
この記事は、インテル® デベロッパー・ゾーンに公開されている「Intel® Graphics Performance Analyzers Assist Snow Simulation in Frostpunk*」(https://software.intel.com/en-us/articles/intel-graphics-performance-analyzers-assist-snow-simulation-in-frostpunk) の日本語参考訳です。
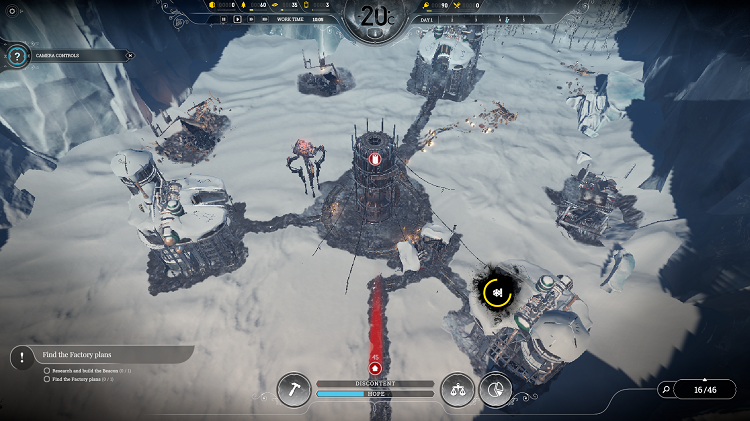
ポーランドのワルシャワが本拠地の 11 bit studios (英語) は、雪のシミュレーションとレンダリング・システムの設計と実装に細心の注意を払いました。社内の Liquid エンジンには、ダイナミックな天候の世界の外観と雰囲気を効率良くサポートするいくつかのカスタム地形およびシェーディング機能があります。この記事では、最初に雪のシミュレーションとレンダリングのいくつかの実装の詳細について簡単に説明します。そして、臨場感あふれるゲームプレイとストーリー展開に必要な雪の外観と動作を実現するため視覚的な忠実性を維持しつつ、インテル® グラフィックス・テクノロジー上で雪のレンダリングの GPU パフォーマンスを向上する 11 bit studios とインテルのコラボレーションを紹介します。
ゲームは、第 6 世代インテル® Core™ i7 プロセッサー (4 コア、8 スレッド) および Windows* 10 搭載のインテル® ネクスト・ユニット・オブ・コンピューティング・キット NUC6i7KYK (開発コード名 Skull Canyon、詳細) を使用して、インテル® Iris® Pro グラフィックス 580 向けに最適化されました。パフォーマンスの最適化に使用されたインテル® グラフィックス・パフォーマンス・アナライザー (インテル® GPA) は、こちらから無料でダウンロードできます。
11 bit studios の開発者の協力により、テストしたシナリオでは平均フレームレートが約 17FPS (約 58ms) から約 35FPS (約 29ms) に向上して、ゲームを非常に楽しくプレイできるようになりました。この記事では、雪のシミュレーションとレンダリング・システムについて詳しく説明し、ゲームの全体的なプレイに不可欠ないくつかの GPU の最適化を紹介します。
リアルな雪のシミュレーションが重要
『Frostpunk*』の凍てついた銀世界で雪は非常に重要な役割を果たします。プレーヤーは、地球に残された人類最後の街を、極寒と戦いながら統治します。雪は、熱源により一時的に遮られたり、街の住民の移動により溶けますが、常に降り続けます。『Frostpunk*』では、雪の計算シミュレーションとレンダリングの両方が完全に GPU 上で実行されます。GPU 上の雪の計算シミュレーションは、雪の初期化、融雪、降雪の 3 つのステージに分けられます。
雪の初期化
