

この用語集はインテル® ソフトウェア・ネットワークの Parallel Programming Glossary of Technical Terms (http://software.intel.com/en-us/blogs/2008/05/27/parallel-programming-glossary-of-technical-terms/) を基に日本語で作成されました。
並列プログラミングに関連する最新の用語を日本語で追加していく予定です。もし追加を希望される用語がございましたら、iSUS 事務局までお知らせください。
アトミックの意味は状況によってやや異なります。ハードウェア・レベルのアトミック操作は割り込みがないことを指します (例: ロードとストア、アトミックなテスト・アンド・セット命令)。データベースのアトミック操作 (またはトランザクション) は完全に実行されるか、全く実行されないかのどちらかです。並列プログラミングのアトミック操作は安全に同期され、ほかの実行ユニット (UE) やエンジン (DMA など) によって中断されてはならない操作を指します。アトミック操作は、必ず終了しなければなりません (例えば、無限ループであってはなりません)。
1 つまたは複数のプロセッサーがアクセスできるメモリー範囲です。状況によって、物理メモリーであったり、仮想メモリーであったりします。
アプリケーション・プログラミング・インターフェイス (Application Programming Interface)
アプリケーション・プログラミング・インターフェイス (API) は、ソフトウェア・モジュール (通常はアプリケーション・プログラム) から別のソフトウェア・モジュールの機能を利用するのに必要な情報と呼び出し規約を定義します。具体的な例として、並列プログラミングの API に MPI* があります。”API” という用語は、プログラマーがプログラムの特定の機能を表すために使用する表現方法を指すこともあります。例えば、OpenMP* 仕様が API と呼ばれることがあります。API で重要な点は、API を使用するプログラムは、再コンパイルすることで、その API をサポートしているどのシステム上でも実行できることです。
(特定の仮定に基づいて) P 個のプロセッサーを搭載したシステムでアルゴリズムを実行した場合に得られる最大スピードアップを、次のように定義した法則です。
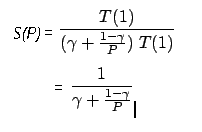
ここで γ は プログラムのシリアル領域、T(n) は n 個のプロセッサーで実行した場合の合計実行時間です。「スピードアップ」と「シリアル領域」の説明もご覧ください。
暗黙的な並列言語 (Implicitly Parallel Language)
並行に実行される処理の詳細と、その実装方法はコンパイラーに委ねられる並列プログラミング言語です。ほとんどの並列関数型言語と並列データフロー言語は、暗黙的な並列言語です。
インクリメンタルな並列化 (Incremental Parallelism)
インクリメンタルな並列化は、既存のプログラムにおいて 1 つずつループを並列化して、徐々に並列性を高めていく手法です。プログラムに変更を加えるたびにテストを行って、オリジナルのプログラムと同じ動作になることを確認することで、変更による不具合が発生する可能性を大幅に軽減します。「リファクタリング」の説明もご覧ください。
プリミティブ型のデータを対応するラッパー型に自動変換する Java* 2 1.5 の言語機能です (例: int から Integer)。
カウンティング・セマフォー (Counting Semaphore)
「セマフォー」の説明を参照してください。
仮想共有メモリー (Virtual Shared Memory)
共有メモリーの抽象化を提供し、分散メモリー型アーキテクチャーのハードウェアであっても共有メモリーへの書き込みを行うことができます。仮想共有メモリーシステムは、オペレーティング・システム内に実装することも、プログラミング環境の一部として実装することもできます。
コンピューターのメインメモリーの内容をミラーリングした比較的小さなメモリーデバイスで、プロセッサーの近くに配置されています (最近のほとんどのプロセッサーは、キャッシュをコアと同じダイに集積しています)。コンピューターのメインメモリーよりも非常に高速です。現代のコンピューター・システムでは、多くのアルゴリズムで 1 つまたは複数のレベルからなるキャッシュ階層が不可欠です。プロセッサーのほうがコンピューターのメインメモリーよりも遥かに高速なため、必要なデータをあらかじめキャッシュにロードしておいて計算中に再利用しないと、プロセッサーの処理能力を活かすことができません。
キャッシュとコンピューターのメインメモリーの間では、データはキャッシュラインと呼ばれる小さなバイトブロック単位で転送されます。キャッシュラインにマップされたメモリー内のバイトにアクセスする場合、キャッシュライン全体がコピーされます。キャッシュが一杯でほかのデータがキャッシュスペースを必要としている場合、あるいはほかのプロセシング要素 (PE) やエンジン/コントローラーがキャッシュラインに対応するメモリーへ書き込んでいる場合、キャッシュラインは無効になります。
マルチコア・プロセッサーでは、コアごとに個別のキャッシュがあります。多くの場合、1 または 2 階層の追加レベルのキャッシュが複数のコア間で共有されます。キャッシュの一貫性を保つことは (つまり、すべてのプロセッサーが個々のキャッシュを通してアクセスするメモリーの内容が同じになるようにすることは)、コンピューター設計者やコンパイラー開発者の責任です。ソフトウェアのパフォーマンスを最適化する場合、プログラマーはキャッシュの問題に注意する必要があります。
複数のエージェントが同一の限られたリソースを同時に要求している状態を表します。競合を解決する方法は、バス取得プロトコルからバックオフ・アルゴリズム、キャッシュ・コヒーレンシーまで多数あります。「MESI プロトコル」の説明もご覧ください。
並列プログラムに特有のエラーで、実行ユニット (UE) の相対的なスケジューリングの変更に伴い、プログラムの結果が変わります。通常は、適切な同期メカニズム (バリア、mutex、セマフォー) を使用せずに 2 つ以上の UE が共有変数やグローバル変数を変更することでこのエラーが発生します。
共有アドレス空間 (Shared Address Space)
実行ユニット (UE) 間で共有されるアドレス指定可能なメモリーのブロックです。
ハードウェアとソフトウェアの両方に適用される用語で、システム・コンポーネント間で共有されるメモリー領域があることを示します。プログラミング環境では、プロセッサー間またはスレッド間でメモリーが共有されることを意味します。ハードウェアでは、プロセッサーを結び付けているアーキテクチャー上の機能が共有メモリーであることを意味します。「共有アドレス空間」の説明もご覧ください。
