
この記事は、インテル® デベロッパー・ゾーンに公開されている「HPC Cluster Tuning on 3rd Generation Intel® Xeon® Scalable Processors」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
この記事の PDF 版はこちらからご利用になれます。
原文公開日: 2021年8月17日
はじめに
ハイパフォーマンス・コンピューティング (HPC) アプリケーションに使用するサーバーのパフォーマンスを最適化するには、ほかのエンタープライズ・アプリケーションで使用するサーバーとは異なる設定が必要となる場合があります。HPC クラスターでは、MPI ライブラリーとハイパフォーマンス・ファブリックを使用するアプリケーションのワークロード実行時間を短縮することが目標です。本ガイドでは、インテル社内で実施したテストにおいて、アプリケーション・パフォーマンスを改善することが実証された、システムおよびソフトウェア設定について説明します。
ここでの設定は、2 ソケットの第 3 世代インテル® Xeon® スケーラブル・プロセッサー・ベースのサーバーを実行するマルチノード HPC クラスターで検証しています。本ガイドでは、ほかのハードウェアは評価していません。
本ガイドの目的は、典型的なマルチユーザーで運用されるクラスター向けに最適化された環境を提供することです。これらの設定は、MPI ライブラリーを使用する多くのマルチノード・アプリケーションにとって有益であると考えられます。しかし、HPC アプリケーションによっては、本ガイドの設定によって意図しない影響を受ける可能性があり、特定のアプリケーションのパフォーマンス向上を保証するものではありません。
第 3 世代インテル® Xeon® スケーラブル・プロセッサー
第 3 世代インテル® Xeon® スケーラブル・プロセッサー (開発コード名 Ice Lake) は、AI アクセラレーション機能を内蔵した、業界最高水準のワークロード最適化プラットフォームであり、マルチクラウドからインテリジェント・エッジまで、データ変革の効果を加速するシームレスなパフォーマンス基盤を提供します。以下は、第 3 世代インテル® Xeon® スケーラブル・プロセッサーでサポートされている機能の一部です。
- パフォーマンスの強化
- VNNI 命令によるインテル® ディープラーニング・ブーストの強化
- インテル® ウルトラ・パス・インターコネクト (インテル® UPI) リンクの増加
- DDR4 メモリーの速度と容量の向上 (2 つの内蔵メモリー・コントローラー、コントローラーごとに 4 チャネル)
- インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) 命令
- データセンター向けインテル® セキュリティー・ライブラリー (インテル® SecL – DC) をサポートするインテル® セキュリティー・エッセンシャル
- インテル® スピード・セレクト・テクノロジー (インテル® SST)
- インテル® Optane™ パーシステント・メモリー 200 シリーズのサポート
ハードウェア構成
DIMM スロット構成
プラットフォームがサポートする最速の DIMM 速度で、すべてのメモリーチャネルを使用できます。
第 3 世代インテル® Xeon® スケーラブル・プロセッサーは、プロセッサーごとに 8 メモリーチェネルをサポートします。すべてのメモリーチャネルに、少なくとも 1 つの DIMM を配置する必要があり、メモリースロットには、同一のデュアルランクのレジスタード DIMM を装着します。デュアルランクの DIMM は、シングルランクの DIMM よりもパフォーマンスが高くなります。DIMM の速度は、プラットフォームでサポートされている最速の速度にする必要があります。
1 つ以上の DIMM を使用してもメモリー速度が低下しない場合、同じメモリー速度であれば、チャネルあたり 2 つの DIMM のほうがチャネルあたり 1 つの DIMM よりもわずかにパフォーマンスが向上する可能性があります。