シミュレーションは、雪の高さマップと降雪マスクの 2 つの動的テクスチャーに依存します。降雪マスクは、建物の下、ヒートゾーン内、路上など、定義されたエリアでの降雪を防ぐのに使用されます (図 1)。ゲームの開始時に、雪の高さマップはゲームアセットからの入力データで初期化され、降雪マスクはクリアされます。良好な視覚的効果を得るため、雪の高さマップは R16F 形式を使用し、降雪マスクは R8G8 形式を使用します。R16F は 16 ビット浮動小数点で、雪の高さをより忠実に表現します。R8G8 は単純な雪のオン/オフであり、浮動小数点表現は不要です (降雪のオン/オフエリアを表現するだけなので、R8G8 でも十分すぎるくらいです)。

図 1. 雪のシミュレーションに使用されたテクスチャー。左は雪の高さマップ、右は (降雪しないエリアを示す) 降雪マスク。
どちらのテクスチャーも 1K です。雪の高さマップは R16 形式を使用し、降雪マスクは R8G8 形式を使用します。
融雪
ゲームを通して、雪を溶かすことができるいくつかの異なる種類のイベントがあります。これらの「融雪」イベントは、「メルトクワッド」のバッチ描画呼び出しにより比較的低コストで実装できます。メルトクワッドは、正または負の強度で加算ブレンドを使用して融雪をシミュレーションし、追加のテクスチャーと手続き型ノイズ関数に依存してさまざまなメルト効果を作成します。メルトクワッドは、降雪マスク・テクスチャーの更新にも使用されます。
- 住民またはオートマトンの移動。各住民とオートマトンのそれぞれの脚には、メルトクワッドがアタッチされており、サイズ、フォールオフ、ノイズ、抑制などのパラメーターをランダムなバリエーションで定義する追加のテクスチャーを使用します (図 2 と図 3)。
- 建物と道路の配置。それぞれの建物と道路にもメルトクワッドがアタッチされています。建設が始まると、建物の周囲の雪はすぐに溶けます (図 4)。これは、降雪マスクの赤チャネルに保持されます。
- 蒸気ジェネレーターの処理。熱源にもメルトクワッドがアタッチされていますが、熱源の周囲の雪は建物や道路よりもゆっくりと動的に溶けます (図 5)。これは、降雪マスクの緑チャネルに保持されます。


図 2. 住民の移動による融雪の例。
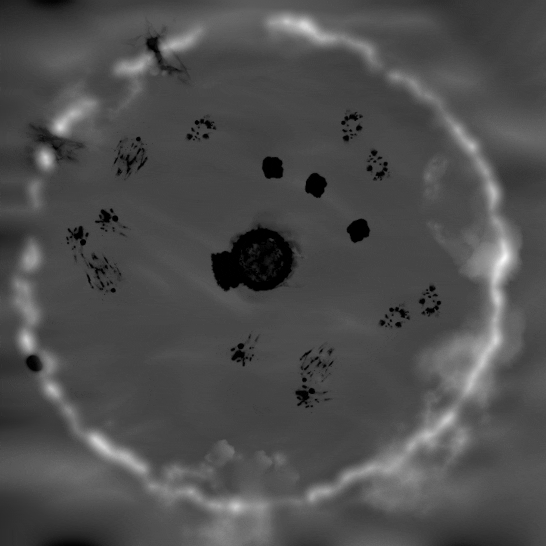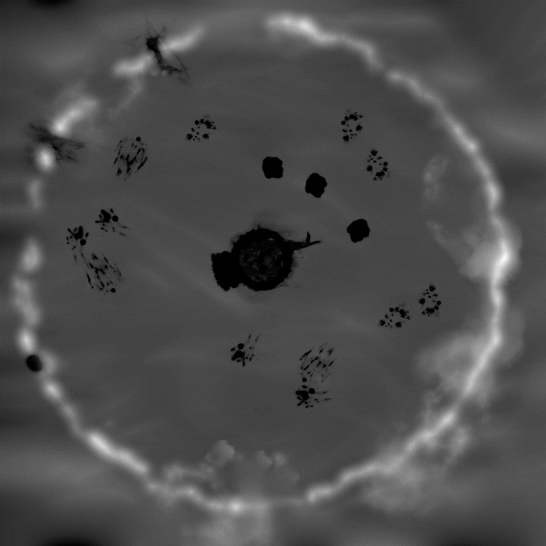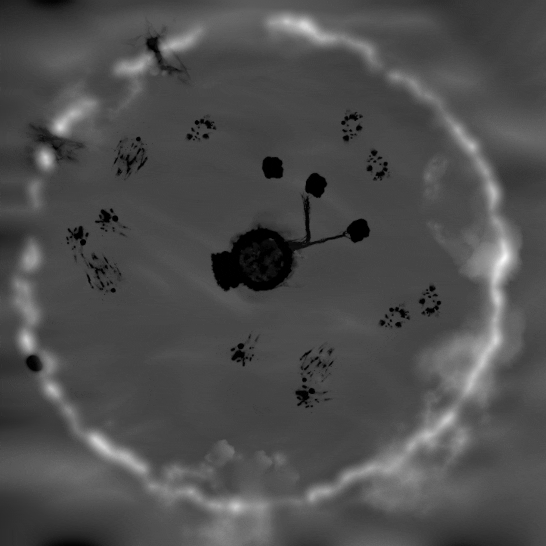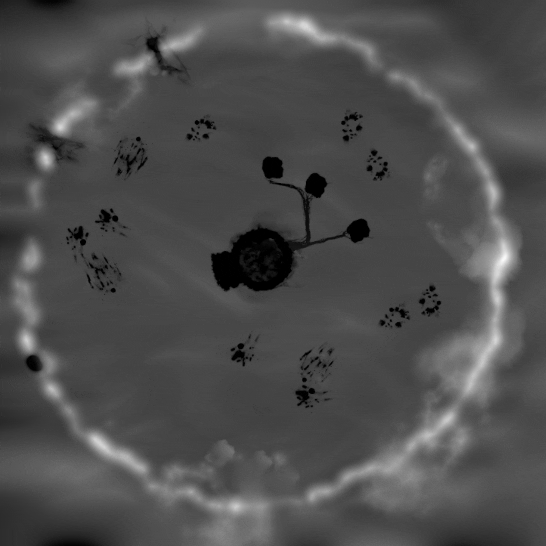
![[入力アセンブラー] ビューのアニメーション](https://www.isus.jp/wp-content/uploads/image/webops12595-fig-3-b.gif)
図 3. 住民の移動のシミュレーション。融雪により変化する雪の高さマップ (左) と
バッチ化された住民のメルトクワッドの描画呼び出しの [入力アセンブラー] ビューのアニメーション (右)。


図 4. 建物のメルトクワッドで使用されたテクスチャーの例。診療所の建物に使用されたテクスチャー (左) と
一般的な建物に使用されたテクスチャー・アトラス (右)。

図 5. 蒸気ジェネレーターとオートマトンによる融雪の例。
降雪