プロセシング要素 (PE) で計算を実行する際に、そのプロセシング要素に関連付けられている (つまり、近くにある) データがどの程度使用されるかを表します。例えば、多くの密線形代数問題では、ハイパフォーマンスを達成するために、行列をブロックに分解してプロセッサーのキャッシュに読み込み、そのデータが多用されるように計算を組み立てます。これは、計算の局所性を高めるアルゴリズム変換の例です。
高可用性を実現するために冗長システムを形成したり、あるいは 1 つのインターフェイスを介してプールされたリソース (分散プリンターやバッチキューなど) を利用するために接続され、並列コンピューターとして使用されるローカル・コンピューターの集合体です。クラスター内のコンピューターは、クラスター・コンピューティング専用のものではなく、原則としてスタンドアロン・コンピューターとして個別に使用できます。つまり、クラスターを形成しているコンピューターと、コンピューターを接続するためのネットワークは、両方とも特別なものではありません。具体的な例として、イーサネットで接続されたワークステーション・ネットワークや並列コンピューティング用のラックマウント型サーバーなどがあります。「サーバー/ワークステーション・ファーム」の説明もご覧ください。
分散コンピューティングとリソース共有のためのアーキテクチャーです。グリッドシステムは、LAN や WAN (通常はインターネット) を介して結び付けられた異種のリソース群から成ります。個々のリソースは一般的なもので、計算サーバー、ストレージ、アプリケーション・サーバー、情報サービス、科学機器などが含まれます。通常、グリッドは、Web サービスや統合ミドルウェア・コンポーネントとして実装され、一貫性のあるインターフェイスを提供します。クラスターと違う点は、グリッドのリソースは集中管理されないことです。グリッド・ミドルウェアがシステムを管理するため、グリッド上のリソースの制御と使用ポリシーの管理はそれぞれのリソース所有者が行います。
クリティカル・セクション (Critical Section)
同時に 1 つの実行ユニット (UE) のみが共有リソースの操作を行うよう調停が必要なコード領域のことです。排他アクセスにより競合状態は回避できますが、データの一貫性が失われる恐れがあります。また、デッドロックが発生する可能性もあります。クリティカル・セクションは必要な場所でのみ使用し、できるだけ短くなるようにします。
コアとはプロセッサー内部にあるプロセシング要素で、実行ユニット (UE) の実行要求に対応します。プロセッサー・アーキテクチャーによって、コアごとに個別のキャッシュがある場合と、同じプロセッサーにあるほかのコアとキャッシュを共有する場合があります。
計算の効率性 E は、プロセシング要素の数 (P) で正規化されたスピードアップです。次の式で求めることができます。
E(P) = S(P)/P
並列コンピューターのリソースがどの程度効率的に使用されているかを示します。
プロセスが実際に書き込みを行うまでは共有ページをコピーしないことで、複数のプロセスで使用される物理メモリーページの割り当てを最適化する手法です。プログラム/ライブラリー・コードなどの読み取り専用ページは、静的に初期化されたデータとともに共有できます。プロセスが書き込みを行おうとすると、そのページで書き込みが許可されている場合は、そのページの書き込み可能なプライベート・コピーが作成されます。
サーバー/ワークステーション・ファーム (Server/Workstation Farm)
クラスターの一種です。1 つのアプリケーションを並列に実行するのではなく、独立した一連のジョブを大量に実行するのにクラスターを活用するため “ファーム” という用語が使われています。サーバーファームは現在よく使用されていますが、”ワークステーション・ファーム” は特定のコンピューティング・プラットフォーム (通常はシングルユーザーモデル専用の UNIX 系プラットフォーム) を指す古い用語です
サイクリック分割 (Cyclic Distribution)
データ (配列の要素など) やタスク (ループの反復など) を実行ユニット (UE) の数よりも多くなるように分割して、そのブロックを UE に 1 つずつ順番に割り当てます。
プログラムに特定のエンティティー (通常はデータ型) のプレースホルダーを含めることができるプログラミング言語の機能です。ジェネリック・コンポーネントは、プログラムで使用される前に定義されていなければなりません。ジェネリックは、Ada、C++ (テンプレート)、Java* で利用できます。「ジェネリック・プログラミング」の説明もご覧ください。
シストリック・アルゴリズム (Systolic Algorithm)
通常の隣接通信パターンを使用して複数のタスクが同期的に実行する並列アルゴリズムです。計算の多くは、ある種の再帰関係で再定式化することで、シストリック・アルゴリズムとして定式化できます。
プロセッサー群からなる並列アーキテクチャーで、各プロセッサーは隣接する少数のプロセッサーとつながれています (「ポイントツーポイント・アーキテクチャー」の説明を参照)。データがアレイの中を流れ、 プロセッサーに到達すると割り当てられた操作を実行し、その結果を隣接する 1 つまたは複数のプロセッサーに渡します。シストリック・アレイ中の個々のプロセッサーは個別の命令ストリームを実行できますが、実行は “ロックステップ” され、計算と通信を交互に行います。そのため、シストリック・アレイは SIMD アーキテクチャーと多くの共通点があります。
並行に実行しているエンティティー群 (通常はプロセスまたはスレッド) を指す一般名称です。「プロセス」と「スレッド」の説明もご覧ください。
自明な並列性 (Embarrassingly Parallel)
タスク同士が完全に独立しているタスク並列アルゴリズムです。「タスク並列」の説明、『Patterns for Parallel Programming』の「The Task Parallelism Pattern」セクション [Mattson2004] もご覧ください。
集合通信 (Collective Communication)
実行ユニット (UE) 群に対する高レベル操作で、UE 間の情報交換を行います。高レベル操作は、純粋な通信イベントの場合も (ブロードキャスト)、何らかの計算を含む場合もあります (リダクション)。
一連のステートメントの順序上の制約を示したもので、 グラフ中のノードはステートメントを表します。ノード A からノード B への矢印は、ステートメント A をステートメント B よりも前に実行する必要があることを示します。順序グラフに循環がある場合は、そこでデッドロックが発生します。
「フォーク/ジョイン」の説明を参照してください。
