
この記事は、インテル® デベロッパー・ゾーンに公開されている「Accelerate INT8 Inference Performance for Recommender Systems with Intel® Deep Learning Boost (Intel® DL Boost)」(https://software.intel.com/en-us/articles/accelerate-int8-inference-performance-for-recommender-systems-with-intel-deep-learning) の日本語参考訳です。
はじめに
オンライン情報の大幅な増加に伴い、推奨システムは過剰な選択肢の問題に取り組むため不可欠になりました。ワイド & ディープラーニング推奨システム (Cheng 2016 (英語)) は、ワイド線形モデルを使用する特徴の相互作用の利点とディープ・ニューラル・ネットワークの一般化を組み合わせるディープラーニング (DL) トポロジーの一例です。
従来のディープラーニング・ソリューションとアプリケーションは、トレーニングと推論に 32 ビットの浮動小数点精度 (FP32) を使用しています。精度の低下を最小限に抑える (Norman 2017 (英語)、ログインが必要) 8 ビット (INT8) の乗数 (32 ビットに累積) を使用するディープラーニングの推論は、さまざまな畳み込みニューラル・ネットワーク (CNN) モデルで一般的ですが (Gupta 2015 (英語)、Lin 2016 (英語)、Gong 2018 (英語))、推奨システムではこれまで結果を利用できませんでした。
第 2 世代インテル® Xeon® スケーラブル・プロセッサーには、ベクトル・ニューラル・ネットワーク命令 (VNNI) を使用して低い精度のパフォーマンスを向上する、インテル® ディープラーニング・ブースト (インテル® DL ブースト)と呼ばれる新しい組込みアクセラレーション命令が含まれます。インテル® DL ブーストは、FP32 と比較して最大 4 倍の計算を処理でき、スループットを向上し、レイテンシーを軽減します。詳細は、「低い数値精度でのディープラーニングのトレーニングと推論」を参照してください。INT8 精度の推論は、計算パフォーマンスを向上し、メモリー帯域幅の使用を軽減し、キャッシュの局所性を高め、消費電力を軽減できます。
インテル® DL ブースト・テクノロジーを使用することで、ワイド & ディープラーニング推奨システムにおいて、精度の低下を最小限に抑え (0.5% 未満)、INT8 精度で FP32 精度の 200% のパフォーマンス・ゲインが得られました1。このホワイトペーパーの目的は、インテル® DL ブーストとディープ・ニューラル・ネットワーク・ライブラリー (DNNL) (英語) (旧称: ディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN) (英語)) を使用して INT8 推論パフォーマンスを向上するために使用した量子化手法と最適化手法をさまざまなコミュニティーの方々に紹介することです。