HPC ベンチマークには、インテル® Optane™ メモリーを使用しないでください。
メモリーサイズ
ほとんどの HPC アプリケーションやベンチマークは、物理メモリーサイズを大きくすることでメリットが得られます。具体的な要件は、アプリケーションによって決定されます。例えば、GROMACS または LAMMPS 分子動力学コードを実行する各クラスターノードには、最低 96GB の RAM が必要です。メモリー使用量のガイドラインに従って、各メモリーチャネルに 16GB DDR4 DIMM を 1 つずつ使用すると、2 ソケットのシステムでは合計 256GB の RAM になります。
メモリーエラー
修正されたメモリーエラーが繰り返されると、パフォーマンスが低下します。メモリー修正が有効な場合、dmsg またはシステム・イベント・ログを確認し、修正されたメモリーイベントがないことを確認してから、繰り返しメモリエラーが発生する DIMM を交換します。
BIOS 設定
「Sub-NUMA Clusters」と「One-way IMC Interleave」を有効にし、電源プロファイルを「Performance」に設定します。
「CPU Power and Performance Policies」と「Fan Profiles」は常に「Performance」に設定すべきです。
「Turbo Mode」を有効にします。HPC アプリケーションは CPU 使用率が高いため、これにより結果が改善される可能性は低いですが、パフォーマンスが低下することはありません。ベンチマーク実行のパフォーマンス・メトリックを以前の実行と一致させる必要がある場合は、このオプションを無効にします。
ハイパースレッディング (SMT: Symmetric Multi-Threading) は有効にすることを推奨しますが、これによってもたらされるパフォーマンスの利点はアプリケーションにより異なります。アプリケーションによっては、パフォーマンスがわずかに低下することがあります。使用するアプリケーションごとに、ハイパースレッディングのパフォーマンスを評価することをお勧めします。STREAM ベンチマークでは、ハイパースレッディングを無効にすることを推奨します。
推奨設定
最適化された設定と推奨値を使用してください。アスタリスク (*) はデフォルト値を示します。
| 設定項目 | 推奨値 |
|---|---|
| Hyper-Threading (SMT) | Enabled* (上記の説明を参照) |
| Core Prefetchers | Enabled* |
| Turbo Boost Technology | Enabled* |
| Intel® SpeedStep® (P-States) | Disabled |
| SNC (Sub-NUMA Clusters) | Enabled |
| IMC Interleave | One-way |
| UPI Prefetch | Enabled* |
| XPT Prefetch | Enabled* |
| Total Memory Encryption (TME) | Disabled |
| Memory controller page policy | Static closed |
| Autonomous Core C-State | Disabled* |
| CPU C6 Report | Disabled* |
| Enhanced Halt State (C1E) | Disabled* |
| Package C State | C0/C1 State* |
| Relax Ordering | Disabled* |
| Intel VT for Directed I/O (Intel VT-D) | Disabled* |
| CPU Power Policy | Performance |
| Local/Remote Threshold | Auto* |
| LLC Prefetch | Disabled* |
| LLC Dead Line Alloc. | Enabled* |
| Directory AToS | Disabled* |