条件変数は、モニター同期メカニズムに不可欠です。プロセスまたはスレッドは、条件変数を使用して、モニターの状態が特定の条件を満たすようになるまで待機します。そして、条件が真になると、条件変数を使用して待機中のプロセスを実行可能な状態にします。各条件変数には、それを待機する休止 (遅延) プロセス/スレッドと対になります。条件変数に対する操作には、待機 (プロセス/スレッドを条件変数の待機中の対に追加する) とシグナルまたは通知 (条件変数の待機中の対にあるプロセス/スレッドを実行可能な状態にする) があります。「モニター」の説明もご覧ください。
ほとんどの処理には、コンカレンシー (並行性) を活用できる領域とシリアルに実行する領域があります。シリアル領域とは、プログラムの実行時間のうちシリアルに実行しなければならない部分のことです。例えば、プログラムの実行時間を setup (セットアップ)、compute (計算)、finalization (ファイナライズ) に分解すると、次のように表すことができます。
Ttotal = Tsetup + Tcompute + Tfinalization
setup と finalization は必ずシリアルに実行されるので、シリアル領域は次のように表すことができます。
?= (Tsetup + Tfinalization)/Ttotal
メモリー空間の移動に使用されるインクリメント値です。ストライドの厳密な意味は、状況によって異なります。例えば、連続するメモリーブロックに列優先順で格納された M×N 配列の列要素をスキャンする場合は 1 ストライドとなり、 同じ配列の行要素をスキャンする場合は M ストライドとなります。
共有メモリー・アーキテクチャーのキャッシュ間でキャッシュの一貫性を維持するためには、キャッシュとメモリー間の通信が必要です。通常、このトラフィックをスヌーピングと呼び、有効バンド幅を向上させずにオーバーヘッドだけを増やします。
プロセシング要素 (PE) 間のバスやリンクに対するローカル要求を排除してスヌープ・トラフィックを制限するデバイスです。
スピードアップ S は、対応するシリアルプログラムよりも並列プログラムのほうが何倍速いかを示す比率です。次の式で求めることができます。
S(P) = T(1)/T(P)
ここで、T(n) は n プロセシング要素のシステムで実行した場合の合計実行時間です。並列コンピューター上で、スピードアップがプロセシング要素 (PE) の数と等しい場合は、「完全に線形的なスピードアップ」と呼びます。
一部のコンピューターの基本的な実行ユニット (UE) です。UNIX* では、スレッドはプロセスに関連付けられていて、プロセスの環境を共有します。そのため、プロセスと比べると、スレッドのほうが比較的軽量です (プロセス間のコンテキスト・スイッチよりもスレッド間のコンテキスト・スイッチのほうがコストがかかりません)。より上位のレベルから見た場合、スレッドはほかのスレッドとアドレス空間を共有するので軽量な UE といえます。「実行ユニット」と「プロセス」の説明もご覧ください。
スレッドの作成と破棄にかかるオーバーヘッドを最小限に抑えるため、プログラムの実行中に管理されるスレッド群です。使用されていないスレッドは、プールによってアイドル状態で維持されます。スレッドプールは、明示的に使用される場合や、API によって暗黙に使用される場合があります。
特定の同期の実装に使用される抽象データ型です。セマフォーにはいくつかの種類があります。バイナリーセマフォーは、1 つの共有バイナリー値を使用して 1 つのリソースへのアクセスを制御します。カウンティング・セマフォーは、共有整数値を使用してリソース群 (バッファーや I/O チャネルなど) を制御します。使用される値は非負数で、2 つのアトミック操作 V (アップとも呼ばれる) と P (ダウンとも呼ばれる) をサポートしています。V 操作はセマフォーの値を 1 増加し、 P 操作は値を 1 減少します (非負数にならない場合のみ)。セマフォーの値が 0 の場合、P 操作は中断され、 値が正数になると再開されます。
すべての引数が評価された直後に、式の評価やプロシージャーの実行が行われるスケジューリング手法です。ほとんどのプログラミング環境で採用されており、遅延評価と対照的です。先行評価では、実際には計算に必要ない引数も計算しなければならないため、追加処理が発生することがあります (場合によっては、処理を終了できないこともあります)。
対称型マルチプロセッサー (Symmetric Multiprocessor)
各プロセッサーが同じ機能を持ち、すべてのメモリーアドレスへ “同じ時間” でアクセスできる共有メモリー型のコンピューターです。つまり、それぞれのプロセッサーは、メモリーアドレスと OS サービスの両方を平等に利用することができます。これは、共有アドレス空間はあるものの、物理アドレスの範囲とプロセシング要素間でメモリーへのアクセス時間が異なる NUMA コンピューターと対称的です。
この用語は、状況によってさまざまな意味を持ちます。ここでは、アルゴリズムやプログラムのある論理的な部分を構成する一連の操作を指しています。
1 つまたは複数の実行ユニット (UE) によって実行されるタスクを保持するためのキューです。タスクキューは、タスク並列アルゴリズムで (特に マスター/ワーカーを使用する場合に) 動的スケジューリング・アルゴリズムを実装するのによく使用されます。
並列コンピューティングの一種で、同時に実行されるタスクという観点から並行性 (コンカレンシー) を表します。非常に広範な マスター/ワーカー・アルゴリズム、明示的なタスクと、ループの反復からのタスクを作成する OpenMP* などのフレームワーク、明示的なメッセージパッシングを使用する SPMD プログラム、その他の多数の並列化手法などが含まれます。データ並列アルゴリズムをタスク並列アルゴリズムに変換することはできますが、タスク並列アルゴリズムをデータ並列アルゴリズムに変換することはできません。そのため、タスク並列のほうがより一般的なモデルといえます。データ並列と比較してみてください。
一部のプログラミング言語の機能で、共通のインターフェイス (関数型またはメソッドベース) を関連するデータ型のファミリーに適用できます (「抽象データ型」を参照)。複数の実装があり、それぞれ特定の型によりマッピングされます。多相性は、ジェネリック・プログラミングを実現するための主要な機能です。
タプルと呼ばれる複合オブジェクトが格納された共有メモリーシステムです。タプルとは、値や変数を保持するフィールドの小さなセットです。次に例を示します。
(3,”the larch”, 4)
(X, 47,[2, 4, 89, 3])
(“done”)
このように、タプルを構成するフィールドは、整数値、文字列、変数、配列、および使用するプログラミング言語で定義されているその他の値を保持することができます。従来のメモリーシステムはアドレスを基にオブジェクトにアクセスしていましたが、タプルは関連性によりアクセスできます。タプル空間を使用する場合、テンプレートを定義して、そのテンプレートと一致するタプルを取り出すことができます。タプル空間は、Linda 協調言語 [CG91] の一部として開発されました。Linda は、タプルの挿入、削除、コピーの取得を行うわずかなプリミティブからなる小さな言語です。C、C++、Fortran などの言語と組み合わせて使用することで、並列プログラムを作成できます。Linda は元々共有アドレス空間を持つマシンで実装されていましたが、仮想共有メモリーを使用するマシンでも実装され、分散メモリー型コンピューターのノードで実行する実行ユニット (UE) 間の通信にも使用されています。Linda に端を発した仮想共有メモリーの結合という概念は、JavaSpaces [FHA99] に取り入れられています。