FP32 モデルのトレーニングと最適化
トレーニング
ここでは、Criteo* AI Labs の Kaggle* Display Advertising Challenge Dataset を使用します。トレーニング・データセットは、ユーザーによる広告のクリック情報を含む 7 日間の Criteo のトラフィックの一部で構成されています。データの各行は、Criteo が配信するディスプレイ広告のユーザーによるクリックに対応しています。整数で表現される数値特徴が 13 列、16 進数値で表現されるカテゴリー特徴が 26 列あります。ラベル列は広告がクリックされたかどうかを示します。モデルのトレーニングには合計 8,000,000 行が使用されます。
数値特徴は正規化後 ([0,1] 範囲) 直接ディープ部分に供給され、カテゴリー特徴は最初にハッシュされ、埋め込みのためワイド部分とディープ部分の両方に供給されます。
各カテゴリー特徴のハッシュには、長さ 1000 の one-hot ベクトルが使用されます。ワイド部分は線形変換を効率良く使用して特徴間の疎な相互作用を学習し、ディープ部分はフィードフォワード・ニューラル・ネットワークと埋め込み層や複数の隠れ層を使用して特徴の組み合わせを一般化します。
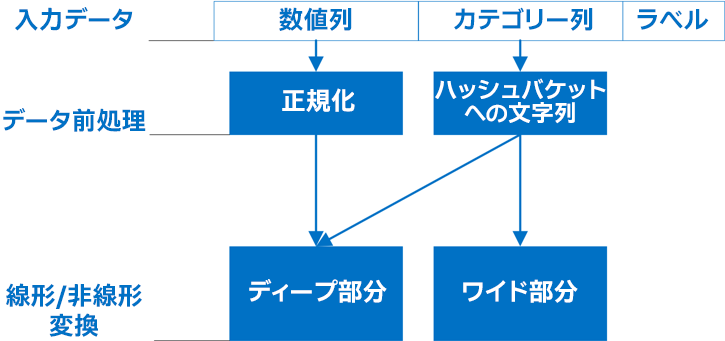
図 1. 数値特徴は一般化後ディープ部分に直接供給され、カテゴリー特徴は最初にハッシュされ (String To Hash Bucket)、埋め込みのためワイド部分とディープ部分の両方に供給されます。
各 26 カテゴリー特徴は、最初にハッシュ・バケット・サイズ 1000 の長さ 1000 の one-hot ベクトルに変換されます。そして、これらのスパースベクトルに対して埋め込みが行われ、長さ 32 の密ベクトルが取得されます。13 の数値特徴は直接連結されます。多層パーセプトロン (MLP) の隠れ層は、それぞれサイズが 1024、512、256 になるように選択されます。
ワイド & ディープ推奨システムは、メモリー帯域幅を大幅に消費する操作 (埋め込み) によって特徴付けられます。インテル® DL ブーストは積和演算 (FMA) の高速化に使用されるため、インテル® DL ブーストによる全体的なパフォーマンス向上は、非 FMA グラフノードでの実行時間 (OP) の最小化に依存します。インテル® DL ブーストによる推論の高速化の利点を最大限に得るには、最初に高い精度 (FP32) のワイド & ディープグラフを最適化します。
トレーニング済みモデル内の OP は、使用されるフレームワークによって異なる場合があります。TensorFlow* Estimator は、ワイド & ディープモデルを生成する DNNLinearCombinedClassifier と呼ばれる高水準 API を提供します。Apache* MXNet (英語) (Chen 2015 (英語)) では、このモデルの構築に必要な OP を手動で追加する必要があります。ここでは、TensorFlow* フレームワークと MXNet フレームワークで既存のツールを使用して事前トレーニング済みモデルを最適化するプロセスを説明します。