雪は絶えず降っており、融雪エリアにも降り積もります。この処理は比較的簡単で、オリジナルの初期化値に達するまで雪の高さマップの値を常に増加させます。動的な高さマップは、ゲームアセットからのデータ (アーティストによって指定されたオリジナルの雪の高さマップ) で初期化されます。これは開始点であり、降雪の最終目標でもあります。降雪ピクセルシェーダーは、最初に新しい雪を適用してから、雪の高さマップの値が適切な範囲内 (0.0 よりも大きく、アセットから読み取られた最大値よりも小さい) になるように維持します。視覚効果を向上するため、追加のテクスチャーとパラメーターを使用して不均一な雪の成長を実現します。降雪マスクは、路面、建物の周囲、(蒸気ジェネレーターによって作成された) アクティブなヒートゾーンなど、降雪できないエリアで雪が成長するのを防ぐために使用されます。
メッシュとデカールでレンダリング・システムを作成
11 bit studios の Liquid エンジンの G バッファーパスは、ソリッドメッシュ、ソリッド・ソフトネス・メッシュ、およびデカールのレンダリングの 3 つのステージで構成されます。ソリッド・ソフトネス・メッシュは、前のステージのソリッドメッシュとのスムーズなレンダリングをサポートするメッシュです。雪の地形は、雪と環境オブジェクトのスムーズなブレンドを実現するため、ソフトネスメッシュを使用してレンダリングされます。
雪システムの動的な地形は、GPU によって完全に制御されます。ジオメトリーは N x N の地形タイルで構成されます。地形タイルは、ジオメトリーのインスタンス化を利用してレンダリングされます (図 6)。
|
|
図 6. 雪システムの地形タイル構造。 | |


CPU 錐台カリングをサポートするため、地形全体が D x D エリアに分割されます (図 7)。

図 7. CPU 錐台カリングのための追加の地形細分割。緑の線は錐台カリングに使用される細分割エリアを視覚化したもの。
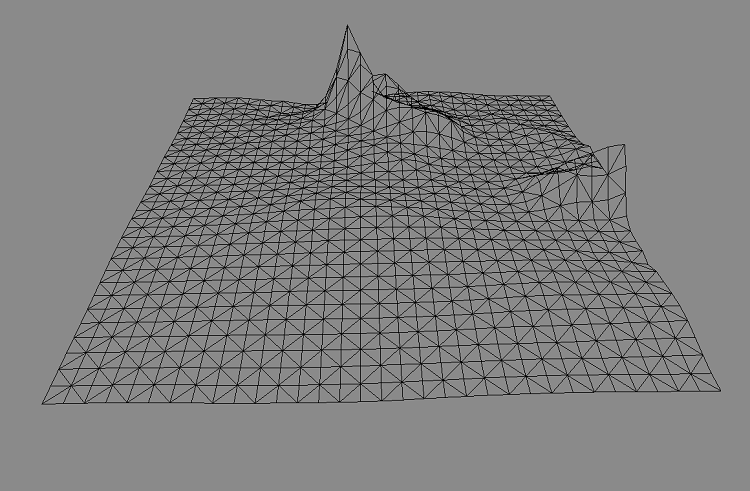
各地形タイルは、テセレーション・シェーダーでテセレーションされた M x M のテセレーション・パッチで構成されます。地形タイルの数とテセレーション・パッチの密度は、どちらも地形プロパティーで設定できます (図 8)。
|
|
図 8. 選択された地形エリアのテセレーション・パッチ構造。 | |

地形システムは、次のテクスチャーのコレクションに依存します。
- 雪の高さマップ。雪のシミュレーションによって動的に変更される高さマップは、ジオメトリーの変位と法線の計算の地形ディスプレイスメント・マップとして使用されます。
- マテリアル・レイヤー・マップ。雪の地面にテクスチャー・スプラッティングを適用するのに使用されます。
- マテリアル・ブレンド・マップ。各ペイントマテリアルの重みを格納するのに使用されます。
- マテリアル・テクスチャー配列。地形ペイントのマテリアルを格納するのに使用されます。
- 密度マップ。シェーダーでテセレーションできる地形エリアに関する情報を格納するのに使用されます。
- ソフトネスマップ。ソリッド・オブジェクトとブレンドできる地形エリアに関する情報を格納するのに使用されます。