単一代入変数 (Single-assignment Variable)
値を 1 回しか代入できない特殊な変数です。初期状態では値が割り当てられていません。いったん値が代入されると、その値を変更することはできません。この変数は、すべての入力変数に値が代入されるまでタスクが待機するデータフロー制御を使用したプログラミング環境でよく使われます。
評価結果が必要になるまで式を評価しない (あるいはプロシージャーを呼び出さない) スケジューリング手法です。遅延評価により不要な作業を避けることができます。また、場合によっては、ほかに終了する方法がない計算を終了できることもあります。遅延評価は、関数型プログラミングと論理プログラミングでよく使用されます。(先行評価と対照的です。)
抽象化は、状況によってさまざまな意味を持ちます。ソフトウェアでは、通常、いくつかの操作またはデータを 1 つに結合して、それに名前を付けることを指します。例えば、制御抽象化は、一連の操作を 1 つのプロシージャーに結合し、プロシージャー名を付けて使用します。オブジェクト指向プログラミングのクラスでは、データと制御の両方の抽象化を指します。より一般的には、抽象化とは要素の本質的特性を捉え、詳細は隠蔽することを表します。通常は、実際の詳細を気にせずに (あるいは詳細がまだ決まっていなくても)、その抽象化を扱うことができます。
抽象データ型 (ADT) とは、取り得る値のセットとそれらの値に対して行える操作によって定義されるデータ型です。値と操作は、値の表現方法や操作の実装とは関係なく定義されます。ADT を直接サポートしているプログラミング言語では、この型のインターフェイスは操作は示すものの、実装は隠蔽しています。原則として、この型を使用するクライアントに影響を与えずに実装を変更することができます。典型的な ADT の例として、一般にプッシュとポップという操作によって定義されるスタックが挙げられます。さまざまな内部表現が可能です。
超並列プロセッサー (Massively Parallel Processor)
何百ものプロセッサーでスケーリングするよう設計された分散メモリー型並列コンピューターです。高いスケーラビリティーを実現するために、超並列プロセッサー (MPP) マシンでは、スケーラブルなコンピューター向けに計算要素またはノードがカスタマイズされていて、 通常は、計算要素とスケーラブルなネットワークが緊密に統合されています。
強く順序付けられたメモリー (Strongly Ordered Memory)
強く順序付けられたメモリーは、メモリー操作の終了順序が開始順序と同じに保たれます。「弱く順序付けられたメモリー」の説明もご覧ください。
デザインパターンとは “状況に応じた問題に対する解法”、つまり、デザイン上繰り返し発生する問題に対する質の高いソリューションのことです。
並列コンピューティングの一種で、単一命令ストリームをデータ構造の複数の要素に同時に適用することでコンカレンシー (並行性) を表します。
並列プログラミングでよく見られるエラーで、循環依存が発生して実行ユニット (UE) 群がブロックされ、互いに待機することで計算がストールします。
同時マルチスレッディング (Simultaneous Multithreading)
同時マルチスレッディング (SMT) は、一部のプロセッサーのアーキテクチャー上の機能で、各サイクルで複数のスレッドが命令を発行することができます。つまり、プロセッサーを構成する関数ユニットで、同時に 2 つ以上のスレッドの要求を処理できます。SMT を活用しているシステムの具体的な例として、ハイパースレッディング・テクノロジーを採用したインテル製のマイクロプロセッサーがあります。
トランスピューターとは、Inmos Ltd. により開発されたオンチップの並列処理機能を備えたマイクロプロセッサーです。各プロセッサーには、ほかのトランスピューターのリンクと簡単に接続できる 4 つの高速通信リンクと、マルチプロセシング向けの非常に効率の良いビルトイン・スケジューラーが含まれています。
ノードとは、ネットワーク上の “末端” にある個々の計算要素のことです。一般に、分散メモリー型並列マシンを表すのに使用され、それぞれのノードには個別のメモリーと 1 つ以上のコアやプロセッサーがあります。ダイ上にネットワーク接続機能を備えたメニーコア・プロセッサーでは、ネットワークの末端におけるコアのクラスターを表すことがあります。
バイセクション・バンド幅 (Bi-section Bandwidth)
ノードを 2 等分したグループ (バイセクション) 間のネットワークの双方向通信能力です。ネットワークの各バイセクションで最短距離が使用されます。
d 次元の立方体の頂点にノードを配置したマルチコンピューターです。最も一般的な構成は、2n ノードのそれぞれが n ノードに接続されたバイナリー・ハイパーキューブです。
バス・アーキテクチャー (Bus Architecture)
周辺機器、コントローラー、メモリーを接続するための手法で、共通の共有データパスを介して互いのデータセット、アドレス、コントロール・ラインにアクセスできるようにします。同時にバスを制御できるバスマスターは 1 つだけです。これにより、バス操作の順序は保たれますが、競合が発生する可能性が高くなります。I/O とメモリー間、あるいはプロセッサー間でバスを分割し、ローカル操作を分離することで競合を減らすことができます。
実行ユニット (UE) のグループに適用される同期メカニズムで、グループのすべての UE がバリアに到達するまで、どの UE もバリアより先に進むことができません。つまり、すべての UE が揃うまで、バリアに到達した UE はサスペンドまたはブロックされます。すべての UE がバリアに到達すると、先へ (例えば、フォーク/ジョインのジョイン部分に) 進むことができます。
また、メモリーバリア (またはメモリーフェンス) は、特定のメモリーの読み取り/書き込み操作を保証します。
システムの処理能力で、通常は 1 秒あたりのアイテム数 (items per second) で表されます。並列コンピューティングでは、ネットワークやメモリー・サブシステムで 1 秒間に転送できるビット数 (bps: ビット毎秒) を表すのによく使用されます。インターフェイスの転送速度よりも 1 秒あたりに生成される情報量のほうが多い並列プログラムは、”バンド幅により制限された” プログラムと呼ばれます。「バイセクション・バンド幅」の説明もご覧ください。