| Direct-to-UPI (D2U) | Enabled |
| DBP-for-F | Enabled |
設定の説明
Sub-NUMA Cluster (SNC)
SNC は、以前のプロセッサー・ファミリーに搭載されていたクラスターオンダイ (Cluster-On-Die) と同様の局所性のメリットを、COD のデメリットなしに提供する機能です。SNC は、ラスト・レベル・キャッシュ (LLC) をアドレス範囲に基づいて不連続のクラスターに分割し、各クラスターをシステム内のメモリー・コントローラーのサブセットにバインドします。SNC は LLC の平均レイテンシーを改善する、以前のプロセッサー・ファミリーにあった COD 機能の代替となるものです。
すべての HPC アプリケーションでは、SNC と XPT/UPI プリフェッチの両方を有効にする必要があります。これにより、1 ソケットあたり 2 クラスターを設定して、LLC 容量を効率良く利用し、近くの コア/IMC を利用することでレイテンシーを低減できます。
内蔵メモリー・コントローラー (IMC) のインターリーブ
これは、内蔵メモリー・コントローラー (IMC) 間のインターリーブを制御します。SNC が有効な場合、IMC インターリーブは一方向に設定され、インターリーブは行われません。
XPT (eXtended Prediction Table) Prefetch
XPT プリフェッチは、ローカル・メモリー・アクセス・レイテンシーを低減するために設計された新しい機能です。各コアの「LLC ミス予測器」として XPT プリフェッチは、LLC ルックアップから「ミス」を予測した場合にのみ、LLC ルックアップと並行して投機的 DRAM リード要求を発行します。
UPI (Ultra-Path Interconnect) Prefetch
UPI プリフェッチは、リモート・メモリー・アクセス・レイテンシーを低減するために設計された新しい機能です。UPI コントローラーは、ホームソケットにリモートリードが到着すると、LLC ルックアップと並行して、メモリー・コントローラーに UPI プリフェッチを発行します。
Direct-to-UPI (D2U または D2K)
D2U は、リモート・リード・トランザクションのレイテンシーを低減する機能です。D2U を有効にすると、IMC はデータを CHA (Caching and Home Agent) を経由せずに直接 UPI に送信してレイテンシーを低減します。NUMA に最適化されているワークロードや、高レベルのメモリー帯域幅を使用するワークロードは、D2U を無効にしてもあまり効果が得られませんが、有効にしてください。
DBP-for-F
DBP-for-F は、マルチスレッドのワークロードに恩恵をもたらす新機能ですが、シングルスレッドのワークロードでは、パフォーマンスが低下する可能性があります。
Linux* 向けの最適化
仮想マシン
仮想マシンの内部でアプリケーションを実行すると、パフォーマンスが低下しますが、低下はわずかである可能性があります。パフォーマンスへの影響は、使用するハイパーバイザーと設定に依存します。HPC ベンチマークは仮想マシン内で実行しないでください。
ネットワーク設定
HPC アプリケーションの多くは、粒度が細かく、小さなペイロードで頻繁なプロセス間通信を必要とします。そのため、パフォーマンスは帯域幅よりも通信レイテンシーに依存します。ハイパフォーマンスのファブリックを使用することで、メッセージのレイテンシーを最小化できます。
パフォーマンスを最大化するには、CPU あたり 1 つのファブリック・ホスト・コントローラーを使用します。サーバーでは、各 PCIe* 拡張スロットが CPU の 1 つに関連付けられます。各 CPU が自身のファブリック・ホスト・コントローラーに関連付けられるように、ファブリック・ホスト・コントローラーを設置します。PCIe* レーンの割り当てを決定するには、システムボードの技術仕様書を参照する必要があります。
ファブリックのパフォーマンスは、複数のリンク (デュアルレールまたはマルチレール) を使用してさらに向上できます。多くの場合、必要な帯域幅は限られており、マルチレールを使用してもパフォーマンスのメリットは期待できません。
ディスク設定
ディスク設定は、HPL、HPCG、STREAM などのベンチマーク・パフォーマンスにほとんど影響を与えません。
CPU 設定
ベンチマークを実行する前に、すべての CPU をパフォーマンス・モードに設定する必要があります。例えば、cpupower ユーティリティーを使用する場合は、以下を実行します。
cpupower -c all frequency-set --governor performanceサービス
不要なサービスや cron ジョブをすべて無効にします。
HPC ベンチマークを実行する場合は、バッチ・スケジューラーやリソース・マネージャーを使用するジョブとして実行せず、ベンチマークが完了するまでこれらのサービスを無効にする必要があります。ベンチマークの実行中、使用するシステムにほかのユーザーがログインしていないことを確認してください。
アプリケーション設定
開発環境
最新のインテル® oneAPI HPC ツールキットを使用してアプリケーションを設定し、実行します。
インテル® oneAPI ツールキットは、統一されたツールセットにより、CPU、GPU、FPGA アーキテクチャー向けのアプリケーションとソリューションの開発を可能にします。インテル® oneAPI HPC ツールキットは、ベクトル化、スレッド化、マルチノード並列化、メモリー最適化の最新技術により、HPC アプリケーションの開発、解析、最適化、および拡張に必要なものを提供します。インテル® oneAPI HPC ツールキットを使用するには、インテル® oneAPI ベース・ツールキットが必要です。
インテル® oneAPI ツールキットは、ローカル・インストーラーを使用してインストールするか、オンラインの APT および YUM リポジトリーを介してインストールできます。最新のインストーラーは、次の URL からダウンロードできます。
https://software.intel.com/content/www/us/en/develop/tools/oneapi/hpc-toolkit/download.html (英語)
インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL)
インテル® oneMKL は、BLAS、LAPACK、スパースソルバー、高速フーリエ変換 (FFT)、乱数生成関数 (RNG)、サマリー統計、データ適合、ベクトル演算などの拡張数学ルーチンやライブラリーを提供します。HPC アプリケーションやベンチマークのパフォーマンスを最適化するため、インテル® oneMKL を使用することを推奨します。
インテル® oneMKL はインテル® oneAPI ベース・ツールキットに含まれていますが、インテル® MPI ライブラリーまたはインテル® Fortran コンパイラーでインテル® oneMKL をサポートするには、インテル® oneAPI HPC ツールキットが必要です。
インテル® MPI ライブラリー
インテル® MPI ライブラリー 2021.2.0 以降を使用してください。MPI アプリケーションは、インテル® oneAPI ツールキット 2021.2.0 以降のコンパイラーとライブラリーを使用して、インテル® MPI ライブラリー 2021.2.0 以降でコンパイルする必要があります。
ユーザー環境
インテル® ハイパースレッディング・テクノロジー
マルチスレッド・コアの同時使用によるメリットがない OpenMP* ベースのアプリケーションでは、OpenMP* スレッド数がシステムで利用可能な物理コア数を超えないようにします。OpenMP* スレッドは、OMP_NUM_THREADS 環境変数を設定することで制御できます。
また、サーバーでインテル® ハイパースレッディング・テクノロジーが有効かどうかに応じて、適切なスレッドとコアのアフィニティーを設定します。
インテル® ハイパースレッディング・テクノロジーが有効な場合:
export KMP_AFFINITY=granularity=fine,compact,1,0インテル® ハイパースレッディング・テクノロジーが無効な場合:
export KMP_AFFINITY=compactマルチレールのインテル® Omni-Path ファブリック
システムがインテル® Omni-Path ファブリックと複数のリンクで構成されている場合、マルチレール通信を有効にします。PSM2_MULTIRAIL 変数を、各ホスト・コントローラーのケーブルリンク数と等しくなるように設定します。デフォルトでは、1 に設定されています。
ベンチマークの最適化
HPC ベンチマークに最適な設定は、アプリケーションとは異なる場合があります。
HP LINPACK
HP LINPACK ベンチマークの最適なチューニングは、ほかのベンチマークやアプリケーションのパフォーマンスに影響を与える可能性のあるカスタム設定を使用します。そのため、ここでは紹介していません。HP LINPACK ベンチマークのチューニングについては、インテルにお問い合わせください。
HPCG
インテル® oneMKL に含まれるインテル® Optimized HPCG ベンチマークを使用します。
HPCG (High Performance Conjugate Gradients: 高性能共役勾配) ベンチマーク・プロジェクト (http://hpcg-benchmark.org (英語)) は、重要なアプリケーションの広範なセットに、より密接に合致するメトリックを提供することで、HP LINPACK (HPL) ベンチマークを補完します。このベンチマークは、以下のパフォーマンスを測定します。
- 疎行列-ベクトル乗算
- ベクトル更新
- グローバルドット積
- 局所的な対称ガウス・サイデル法のスムージング
- スパース三角ソルバー
インテル® Optimized HPCG ベンチマークは、インテル® Xeon® プロセッサー向けに最適化された HPCG ベンチマークの実装で、インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX)、インテル® アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2) 、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) を含む最新プロセッサーのテクノロジーがサポートされています。
このベンチマークは、インテル® oneMKL インストール・ディレクトリー以下の /benchmarks/hpcg サブディレクトリーにあります。以下の手順に従って、ベンチマークを準備してください。
https://software.intel.com/content/www/us/en/develop/documentation/onemkl-linux-developer-guide/top/intel-math-kernel-library-benchmarks/intel-optimized-high-performance-conjugate-gradient-benchmark/getting-started-with-intel-optimized-hpcg.html
インテル® Xeon® スケーラブル・プロセッサー向けに最適化されたバイナリー xhpcg_skx を使用してください。インテル® Optimized HPCG パッケージには、これらのバージョンのベンチマークをほかの MPI 実装向けにビルドするために必要なソースコードも含まれています。また、以下の点にも注意してください。
- 問題サイズが小さいと非常に良好な結果が得られます。しかし、問題サイズはキャッシュに収まらない大きさでなければならず、そうでない場合は無効な実行と見なされます。また、物理メモリーの 25% 以上を使用する必要があります。最適な局所次元のグリッドサイズは、実用的な評価を通じて決定する必要があります。
- 必要な実行時間である 3600 秒より長く実行しても、パフォーマンスへの影響は見られません。
- 総コア数あたり 1~1.25 MPI プロセス、MPI プロセスあたり 12~16 OpenMP* スレッドを使用した場合、最良の結果が得られます。最適な設定は、実験によって決定される必要があります。スレッドを割り当てる際は、SMT コアをスキップしてください。
STREAM
STREAM ベンチマークは、4 つの単純なベクトルカーネル (Copy、Scale、Add、Triad) の持続可能なメモリー帯域幅 (MB/秒) と対応する計算速度を測定するために設計された、単純な合成ベンチマークです。また、HPCC ベンチマーク・スイートにも含まれています。ソースコードは、http://www.cs.virginia.edu/stream/ から入手可能です。測定項目は以下のとおりです。
- 持続可能なメモリー帯域幅
- 単純なベクトルカーネルの対応する計算速度
STREAM の一般的なルールとして、各配列は、実行時に使用されるすべてのラスト・レベル・キャッシュの合計の少なくとも 4 倍でなければなりません。STREAM は標準のまま実行することも、最適化することもできます。最適化した場合、結果は最適化したものとして識別する必要があります (詳細は、http://www.cs.virginia.edu/stream/ref.html (英語) の STREAM FAQ を参照)。
インテル® プロセッサーで標準の STREAM ベンチマークを最高のパフォーマンスで実行する方法については、以下を参照してください。
https://software.intel.com/content/www/us/en/develop/articles/optimizing-memory-bandwidth-on-stream-triad.html
関連情報
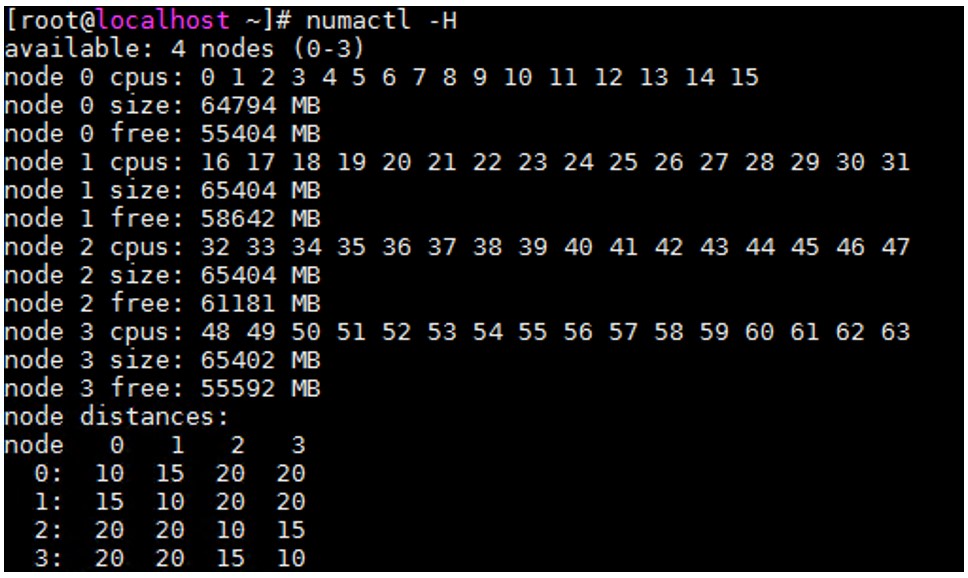
numactl
numactl ツールを使用すると、サーバーの NUMA ノードの構成とステータスを表示できます。例えば、CPU コア数、各ノードのメモリーサイズ、異なるノード間の距離などです。このツールにより、指定した CPU コアにプロセスをバインドすることができ、指定した CPU コアは対応するプロセスを実行します。
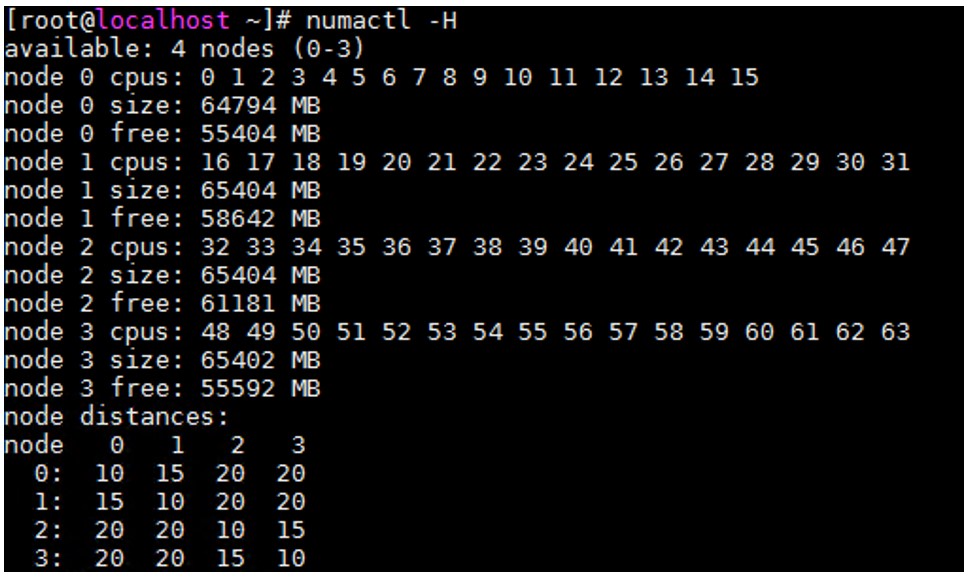
図 1: numactl の出力例
numastat
numastat を使用すると、NUMA ノードのステータスを表示できます。ステータスには、CPU コアによるローカルおよびリモート・メモリー・アクセスが含まれます。
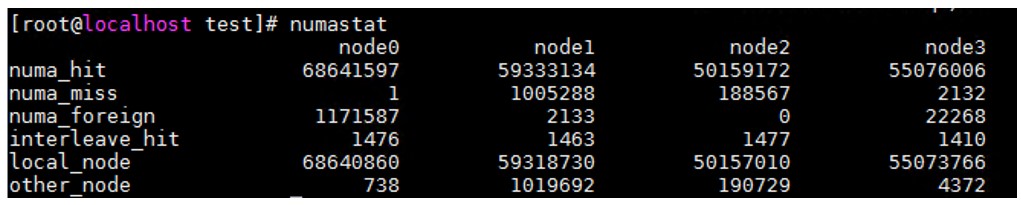
図 2: numastat の出力例
PCM
PCM (Processor Count Monitor) を使用して、インテル® CPU コアのパフォーマンス・メトリックを監視できます。PCM は、パーシステント・メモリーの帯域幅を監視するためによく使用されます。https://github.com/opcm/pcm (英語) からダウンロードできます。
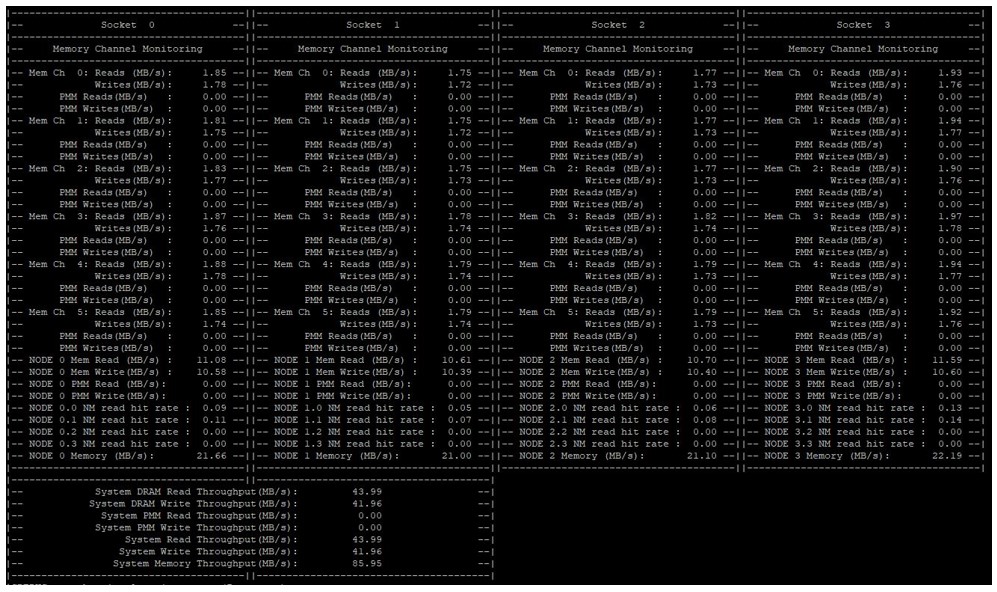
図 3: パーシステント・メモリー帯域幅を監視する PCM の例
法務上の注意書き
インテルのテクノロジーを使用するには、対応したハードウェア、ソフトウェア、またはサービスの有効化が必要となる場合があります。
絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
実際の費用と結果は異なる場合があります。
開発コード名は、インテルが開発中で一般に公開されていない製品、テクノロジー、サービスを識別するために使用されます。これらは「商用」の名称ではなく、商標として機能することを意図したものではありません。
本資料で説明されている製品には、エラッタと呼ばれる設計上の不具合が含まれている可能性があり、公表されている仕様とは異なる動作をする場合があります。現在確認済みのエラッタについては、インテルまでお問い合わせください。
© Intel Corporation. Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