- ディテールマップ。追加の法線/粗さ/メタル質マップを高解像度で格納するのに使用されます。このテクスチャーは、性質上平らな雪のオブジェクトにとって特に重要です。
頂点シェーダーは、平坦な地形パッチに基本的な変換を適用するのに使用されます。ハルシェーダーとドメインシェーダーは、密度マップと LOD 距離評価に基づいてアダプティブ・テセレーションを実行します。また、地形の変位を適用して、地形パッチの GPU カリングを実行します。ピクセルシェーダーは、ジオメトリーの法線の生成、マテリアルの適用とブレンドなど、多くのことを行います。ピクセルシェーダーで法線ベクトルの計算を行うと、ドメインシェーダーで計算を実行するよりもフレーム時間コストが大幅に上昇しますが、驚くほどの視覚効果が得られ、低解像度の入力ジオメトリーで詳細な地形を実現できます (図 9)。
|
|
|
|
図 9. 雪のレンダリング結果の例アルベド (左上)、法線マップ (右上)、最終レンダリング結果 (左下)、 | |




インテル® GPA を利用したパフォーマンス解析
ほとんどのパフォーマンス解析は、インテル® GPA で行いました。インテル® GPA は、ゲームの単一のフレームをキャプチャーおよび再生するツールを含む、グラフィック・アプリケーション向けのパフォーマンス解析ツールスイートで、統合 GPU とディスクリート GPU のどちらでも利用できます。インテル® インテグレーテッド・グラフィックスで利用すると、インテル® GPA はボトルネック解析に非常に有用な詳細なハードウェア・メトリックのコレクションを提供します。ここでは、最適化の説明を通じて、インテル® GPA のいくつかの機能を紹介します (各機能の詳細は、インテル® GPA のユーザーガイドを参照してください)。
『Frostpunk*』の 1 つのフレームを見てみましょう。最初に気付くことは、雪のシミュレーションを行う最初の描画呼び出しに、開発コード名 Skull Canyon の GPU で約 3ms もかかっています。

図 10. インテル® GPA の出力例。フレームのすべての描画呼び出しが表示され、各バーの高さはそれぞれの
描画呼び出しの実行時間を表している。オレンジ色のバーは『Frostpunk*』の融雪と降雪の描画呼び出し。
雪のシミュレーションが実際に何を行っており、このハードウェアでの達成目標が少なくとも 30FPS であることを考慮すると、この描画呼び出しには時間がかかりすぎています。
以下は、この描画呼び出しに使用されたピクセルシェーダーの DirectX* バイトコードです。
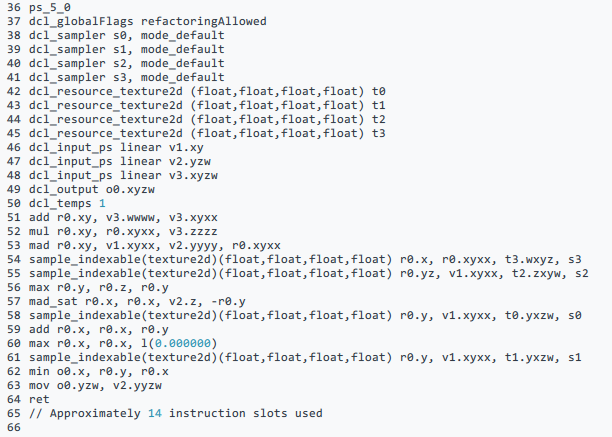
このシェーダーは比較的単純であることが分かります。4 つのサンプル命令とその間にいくつかの単純な演算があります。なぜこのような単純なシェーダーの実行に 3ms もかかっているのでしょうか? インテル® GPA には、詳しく調査する際に役立ついくつかの機能があります (図 11)。
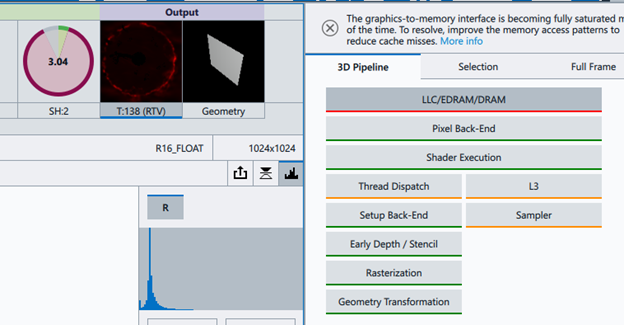
図 11. インテル® GPA の出力例。円グラフで示されたシェーダー実行の特性 (左) とインテル® GPA のボトルネック・ビュー (右)。
インテル® アーキテクチャーでは、並列 GPU コアを実行 (EU) と呼びます。図 11 の左上にある円グラフは、この描画呼び出しを実行中の EU の使用状況を示しています。
- 緑は、アクティブ時間 (EU が実際にシェーダー命令を実行していた時間) を表します。
- 赤は、ストール時間 (EU が何かを待機していた時間) を表します。
- 灰色は、アイドル時間 (EU でシェーダーが全く実行していなかった時間) を表します。
この雪のシミュレーションの描画では、EU は 3ms の 85% をストールに費やしています。
図 11 の右にあるパイプライン・フローは、ハードウェア・メトリックとヒューリスティックを使用して、ボトルネックの可能性がある場所を示しています。[Selection] タブと [Full Frame] タブでは、パイプライン・ステージに基づいて並べ替えられた、評価に使用された未処理の値を確認できます。[Shader Execution] ボックスは緑で、[LLC/EDRAM/DRAM] は赤であることから、ボトルネックはピクセルシェーダーの 4 つのサンプル命令のメモリーの読み取り/書き込みに関連している可能性が高いことが分かります。原因と必要な最適化を特定するには、GPU とシステム・アーキテクチャーの理解を深める必要があります。
インテルの最適化とメモリー・アーキテクチャー
インテル® プロセッサー・グラフィックスには、専用のビデオメモリーがありません。代わりに、DRAM メモリーが GPU と CPU を含むシステム全体で共有される統合メモリーの概念を実装しています。
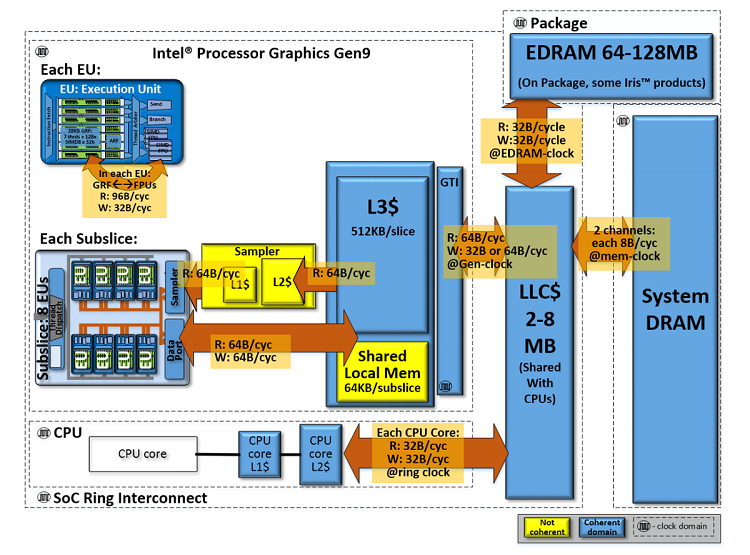
図 12. SoC チップレベルのメモリー階層とインテル® プロセッサー・グラフィックス Gen9 の計算アーキテクチャーの理論ピーク帯域幅。
インテル® プロセッサー・グラフィックスは、各テクスチャー・サンプラー・ユニットが独自のローカルキャッシュ階層を持ち、すべての GPU EU コアとサンプラーで共有される L3 キャッシュがある、キャッシュ階層を備えています。L3 キャッシュにないデータが必要な場合、GPU はデータを取得するため共有システムメモリーへのアクセスを要求します。L3 の下位には、CPU と共有される最終レベルキャッシュメモリー (LLC)、そしてシステム DRAM があります (一部の製品では、LLC と DRAM の間に 64 ~ 128MB の EDRAM があります)。
EU がテクスチャー・リソースをサンプリングすると何が起こるのでしょうか? GPU の並列性と一般的な空間の局所性により、サンプラーは 1 テクセル分のデータだけをフェッチしません。データを含むキャッシュライン全体 (インテル® GPU の場合 64 バイト) をフェッチします。そのため、R16F の雪の高さマップをサンプリングすると、テクスチャー・フェッチは隣接する 32 のテクセルのデータもフェッチします。多くのピクセルシェーダーが並列に実行しており、それぞれが同じテクスチャーのデータを要求するため、必要なデータがすでにキャッシュに存在していることを願うしかありません。
