

この記事は、インテル® デベロッパー・ゾーンに公開されている「New optimizations for X86 in upcoming GCC 5.0: PIC in 32 bit mode.」(https://software.intel.com/en-us/blogs/2014/12/26/new-optimizations-for-x86-in-upcoming-gcc-50-32bit-pic-mode) の日本語参考訳です。
パート 2: 32 ビットモードにおける位置独立コード (PIC) の改善
32 ビット・モードでの PIC は、Android* アプリケーションや Linux* ライブラリーなど他にも多くの製品のビルドに利用されています。そのためこのような利用ケースでの GCC のパフォーマンスは非常に重要です。
GCC 5.0 は、ベクトル化の適用が困難な暗号化、データ保護、データ圧縮やハッシュなど、ホットな整数演算ループを持つアプリケーションで、大幅なパフォーマンス向上 (最大 30%) を達成可能です。
GCC 4.9 では、EBX レジスターはグローバル・オフセット・テーブル (GOT) アドレスを格納するために予約されており、割り当てに利用できません。そのため 32 ビット・モードの PIC では、6 つのレジスターのみが利用できます (通常は 7 個): EAX、ECX、EDX、ESI、EDI そして EBP。割り当て可能なレジスターが不足すると、パフォーマンス低下の原因となります。また、特定の状況では EBP も予約され、パフォーマンスはさらに悪化する場合もあります。
GCC 5.0 では EBX が、レジスター割り当てに利用できるようになったため、7 つのレジスターがすべて割り当てできます。これは、レジスター不足に直面するホットな整数ループを持つアプリケーションのパフォーマンスを向上させます。以下は、整数ループ中でレジスター要求の高いストレステストを行うコードです。
テスト用のソース:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | int i, j, k; uint32 *in = a, *out = b;for (i = 0; i < 1024; i++) { for (k = 0; k < ST; k++) { uint32 s = 0; for (j = 0; j < LD; j++) s += (in[j] * c[j][k] + 1) >> j + 1; out[k] = s; } in += LD; out += ST; } |
ここで
- “c” は、定数行列:12345678
constbyte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1,1, 1, -1, -1, 1, 1, -1, -1,1, 1, 1, 1, -1, -1, -1, -1,-1, 1, -1, 1, -1, 1, -1, 1,-1, -1, 1, 1, -1, -1, 1, 1,-1, -1, -1, -1, 1, 1, 1, 1,-1, -1, -1, 1, 1, 1, -1, 1,1, -1, 1, 1, 1, -1, -1, -1}; - “in” と “out” ポインターは、グローバル配列 “a[1024 * LD]” と “b[1024 * ST]” を指します。
- “uint32” は unsigned int です。
- “LD” と “ST” マクロは、外部ループのロードとストア数に応じて定義します。
コンパイル・オプション “-Ofast -funroll-loops -fno-tree-vectorize –param max-completely-peeled-insns=200” に加え、Silvermont 向けには “-march=slm”、Haswell 向けには “-march=core-avx2” 、PIC モードには “-fPIC” と “-DST=7 -DLD={4, 5, 6, 7, 8}” を使用します。
“-fno-tree-vectorize” オプションは、ベクトル化を抑制し、xmm レジスターを利用できるようにします。
“–param max-completely-peeled-insns=200” オプションは、ピーリングの最大数を指定します。5.0 と 4.9 の振る舞いを同じにするには、引数 100 を指定します。
最初に、GCC 5.0 が GCC 4.9 に比べどれくらい高速であるかテストしてみましょう。
横軸は、ループ内のロードの数を示しています: LD。”LD” が大きいとレジスター要求が高くなります。
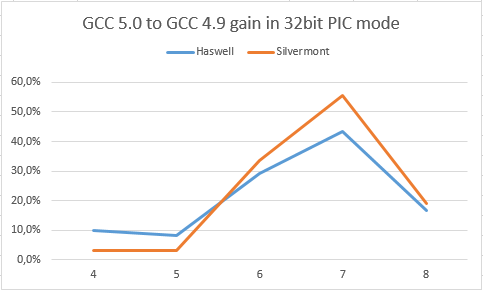
Silvermont✝ と Haswell✝ の両方で良い結果であることが分かります。このゲインが、EBX レジスターが利用できるようになったものか確かめるため、次の 2 つのグラフを見てみましょう。
以下のグラフでは、PIC モードを有効にしたことで、Silvermont✝ と Haswell✝ の両方で GCC 5.0 と GCC 4.9 のゲインが低下しています (高い値が良い)。
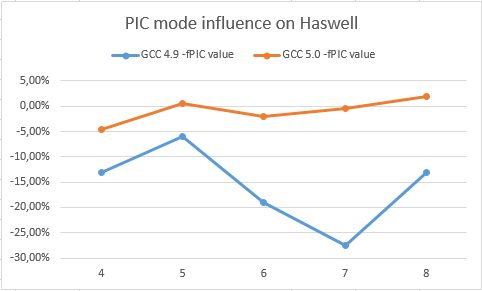
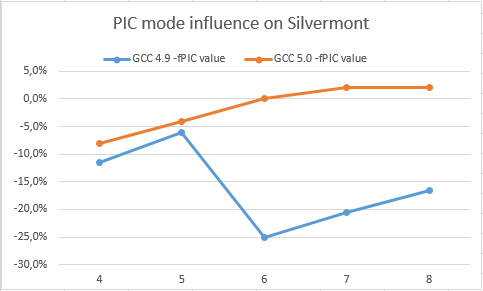
GCC 5.0 は、PIC モードでもそれほど低下していませんが、GCC 4.9 では Silvermont✝ と Haswell✝ の両方で低下が見てとれます。これは、GCC 5.0 で整数ループのパフォーマンスが改善されていることを意味します。また、開発者はアンロール、インライン展開、積極的な不変移動、コピー伝搬などの最適化を、より積極的に (レジスター要求の観点から) 試みることができます。
計測に使用したコンパイラーは以下で入手できます:
GCC 4.9: https://gcc.gnu.org/gcc-4.9
GCC 5.0 トランクビルドは、レビジョン 217914 です: https://gcc.gnu.org/viewcvs/gcc/trunk/?pathrev=218160
テスト用のソース: matrix.zip
https://software.intel.com/sites/default/files/managed/4c/59/matrix.zip
✝ 開発コード名
パート 1 は、こちらをご覧ください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください
