるように、インテルは今後も AI ハードウェアおよびソフトウェア・ソリューション・ポートフォリオの改善に取り組んでいきます。
法務上の注意書きと最適化に関する注意事項
ベンチマーク結果は、「Spectre」および「Meltdown」と呼ばれる脆弱性への対処を目的とした最新のソフトウェア・パッチおよびファームウェア・アップデートの適用前に取得されたものです。パッチやアップデートを適用したデバイスやシステムでは同様の結果が得られないことがあります。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。さらに詳しい情報をお知りになりたい場合は、https://www.intel.com/benchmarks (英語) を参照してください。
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。実際の性能はシステム構成によって異なります。絶対的なセキュリティーを提供できるコンピューター・システムはありません。詳細については、各システムメーカーまたは販売店にお問い合わせいただくか、http://www.intel.co.jp/ を参照してください。
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。注意事項の改訂 #20110804
インテル® プロセッサーは SKU が同じであっても、製造工程における自然なばらつきにより、周波数や出力が異なる場合があります。
© 2019 Intel Corporation. Intel、インテル、Intel ロゴ、Xeon、Intel Xeon Phi は、アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