最適化
TensorFlow* でトレーニング済みのモデルは、次のように最適化されます。
- 推論に必要ないトレーニング OP は、モデルを変更するためのツール群を提供するグラフ変換ツール (英語) によってプルーニングされます。ここでは、strip_unused_nodes、remove_nodes、および remove_attribute を使用してトレーニング OP をプルーニングします。
- カテゴリー列は、冗長および不要な OP を削除して最適化します。図 2 の左部分には、グラフの最適化されていない部分が含まれています。これらは次のように最適化されます。
- 必要な次元の空でない入力文字列の取得に使用される Expand Dimension、GatherNd、NotEqual、および Where OP は、現在のデータセットで冗長なため削除されます。
- エラーチェックと処理 OP (NotEqual、GreaterEqual、SparseFillEmptyRows、Unique、など) および一意の値の計算と再構築 OP (Unique、SparseSegmentSum/Mean、StridedSlice、Pack、Tile、など) は、現在のデータセットに必要ないため削除されます。
- カテゴリー列と埋め込み OP は融合されます。図 2 の中央部分には未融合の GatherV2 OP が含まれています。これらは、次のように使用されます。
- ハッシュ・バケット・ルックアップに単一の文字列を使用するように 26 のカテゴリー列が融合されます。
- ディープ部分の GatherV2 OP を使用する 26 の埋め込み呼び出しとワイド部分の対応する 26 の呼び出しが 2 つの GatherNd に融合されます。
- カテゴリー列のハッシュ・バケット・ルックアップ文字列と数値列の正規化には個別のデータ前処理セッションが使用されます。
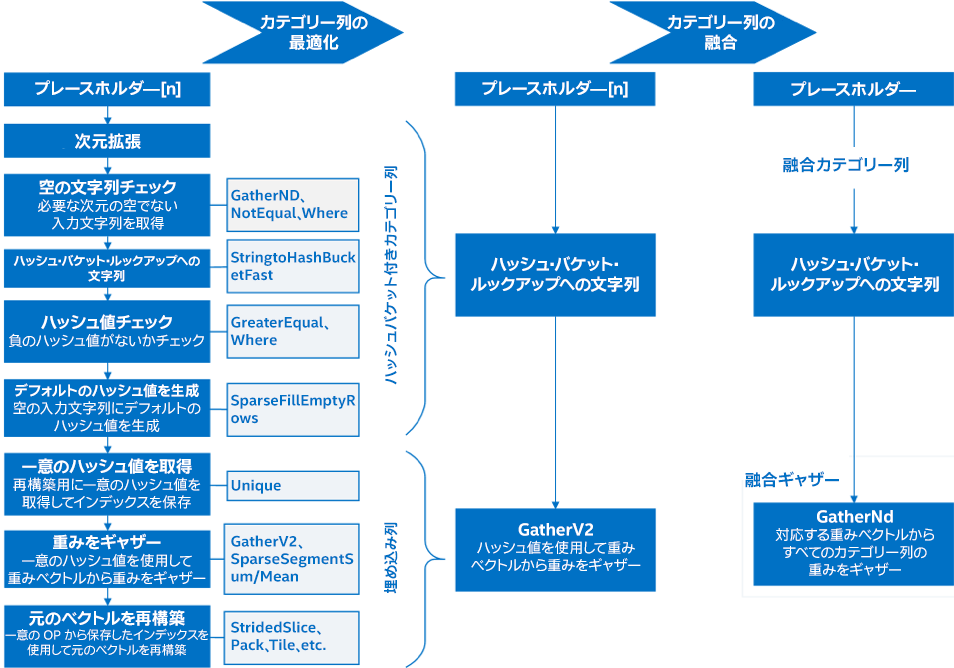
図 2. TensorFlow* での特徴列の最適化データセットに必要ない OP は最初に削除されます。次に、最適なパフォーマンスが得られるように、未融合の GatherV2 を組み合わせて融合したギャザーを形成します。
MXNet でトレーニング済みのモデルは、次のように最適化されています。
- ディープ部分の SparseEmbedding OP を使用する 26 の埋め込み呼び出しは、単一の ParallelEmbedding 呼び出しに融合されます。
- ワイド部分の線形変換には単一の Dot OP が使用されます。
- 入力特徴の分割に使用されるスライスや分割などのメモリー操作 OP が融合されます。
- カテゴリー列のハッシュ・バケット・ルックアップ文字列と数値列の正規化には個別のデータ前処理セッションが使用されます。
最適化後の FP32 モデルを図 3 に示します。
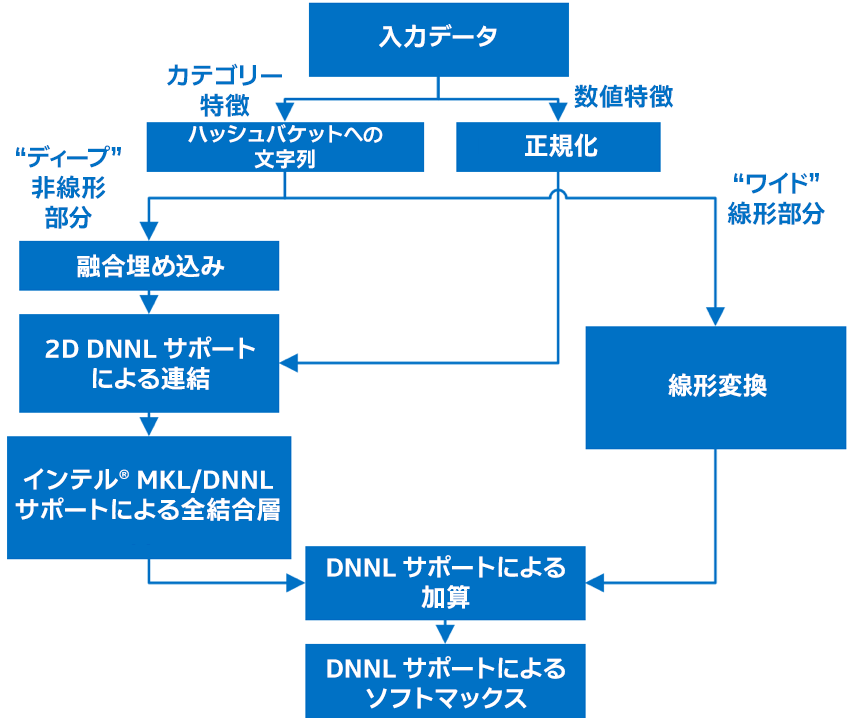