インテル® GPA に戻りましょう。図 13 は、この描画呼び出しに関するいくつかの詳細なメモリーメトリックです。データは 2 つの列に表示されます。インテル® GPA ではさまざまな実験を行うことが可能で、左側の列は実験を適用後の測定値を表し、右側の列はオリジナルの値を表します。このケースでは、何も変更していないため、2 つの列のデータは同じです。
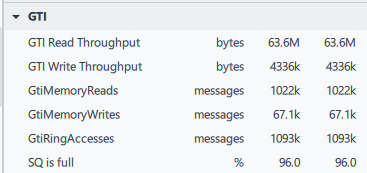
図 13. インテル® GPA の雪のシミュレーションの描画呼び出しに関する詳細なメモリーメトリック。
GTI は、インテル® グラフィックスがシステムメモリーへのアクセスに使用するインターフェイスの名前です。GTI Read Throughput (GTI 読み取りスループット) は、この描画呼び出しのためだけに 63MB を超えるデータが GPU 外部から読み取られていること (DRAM または LLC から GTI へのストリーミング) を示しており、調査する必要があります。おそらく、実行ユニットが要求するデータがローカル・サンプラー・キャッシュまたは GPU の L3 キャッシュに存在しないため、GTI により GPU の外部からデータがフェッチされるのを待機して、多くの時間がストールに費やされていると考えられます。
図 14 のサンプラー・キャッシュ・メトリックは約 170 万回のキャッシュミスを示しており、このことからもこれが確認できます。
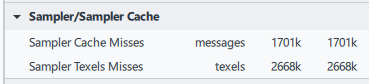
図 14. インテル® GPA のサンプラー・キャッシュ・メトリック。
効率良いキャッシュ階層で一度に 32 の隣接するテクセルをフェッチしているのに、どうしてキャッシュミスの回数がこれほど大きくなるのでしょうか? 1 つの可能性として、サンプリングするテクスチャーが非常に大きい場合、相対 UV は実際にはかなり離れた位置にあるテクセルを指しており、各キャッシュラインには有用なデータがわずかしか含まれていないことが考えられます。このような場合、サンプラーキャッシュと L3 キャッシュは、隣接する未使用のデータで不必要に一杯になってしまいます。
サンプリングされた雪のシミュレーションのテクスチャーの 1 つは 4K で、その他のテクスチャーはそれぞれ 1K でした。分析結果から、この大きなテクスチャーの周波数は、シェーダーのサンプリング周波数に対して高すぎると推測されます。インテルのチームは、この情報とこの描画がハードウェア上でいかに高価であるかを 11 bit studios に伝えました。そして、11 bit studios はすぐに 4K テクスチャーを 1K に変更しました。図 15 と 16 は、変更後の描画の GTI メトリックとサンプラー・キャッシュ・メトリックです。この変更は、最終的なイメージにそれほど影響しませんでした。
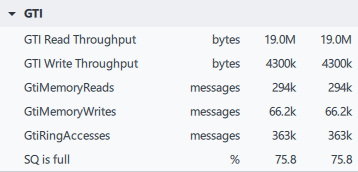
図 15. 11 bit studios により 1K テクスチャーへ変更後のインテル® GPA の
雪のシミュレーションの描画呼び出しに関する詳細なメモリーメトリック。