汎用プログラミング (Generic Programming)
コンピューター・プログラミングのスタイルの 1 つで、パラメーター化により、アルゴリズムを使用するたびに変数部分を指定し、コンパイラーによって最適化された形式でインスタンス化することでアルゴリズムとデータ構造を適応できます。具体的な例として、STL (Standard Template Library) が挙げられます。「多相性」の説明もご覧ください。
ピアツーピア・コンピューティング (Peer-to-peer Computing)
複数のノード間で、それぞれのノードが対等な関係にある分散コンピューティング・モデルを指します。一般的に、この用語はそれぞれのノードの能力が同じで、どのノードもほかのノードと通信セッションを開始できる場合に使用されます。クライアント/サーバー・コンピューティングとは対照的です。ピアツーピア・コンピューティングでは、ファイル共有だけでなく、計算を分割することもできます。「グリッド」の説明もご覧ください。
ノード間で LAN 以外のリソースが共有されていない分散メモリー型 MIMD アーキテクチャーです。
ファクトリーとは、[GHJV95] で説明されているデザインパターンに対応するものです。抽象基本クラスのいくつかのサブクラスの中から 1 つのインスタンスを返すクラスを使用して実装されます。
プロセシング要素 (PE) 間で特定のメモリーアクセス順序が保たれるようにするための手法です。これは一種のバリアであり、命令セットとして実装され、バリアの後にある読み取り、書き込み、またはすべてのメモリー操作を開始する前に、バリアの前にある同様の操作が順序どおりに完了していなければなりません。
現在の実行ユニット (UE) をコピーして、その子として新しい実行ユニット (UE) を作成するための手法です。UNIX* や Linux* などのオペレーティング・システムでは、通常は fork システムコールの後に、他のプログラムファイルをロードし実行する exec システムコールが続きます。作業を完了するために限定された期間だけスレッドを追加する手法としても使用されます。「フォーク/ジョイン」の説明もご覧ください。
Pthreads や OpenMP* などのマルチスレッド API で使用されているプログラミング・モデルです。スレッドは fork を実行して、追加スレッドを生成し編成します。スレッド群 (OpenMP* ではチームと呼ぶ) は並行に実行され、 メンバーは並行タスクを完了すると、チームのすべてのメンバーがジョインポイントに到達するまでサスペンドされます。そして、すべてのメンバーが揃ったら、オリジナルのスレッドは実行を継続し、残りのチームメンバーの一部は開放され、一部は再利用されます。「バリア」の説明もご覧ください。
マルチスレッド・アプリケーションでフォルス・シェアリングを特定して、排除してみましょう。例えば、2 つのスレッドが同じキャッシュライン上にある別々のデータ要素にアクセスするとします。1 つのスレッドがこのキャッシュラインへ書き込みを行うと、別のスレッドでは同じキャッシュラインが無効になります。別のスレッドがこのキャッシュラインにあるデータに新たにアクセスしようとすると、キャッシュミスとなり、データをメモリーから再度ロードしなければなりません。
次のようにスレッド関数を実装すると、グローバル変数 sumLocal でフォルス・シェアリングが発生します。これは、2 つのスレッドが両方ともこの配列への書き込みを行っていて、それぞれの要素は別々であるものの同じキャッシュライン上にあるためです。
double sumLocal[N_THREADS];
. . . . .
. . . . .
void ThreadFunc(void *data)
{
. . . . . . .
int id = p->threadId;
sumLocal[id] = 0.0;
. . . . . .
. . . . . .
for (i=0; i |
スレッド 1 がキャッシュライン上の要素に書き込みを行うたびに、スレッド 2 の同じキャッシュラインのコピーが無効になります。そのため、スレッド 2 は配列の要素に書き込みを行う前に、データをキャッシュに再度ロードしなければなりません。これにより、今度はスレッド 1 のキャッシュラインのコピーが無効になります。何らかの理由でアプリケーションでこのような動作が発生すると、パフォーマンスが大幅に低下することがあります。
- 各スレッドのデータ要素をパディングして、ほかのスレッドの要素がすべて別々のキャッシュラインに配置されるようにする。
- スタックのローカルコピーを使用してすべての更新を行い、後でグローバルコピーに更新内容を反映する。
通常、この問題は、アプリケーションでグローバルな配列を使用して、各スレッドの情報を保持しようとする場合に発生します。デザイン段階でこの問題が見つかった場合は、修正するか、何らかの対策を講じる必要があります。
インテル® VTune™ Amplifier XE (旧インテル® VTune™ パフォーマンス・アナライザー) を使用することで、チューニング段階でフォルス・シェアリングを特定し、適切な措置をとることもできます。すべての場合において、開発者はキャッシュラインが重ならないよう注意してスレッド間の作業を分割し、フォルス・シェアリングを避けるべきです。
特定のドメインでアプリケーションのデザインを具現化した、再利用可能な部分的に完成されたプログラムです。プログラマーは、アプリケーション固有のコンポーネントを提供することで、プログラム全体を完成させます。
グループのすべてのメンバー (通常は、計算にかかわっているすべての実行ユニット (UE)) にメッセージを送ることです。
プログラミング環境 (Programming Environment)
プログラミング環境は、プログラムの作成に必要な基本ツールとアプリケーション・プログラミング・インターフェイス (API) を提供します。プログラミング環境では、コンピューターシステムの特定の抽象化 (プログラミング・モデルと呼ぶ) が暗黙的に使用されています。
プログラミング・モデル (Programming Model)
抽象化はプログラムの動作を論証する場合に役立ちます。通常、これらはハードウェアについての抽象的な見方に密接に関係しています。例えば、従来のシーケンシャル・コンピューターではフォン・ノイマン (von Neumann) モデルが使用されます。並列コンピューティングでは 1 つに統一されたハードウェア・モデルがないため、通常はハードウェアに密接に結び付いている複数のモデル (共有メモリー、分散メモリーとメッセージパッシング、あるいはこの 2 つを組み合わせたもの) が使用されます。"プログラミング・モデル" という用語は、非常に広範に使用されています。ハードウェアの抽象化に加えて、プログラミング・モデルは "オブジェクト指向プログラミング" や "構造化プログラミング" などのプログラミングのアーキテクチャー・スタイルに基づいていることもあります。