図 3. 最適化後の FP32 モデル。数値特徴は直接ディープ部分に供給され、カテゴリー特徴は最初にハッシュされ、埋め込みのためワイド部分とディープ部分の両方に供給されます。ディープ部分には計算負荷の高い全結合層が含まれ、ワイド部分には計算負荷がそれほど高くない線形変換 (ここではドット積) が含まれます。これらの部分からの出力は、ソフトマックス活性化層で処理され、最終出力が得られます。
今後の取り組みとして、より効率良くグラフを最適化できるように、既存のフレームワーク・ツールを拡張する予定です。
量子化
DNNL は、INT8 入力値と INT8 重み値を受け取り、行列乗算を実行して INT32 結果を出力する汎用行列乗算関数をサポートします。また、全結合層のバイアス、ReLU、再量子化、および逆量子化 OP を融合できます。ここでは、すべての全結合 (FC) 層は INT8 精度に量子化されます。
図 4 は、TensorFlow* フレームワークと MXNet フレームワークでの量子化プロセスです。FP32 モデルは最初に融合 INT8 モデルに変換されます。これには、重みを INT8 精度に変換して、FP32 OP を融合 INT8 OP に置き換える処理が含まれます。例えば、MatMul、BiasAdd、および ReLU は融合され、単一の量子化 OP が形成されます。テンソル統計データ (最小、最大、範囲) は、トレーニング・データセットのサブセットであるキャリブレーション・データセットを使用して収集されます。TensorFlow* では量子化されたモデルを使用してキャリブレーションが行われ、MXNet では FP32 モデルを使用して行われます。次に、再量子化 OP は、対応する層の量子化された全結合 OP と融合されます。図 5 に詳しい説明があります。
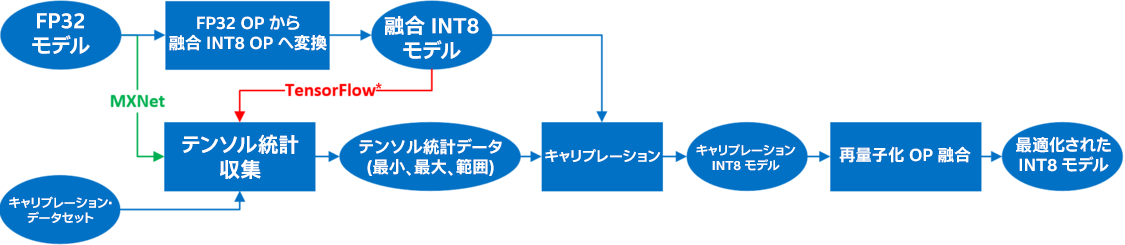
図 4. 量子化プロセスFP32 OP は融合され、INT8 OP に変換されます。TensorFlow* では量子化されたモデルを使用してキャリブレーションが行われ、MXNet では FP32 モデルを使用して行われます。
FC 層の量子化では、MatMul、BiasAdd、および ReLU で処理された最初の FC 層が、各層に対応する単一の融合された INT8 OP に変換されます。MatMul と BiasAdd OP で処理された最後の FC 層は別の INT8 OP に変換されます。FP32 精度の重みは量子化され (図中の QWeight)、FP32 OP (MatMul、Bias Add、ReLU) は単一の OP を形成するため融合された対応する量子化 OP に置き換えられます。図 5 では、このプロセスは量子化と融合 OP として示されています。次に、各 FC 層からの再量子化 OP が対応する層のほかの融合 INT8 OP と融合されます (図 5 の再量子化 OP 融合)。
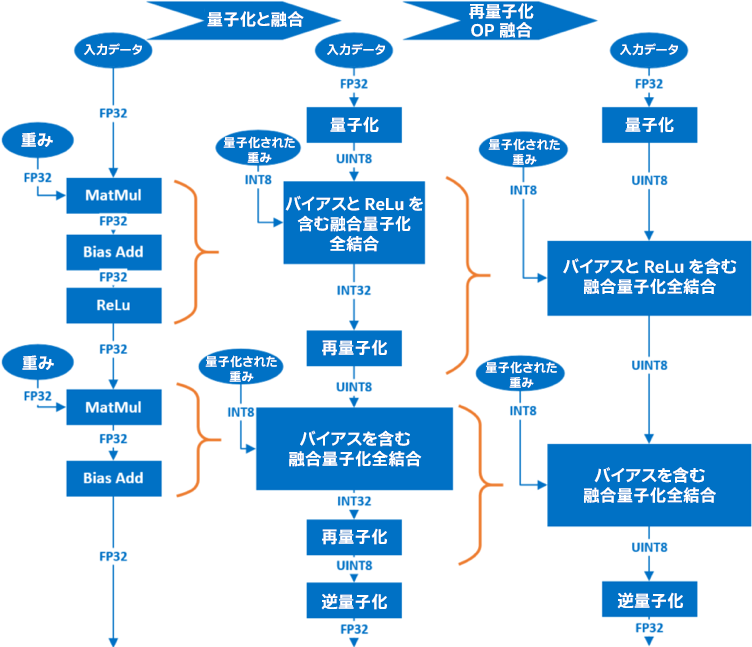