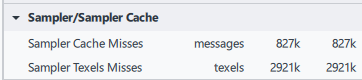
図 16. 11 bit studios により 1K テクスチャーへ変更後の
インテル® GPA のサンプラー・キャッシュ・メトリック。
GTI 読み取りスループットは 63M から 18M に減少しました。GTI によるメモリー読み取りは 1/3 に減り、キャッシュミスも 1/2 になり、合計フレーム時間が 2.4ms 短縮されました。
キャッシュ効率を改善後、雪のシミュレーションのボトルネックは [Thread Dispatch] に変わり、[Sampler] ユニットも注意が必要になりました (図 17)。インテル® GPA は、シェーダーロジックが非効率的である可能性を示唆しており、これはシェーダースレッドのペイロード (レジスターの使用など) を軽減することで改善できます。さまざまなボトルネックに関する詳細は、『インテル® プロセッサー・グラフィックス Gen9 向けグラフィックス API パフォーマンス・ガイド』 を参照してください (「関連情報」セクションにリンクがあります)。
このフィードバックを 11 bit studios に提供したところ、彼らはいくつかの追加の最適化を適用しました。
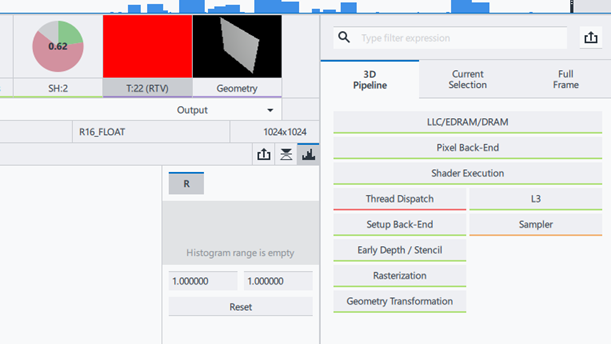
図 17. [Thread Dispatch] と [Sampler] のパイプライン・ボトルネック。
追加の最適化
雪のシミュレーションは、動的な雪の高さマップを直接操作しないように変更され、代わりに、単一の動的な R8 形式の雪のディスプレイスメント・マスク・テクスチャーを出力します。このテクスチャーは、初期化されたディスプレイスメント・データを含む静的な高さマップとともに雪の地形シェーダーにバインドされ、これらを乗算して最終的な雪の高さの値を計算します。
これにより、雪のシミュレーションの実行に必要なサンプルの総数が 4 から 2 に減り、降雪の計算時にクランプ操作を行う必要もなくなりました。その結果、この描画におけるサンプラーの負荷が大幅に軽減されました。
雪のシミュレーションのテクスチャー形式を変更したことで、ゲームの保存とタイムラプス・スナップショットのサイズも軽減されました。
さらに、降雪アルゴリズムは、高さマップ全体ではなく、タイルを操作するように再設計されました。エリア全体が N x N タイルに分割され、降雪はラウンドロビン方式でフレームごとに 1 つのタイルにのみ適用されます。つまり、1 秒間に 30 回マップ全体の雪を更新する代わりに、各フレームで 1 つのタイルのみが更新されます。そして、雪の計算シミュレーションをレンダリングから分離しました。これは、降雪の速度が遅く、マップ全体を 1 秒間に 30 回更新するか、1 秒間に 1 回更新するかは問題ではなかったため可能でした。この変更によって、この描画呼び出しの全体的なパフォーマンスが劇的に向上しました。また、最低品質のプロファイルに手続き型ノイズ関数を適用しないようにすることで降雪シェーダーが簡素化され、これにより別のサンプリング命令が削除されましたこれらの組み合わせにより、降雪描画のフレームごとのコストは、実質的に無視できる約 17us となりました。ゲームがマップ全体に対してこのような GPU シミュレーションを行っている場合、同様の方法で更新頻度を減らしてみる価値があるでしょう。