命令ストリームを実行するハードウェア要素を指す一般的な用語です。どのハードウェア要素 (コア、プロセッサー、コンピューターなど) がプロセシング要素と見なされるかは、状況によって判断されます。SMP ワークステーションのクラスターについて考えてみましょう。あるプログラミング環境で、それぞれのワークステーションが 1 つの命令ストリームを実行していると見なされる場合、プロセシング要素はワークステーションです。ただし、同じハードウェア上の異なるプログラミング環境で、それぞれのワークステーションの個々のプロセッサーまたはコアが別々の命令ストリームを実行していると見なされる場合、プロセシング要素はワークステーションではなく、プロセッサーまたはコアになります。
プログラムの命令を実行するのに必要なすべてのリソースで、 メモリー、I/O 記述子、ランタイムスタック、シグナルハンドラー、ユーザー/グループ ID、アクセス制御トークンなどが含まれます。より上位のレベルから見た場合、プロセスとは個別のアドレス空間を備えた "負荷が大きい" 実行ユニットといえます。
実行中にプロセスを実行するプロセッサーを変更することです。一般に、マルチプロセッサー・システムで動的にロード・バランシングを行うために使用されます。「ロード・バランシング」の説明もご覧ください。また、問題の発生したプロセッサーからプロセスを移動して、フォールトトレランスなコンピューティングをサポートするためにも使用されます。
分散共有メモリー (Distributed Shared Memory)
分散された個々の物理メモリー・サブシステム上の複数のプロセシング要素 (PE) 間で共有されるアドレス空間を構成するコンピューター・システムです。オペレーティング・システムやハードウェアにより分散共有メモリーシステムがサポートされる場合があります。また、分散共有メモリーを個別のミドルウェア・レイヤーとしてソフトウェアで完全に実装できる場合もあります (「仮想共有メモリー」を参照)。
分散コンピューティング (Distributed Computing)
計算処理の一種で、計算タスクをサブタスクに分割して、ネットワークでつながれたコンピューター群で実行します。使用されるネットワークは、専用のクラスター・インターコネクトではなく、LAN、WAN、インターネットなどの標準のネットワークです。代表的な例として、Seti@Home や Einstein@Home があります。
同時に 2 つ以上の実行ユニット (UE) がアクティブで、処理を実行している状態を指します。つまり、異なるプロセシング要素 (PE) で同時に実行されているか、同じプロセシング要素で複数の UE のアクションがインターリーブされています。
並行実行をサポートしているプログラムのことです。
並列処理における計算処理ではなく、処理の制御にかかった時間を指します。並列オーバーヘッドには、スレッドの生成とスケジューリング、通信、同期などが含まれます。
並列ファイルシステム (Parallel File System)
システムのすべてのプロセッサーがアクセス可能なファイルシステムで、複数の実行ユニット (UE) によって同時に読み取り/書き込みが行われます。並列ファイルシステムは、コンピューター・システムからは 1 つのファイルシステムのように見えますが、物理的にはいくつかのディスクに分散されています。効率良くするためには、読み取り/書き込みの総スループットはスケーラブルでなければなりません。
ベクトル型スーパーコンピューター (Vector Supercomputer)
中央演算装置にベクトル・ハードウェア・ユニットを搭載したスーパーコンピューターです。ベクトル・ハードウェアは、配列をパイプラインのように処理します。
ヘテロジニアス・システムは 2 種類以上のコンポーネントで構成されています。例えば、さまざまな種類のプロセッサーからなる分散システムなどです。
ポイントツーポイント・アーキテクチャー (Point-to-point Architecture)
プロセシング要素 (PE) のペアをつなぐリンク群からなる PE のインターコネクトです。リンクは競合しませんが、PE ごとのリンク数によって接続性が制限されます。大きな配列では、任意の PE 間を接続するため複数のリンクが必要です。ポイントツーポイント・アーキテクチャーの具体例として、ハイパーキューブがあります。
ホモジニアス・システムのコンポーネントはすべて同じ種類のものです。
1 つの実行ユニット (UE) が、並行に実行する UE のプールに作業単位をディスパッチするタスク並列手法の一種です。それぞれのワーカー UE は作業が完了したら、マスター UE に次の作業を要求し、すべての作業単位が分散されるまでこれを繰り返します。マスターは追加作業要求をシリアルに処理するのでスケーリングが制限されるため、この手法はマスターがワーカーに追加作業を割り振るのにかかる時間よりも、ワーカーがその作業を実行するのにかかる時間のほうが著しく長い場合にアルゴリズムを効率良く並列化できます。『Patterns for Parallel Programming』の「The Master/Worker Pattern」セクション [Mattson2004] もご覧ください。
マルチコア・プロセッサー (Multi-core Processor)
「1 つのプロセッサーに複数のコアが搭載されているアーキテクチャーで、従来のマルチプロセッサー・コンピューターに共通したキャッシュ・コヒーレントな共有アドレス空間を用いたアーキテクチャーを採用しています。通常、マルチコア・プロセッサーは、複数のコアを規定の熱設計枠に収めることができ、シングルスレッド (またはシングルコア) のパフォーマンスを最大限に引き出すように設計されています。
分散メモリー型 MIMD 並列アーキテクチャー・ベースの並列コンピューターを指します。このシステムは、ユーザーには 1 台のコンピューターに見えます。
アドレス空間を共有する複数のプロセッサーを搭載した並列コンピューターを指します。「マルチコア」の説明もご覧ください。
相互排他ロックです。mutex は、オブジェクトに同時にアクセスできるスレッド/プロセスを 1 つに制限することで、複数の実行ユニット (UE) の実行をシリアル化します。
明示的な並列言語 (Explicitly Parallel Language)
プログラマーがコンカレンシー (並行性) と、その並列処理方法を完全に定義する並列プログラミング言語です。具体的な例として、OpenMP*、Java*、MPI* などがあります。
メッセージ・パッシング・インターフェイス (Message Passing Interface)
多くの MPP ベンダーに加え、クラスター・コンピューティング分野でも採用されている標準化されたメッセージ・パッシング・インターフェイス (MPI) です。幅広く支持されているこの標準規格により、プログラムの移植性は向上します。あるプラットフォーム向けに開発された MPI ベースのプログラムを、MPI が実装された別のプラットフォームでも実行することができます。