図 5. 全結合層の量子化と OP 融合。MatMul、BiasAdd、および ReLU OP 処理される最初の FC 層は、各層に対応する単一の融合 INT8 OP に変換されます。MatMul OP および BiasAdd OP 処理される最後の FC 層は、別の融合 INT8 OP に変換されます。次に、各 FC 層の再量子化 OP は、対応する層の融合 INT8 OP と融合されます。
最初の全結合層は、負の入力値を持つことができますが、後続の全結合層は、各層の前の ReLU 活性化により正の入力値のみを持ちます。最高の精度を得るためには、最初の FC には後続の FC とは異なる量子化アルゴリズムを使用します。推奨入力データ分布は、画像や音声のような対称データではないため、そのような入力データでは非対称量子化のほうが対称量子化よりも精度の低下を抑えられることが分かりました。
したがって、最初の FC では次のような 8 ビットの非対称量子化を使用します。
- A が入力、W が重み、B がバイアスの場合、FC への入力データの量子化係数は Qa = 255/(max(Af32)-min(Af32)) であるため、量子化されたデータは Au8 = round(Qa (Af32-min(Af32))) です。
- 重みの量子化係数は Qw = 127/max(|Wf32|) であるため、量子化された重みは Ws8 = round(Qw Wf32) です。
- 添え字「f32」、「s32」、「s8」、および「u8」はそれぞれ符号付き INT32、符号付き FP32、符号付き INT8、および符号なし INT8 精度を表します。
- 入力データと重みに適用された量子化に対応するため、シフトされたバイアスは B's32 = Qa Qw Bf32 + Qa min(Af32) Ws8 になります。
- 最初の FC の出力は、Xs32 = Ws8 Au8 + B's32 = Qa Qw Wf32 (Af32-min(Af32)) + Qa Qw (Wf32 Af32+Bf32)= Qa Qw Xf32 です。ここで、Xf32 は FP32 精度の最初の FC の元の出力です。
- 2 つ目以降の FC 層では、入力データの 8 ビット対称量子化が行われます。FC への入力の量子化係数は、255/(max(Af32)) になります。
今後の取り組みとして、量子化プロセスを効率良くスケーリングするため、インテルでは精度とパフォーマンスの要件に応じてモデルを量子化するスケーラブルな自動量子化ツールを開発しています。
推論パフォーマンス
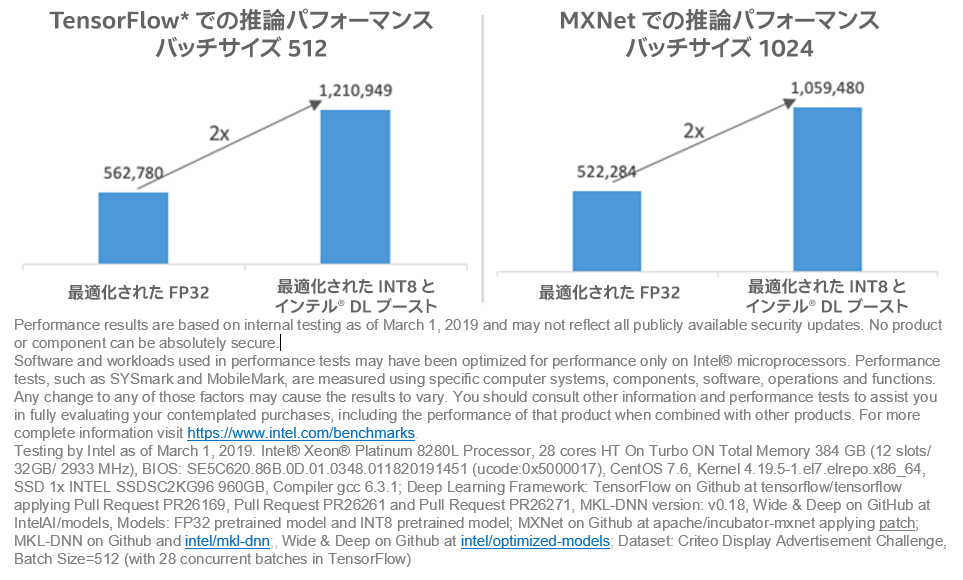
インテル® DL ブースト・テクノロジーと低い精度の INT8 推論を使用することで、レイテンシーとスループットの向上という利点が得られます。図 6 は、FP32 と比較して INT8 推論は、0.5% 未満の精度低下で 1 秒間に 2 倍以上のレコードを処理できることを示しています。
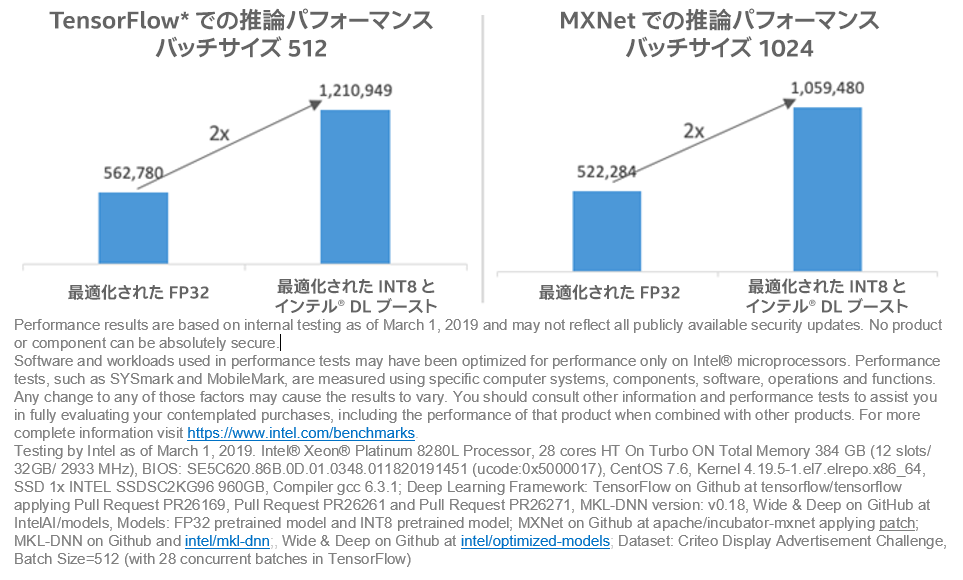
図 6. インテル® DL ブーストによる推論パフォーマンス推論は、最適化された FP32 モデルを使用して、2,000,000 サンプルの評価データセットで行われました。TensorFlow* におけるパフォーマンスは、バッチサイズ 512では 562,780 サンプル/秒から 1,210,949 サンプル/秒に向上しています。MXNet におけるパフォーマンスは、バッチサイズ 1024 では 522,284 サンプル/秒から 1,059,480 サンプル/秒に向上しています1。
実行
- トレーニング済み FP32 と量子化された INT 8 ワイド & ディープモデルを使用して TensorFlow* で推論を実行する手順は、GitHub* の IntelAI/models (英語) を参照してください。
- FP32 トレーニングの手順と、FP32 および INT8 モデルを使用して MXNet で推論を実行する手順は、intel/optimized-models (英語) を参照してください。
システム構成
テストには次のシステム構成を使用しました。
- インテル® Xeon® Platinum 8280L プロセッサー、28 コア、インテル® ハイパースレッディング・テクノロジー有効、インテル® ターボ・ブースト・テクノロジー有効、合計メモリー 384GB (12 スロット/32GB/2933MHz)、BIOS: SE5C620.86B.0D.01.0348.011820191451 (ucode:0x5000017)、CentOS* 7.6、カーネル 4.19.5-1.el7.elrepo.x86_64、SSD 1x INTEL SSDSC2KG96 960GB、コンパイラー gcc 6.3.1
- ディープラーニング・フレームワーク: GitHub* の tensorflow/tensorflow で公開されている TensorFlow* (Pull Request PR26169 (英語)、Pull Request PR26261 (英語)、および Pull Request PR26271 (英語) を適用)、インテル® MKL-DNN バージョン: v0.18、GitHub* (英語) の IntelAI/models で公開されている Wide & Deep、モデル:
FP32 トレーニング済みモデル (9MB、PB)
および INT8 トレーニング済みモデル (5MB、PB)
https://storage.googleapis.com/intel-optimized-tensorflow/models/wide_deep_int8_pretrained_model.pb - GitHub* の apache/incubator-mxnet (英語) で公開されている MXNet (patch (英語) を適用)、GitHub* および intel/mkl-dnn で公開されているインテル® MKL-DNN
- GitHub* の intel/optimized-models (英語) で公開されている Wide & Deep
- データセット: Criteo Display Advertisement Challenge、バッチサイズ = 512 (TensorFlow* で 28 バッチを同時実行)