最後に、11 bit studios は、雪のエリアが (0, 1, 0) の法線ベクトルで平坦であると仮定して、雪のレンダリング・ピクセル・シェーダーを簡素化し、高価な法線ベクトルの計算を回避しました。法線マップで地形詳細マップを使用すると、これらの設定で優れたパフォーマンスを達成しつつ、満足のいく視覚効果が得られます。
まとめ
完成したゲームをインテル® Iris® Pro グラフィックス 580 搭載のインテル® ネクスト・ユニット・オブ・コンピューティング・キット NUC6i7KYK で実行したスクリーンショットがこちらです。
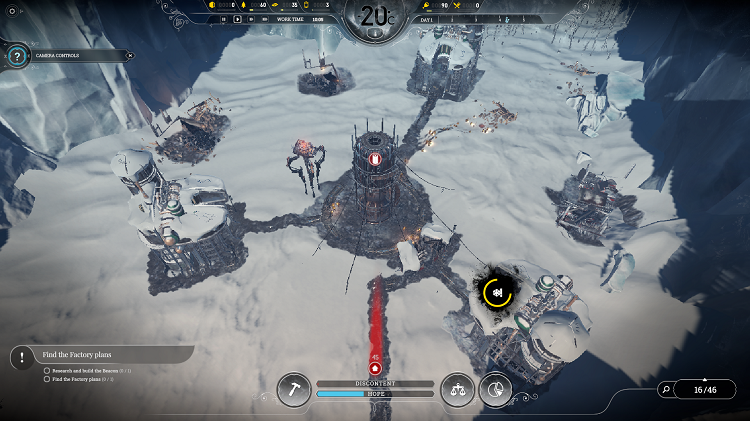
図 18. インテル® ネクスト・ユニット・オブ・コンピューティング・キット NUC6i7KYK で実行中のゲームのスクリーンショット。
雪システムの最適化は、11 bit studios が『Frostpunk*』に対して行ったパフォーマンス向上の一例です。スクリーンショットに示すように、これは高い視覚効果品質、特に素晴らしい雪の外観を維持したまま達成されました。
まだインテル® GPA でコードの最適化とパフォーマンス・ベンチマークの強化を行っていない場合、インテル® GPA のさまざまなツールを利用してスピードアップに取り組んでみてください。この記事で紹介したように、『Frostpunk*』はインテル® GPA ツールキットを活用することで大きなメリットが得られました。実際にご自身で試してみて、素晴らしい雪をご覧になることをお勧めします。
謝辞
まず第一に、11 bit studios の皆さんの多大な協力と、この記事を共同執筆してくれた Szymon に謝意を表します。また、この記事の公開に協力してくれたレビューアーの皆さんにも感謝します: Adam Lake、Stephen Junkins、Jefferson Montgomery、Geoffrey Douglas、および Dietmar Souch。
関連情報 (英語)
- 計算アーキテクチャー
https://software.intel.com/sites/default/files/managed/c5/9a/The-Compute-Architecture-of-Intel-Processor-Graphics-Gen9-v1d0.pdf - インテル® プロセッサー・グラフィックス Gen 9 向けグラフィックス API パフォーマンス・ガイド
https://software.intel.com/en-us/documentation/graphics-api-performance-guide-for-intel-processor-graphics-gen9 - Steam* の Frostpunk* のページ
- Frostpunk*
- Frostpunk の Twitter* アカウント
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