メニーコア・プロセッサー (Many-core Processor)
1 つのプロセッサーに複数のコア (具体的な個数は明示されないが、通常 10 個以上を指す) が搭載されているアーキテクチャーで、マルチプロセッサー・コンピューターよりもはるかに優れたスケーラビリティーを発揮できるように基盤 (インターコネクト、メモリー階層など) が設計されています。搭載されているコアは同種の場合も (ホモジニアス・メニーコア・プロセッサー)、異種の場合も (ヘテロジニアス・メニーコア・プロセッサー) あります。メニーコア・プロセッサーは、対応するマルチコア・プロセッサーよりも多くのコアを規定の熱設計枠に収めることができ、シングルコア・パフォーマンスよりも、並列または "スループット" パフォーマンスに重点を置いて設計されています。
モニターとは、ホーアによって提唱された同期メカニズムの 1 つです [Hoa74]。抽象データ型の実装で、内部データへの相互排他アクセスを保証します。条件変数により条件同期を行います (「条件変数」を参照)。
読み取り/書き込みロック (Reader/Writer Locks)
このロックのペアは mutex に似ていますが、複数の実行ユニット (UE) が読み取りロックを所有することができる点と、書き込みロックがほかの書き込みとすべての読み取りを除外することができる点で異なります。通常、読み取り/書き込みロックは、ロックによって保護されるリソースへの読み取りが、書き込みよりもずっと頻繁に行われる場合に効果があります。
弱く順序付けられたメモリー (Weakly Ordered Memory)
強く順序付けられたメモリーの制約を緩和したものです。制約の緩和によりパフォーマンスは向上しますが、同期操作で問題が発生する可能性があります。その場合は、メモリーフェンスを使用することで順序を保つことができます。
デッドロックに似た並列処理エラーで、実行ユニット (UE) は完全にはブロックされず、トークンやバッファーを渡しますが、有効な処理は行われません。
オブジェクト群 (通常は各実行ユニット (UE) につき 1 つ) を受け取り、それらを 1 つの UE 上の 1 つのオブジェクトに結合する操作、またはそれらを 1 つに結合して各 UE にコピーする操作です。通常は、加算、最大値検索などの結合則を満たす操作を使用して値を結合します。
リファクタリングとは、外部動作を変更することなく内部構造を変更してプログラムを再構成するソフトウェア・エンジニアリング手法です。この再構成は、一連の小さな変更 ("リファクタリング" と呼ぶ) からなり、それぞれの変更を適用した後に "動作が変更されていないこと" を検証することができます。システムが完全に動作し、それぞれの変更後に動作を確認できるため、検知されない深刻な問題が発生する可能性を大幅に軽減します。インクリメンタルな並列化は、並列プログラミングに対するリファクタリングの応用と見なすことができます。「インクリメンタルな並列化」の説明もご覧ください。
リモート・プロシージャー・コール (Remote Procedure Call)
呼び出し元とは異なるアドレス空間 (つまり、別の実行ユニット) で呼び出されるプロシージャーです。多くの場合は、異なるマシンで呼び出されます。一般に、プロセス間通信や分散型クライアント/サーバー・コンピューティング環境でのリモートプロセスの起動で使用されます。
メッセージの送信、ディスク上の情報へのアクセス、命令の終了の待機などのリクエストの処理にかかる固定コストです。クラスター・コンピューティングでは、通常、通信媒体を介して空のメッセージを送信した場合にかかる時間 (送信ルーチンが呼び出された時点から、受信先で空のメッセージが受信されるまでの時間) です。小さなメッセージを大量に生成するプログラムはレイテンシーの影響を受けやすく、レイテンシーに束縛された (latency-bound) プログラムと呼ばれます。
それぞれの並列処理タスクにかかる時間がほぼ同じになるように、実行ユニット (UE) に処理を分散するプロセスを指します。ロード・バランシングには 2 つの主要な手法があります。静的ロード・バランシングでは、実行を開始する前に処理が分割されます。動的ロード・バランシングでは、実行中 (つまり、ランタイム) にロードが変更されます。
並列処理では、タスクは実行ユニット (UE) に割り当てられてから、実行を行うプロセシング要素 (PE) にマップされます。PE 群によって実行される計算に関連した総処理量を "ロード (負荷)" といいます。"ロードバランス (負荷分散)" とは PE 間のロードの分散方法を表します。効率的な並列プログラムでは、ロードがバランスよく分散され、それぞれの PE で計算にかかる時間はほぼ同じです。つまり、ロードバランスの良いプログラムでは、すべての PE は割り当てられた処理をほぼ同時に終了します。
複数の実行ユニット (UE) 間の相互作用を管理するためのメカニズムで、通常は共有リソースの制御により行われます。1 つまたはいくつかの UE がロックを所有する場合、そのロックで保護されたリソースへのアクセスを制御できます。ロックは、ハードウェア (「アトミック」を参照) でもソフトウェア (「セマフォー」を参照) でも実装できます。ロックは、条件変数からクリティカル・セクションまで、さまざまな種類の同期に使用されます。
論理型言語で並列化を行うための主な手法の 1 つです。ゴール A: B,C,D ("A は B と C と D によって導かれる") について考えてみましょう。ゴール A は 3 つのサブゴール B、C、D がすべて成功した場合のみ成功します。AND 並列化では、サブゴール B、C、D が並列に評価されます。
Beowulf クラスター (Beowulf Cluster)
Linux* オペレーティング・システムを実行する PC で構築されたクラスターです。1990 年代初めに Beowulf クラスターが構築された時点で、クラスターシステムはすでに実用化されていました。しかし、Beowulf が登場する前のクラスターは、UNIX* や VMS を実行する高価なシステムで構築されていました。Beowulf クラスターにより、クラスター・ハードウェアのコストが減少し、その結果、クラスター・コンピューティングは飛躍的に普及しました。
キャッシュ・コヒーレント NUMA。プロセシング要素のキャッシュにあるデータが、共通のメモリービューを共有する NUMA モデルです。「NUMA」の説明もご覧ください。
「分散共有メモリー」の説明を参照してください。
Explicitly Parallel Instruction Computer の略称。コンパイル時に、同時に実行する複数の命令をまとめてバンドルする命令アーキテクチャーのことです。この技術は、インテル® Itanium® アーキテクチャーで採用されています。