推論パフォーマンスは 1 秒あたりのデータサンプル処理数で測定 (数値が高いほうが良い)。
まとめ
この記事では、インテル® DL ブーストを使用して推論パフォーマンスを効率良く高速化するため、ワイド & ディープ推奨システムモデルを量子化および最適化する方法を示しました。インテル® DL ブーストは、FP32 精度と比較して、INT8 で精度の低下を 0.5% 未満に抑えつつ、2 倍の推論パフォーマンスを提供します。
脚注
1. 性能の測定結果は 2019 年 3 月 1 日時点のインテルの社内テストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。詳細については、https://www.intel.com/benchmarks (英語) を参照してください。
2019 年 3 月 1 日時点のインテルの社内テスト。インテル® Xeon® Platinum 8280L プロセッサー、28 コア、インテル® ハイパースレッディング・テクノロジー有効、インテル® ターボ・ブースト・テクノロジー有効、合計メモリー 384GB (12 スロット/32GB/2933MHz)、BIOS: SE5C620.86B.0D.01.0348.011820191451 (ucode:0x5000017)、CentOS* 7.6、カーネル 4.19.5-1.el7.elrepo.x86_64、SSD 1x インテル® SSDSC2KG96 960GB、コンパイラー gcc 6.3.1。ディープラーニング・フレームワーク: GitHub* の tensorflow/tensorflow (英語) で公開されている TensorFlow* (Pull Request PR26169 (英語)、Pull Request PR26261 (英語)、および Pull Request PR26271 (英語) を適用)、ディープニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN) v0.18、GitHub* (英語) の IntelAI/models (英語) で公開されている Wide & Deep、モデル: FP32 pretrained model (英語) と INT8 pretrained model (英語)。GitHub* の apache/incubator-mxnet で公開されている MXNet (patch (英語) を適用)。GitHub* と intel/mkl-dnn で公開されているインテル® MKL-DNN。GitHub* の intel/optimized-models (英語) で公開されている Wide & Deep。データセット: Criteo Display Advertisement Challenge、バッチサイズ = 512 (TensorFlow* で 28 バッチを同時実行)。
© 2019 Intel Corporation.
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