実行ユニット (UE) の調整を行うために一部の並列プログラミング環境で使用されるメカニズムです。Future 変数とは、最終的に非同期計算の結果を保持する特別な変数です。例えば、Java* の java.util.concurrent パッケージには、Future 変数を保持するための Future クラスがあります。
C++ から派生したオブジェクト指向言語ですが、C++ のいくつかの危険な言語機能は含まれていません。Java* は、並列性を表現する言語と標準ライブラリー・コンポーネントを備えている明示的な並列言語です。
Java* 仮想マシン (Java Virtual Machine)
Java* 仮想マシン (JVM) は抽象的なスタック型の計算マシンで、その命令セットは Java バイトコードと呼びます。通常、Java* プログラムは、Java* バイトコードを含むクラスファイルにコンパイルされます。JVM は、ハードウェアに関係なく、一貫した実行プラットフォームを提供することを目的としています。
「Java* 仮想マシン」の説明を参照してください。
並列プログラミングの協調言語 (Coordination Language) です。「タプル空間」の説明もご覧ください。
ローカルキャッシュを持つ共有メモリー・アーキテクチャーのキャッシュ・コヒーレンシー・プロトコルの 1 つです。各キャッシュラインは、次の 4 つの状態のいずれかにあります: 変更 (正しい値がそのキャッシュにだけ存在し、メモリーにある値からは変更されている)、排他 (正しい値がそのキャッシュにだけ存在し、メモリーにある値と同じである)、共有 (同じ値が複数のキャッシュに存在し、メモリーにある値と同じである)、無効 (キャッシュラインの値は無効である)。ほかのプロトコルでは、状態の数が多いか少ない場合があります。
Multiple Instruction Multiple Data の略称。フリンの分類によるコンピューター・アーキテクチャーのカテゴリーの 1 つです。MIMD システムでは、プロセシング要素 (PE) ごとに個別のデータの操作を行う個別の命令ストリームがあります。現代の並列システムの大半は MIMD アーキテクチャーを使用しています。
「メッセージ・パッシング・インターフェイス」の説明を参照してください。
「超並列プロセッサー」の説明を参照してください。
Non-Uniform Memory Access の略称。この用語は、レベルごとにアクセス時間の異なるメモリー階層を持つ共有メモリー型コンピューターを表すのに使用されます。メモリー位置からの距離によってアクセスにかかる時間が異なるのが特徴です。
ここで紹介する OpenMP* のサンプルコードは、SourceForge の Open MP Source Code Repository (英語) からダウンロードできます。
また、openmp.org (英語) の OpenMP* 仕様も参照してください。
上記の SourceForge の Web サイトから次のサンプルコードを利用できます。
- 有限差分で離散化したヘルムホルツ方程式をヤコビ反復法により解く方法
- 分子動力学シミュレーション
- 高速フーリエ変換 (FFT) - 分割統治アルゴリズムを使用して、オリジナル信号の偶数成分と奇数成分の変換の組み合わせとして計算します。入れ子になった並列処理を使用します。
- ベイリー法の 6 ステップによる 1 次元高速フーリエ変換
- 依存関係のあるループ
手法: スレッド・パイプラインの作成
- 2 次元密行列の LU 分解
- マンデルブロ集合 - モンテカルロ法を使用してマンデルブロ集合を計算します。
- OpenMP* を使用した円周率計算の並列実装 - 0 から 1 までの区間を一連の幅の狭い長方形に分割して、各長方形の中点を結んだ曲線の内部面積 y=4/(1+x*x) から円周率を計算します。積分値は総和により近似されます。
- OpenMP* を使用したクイックソートの並列実装 - 整数配列をソートします。 入れ子になった並列処理を使用します。
- ヤコビ法による熱方程式の 8 つの解法 - それぞれの解法では、級数 1 の 並列セクションの同期方法が異なります。
並列論理型言語の実行手法の 1 つで、複数の節を並列に評価します。例えば、2 つの節がある問題 A: B,C と A: E,F (それぞれ、"A は B と C によって導かれる" と "A は E と F によって導かれる") について考えてみましょう。ゴール A はサブゴール B と C の両方が成功した場合か、E と F の両方が成功した場合のみ成功します。2 つの節はいずれかが成功するまで並列に実行できます。「AND 並列化」の説明もご覧ください。
「プロセシング要素」の説明を参照してください。
Portable Operating System Interface。IEEE Computer Society の Portable Applications Standards Committee (PASC) - 移植性の高いアプリケーションのための標準規格に関する委員会 - によって定義された、オペレーティング・システム・インターフェイスの移植性を高めるための標準規格です。主に UNIX* や UNIX 系 (Linux* など) のオペレーティング・システムのインターフェイスの標準規格を表しますが、その他のオペレーティング・システムでも POSIX* 標準規格の一部に準拠しているものがあります。
POSIX* スレッドの略称。つまり、POSIX* 標準規格のスレッドの定義です。「POSIX*」の説明もご覧ください。
Parallel Virtual Machine (並列仮想マシン) の略称。並列コンピューティング向けのメッセージ・パッシング・ライブラリーです。PVM は、最初の移植可能なメッセージ・パッシング・プログラミング環境として、並列コンピューティング分野で広く利用され、並列コンピューティングの歴史において重要な役割を果たしました。現在では、多くが MPI に取って代わられています。
「リモート・プロシージャー・コール」の説明を参照してください。
Single Instruction Multiple Data の略称。フリンの分類によるコンピューター・アーキテクチャーのカテゴリーの 1 つです。SIMD システムでは、1 つの命令ストリームが個別のデータストリームを持つ複数のプロセッサーで同期的に実行されます。
Single Program Multiple Data (SPMD)
並列プログラム (特に MIMD コンピューター) では最も一般的な方法で、 1 つのプログラムを並列コンピューターのそれぞれのノードにロードします。プログラムの個々のコピーは別々に実行されるため (協調イベントは除く)、各ノードで実行される命令ストリームは全く違うものになります。どの実行パスが選択されるかは、ある程度ノード ID によって決定されます。
「対称型マルチプロセッサー」の説明を参照してください。
「同時マルチスレッディング」の説明を参照してください。
「Single Program Multiple Data」の説明を参照してください。
「実行ユニット」の説明を参照してください。
