

この記事は、インテル® デベロッパー・ゾーンに公開されている「Direct3D 12 Overview Part 8: CPU Parallelism」(https://software.intel.com/en-us/blogs/2014/09/05/direct3d-12-overview-part-8-cpu-parallelism) の日本語参考訳です。
パート 7 では、ダイナミック・ヒープについて触れ、それがどのように CPU の並列性に役立つか説明しました。それでは、これまで紹介した D3D 12 の機能を使用して、”コンソール API の効率とパフォーマンス” にとって重要な、真にマルチスレッド化された PC 向けゲームを作成する方法を見ていきましょう。D3D 12 は、複数の並列タスクを可能にします。コマンドリストとバンドルは、並列にコマンドを生成し実行することを可能にします。バンドルは、フレーム内もしくはフレームにまたがった複数のコマンドリストで、頻繁に繰り返されるコマンドの記録と実行を可能にします。コマンドリストは、複数のスレッド間で生成することができ、その後 GPU で実行するためコマンドキューへ送られます。最終的に、永続的にマップされたバッファーを使用して、開発者は並列にダイナミック・データを生成することができます。D3D 12 と WDDM 2.0 は並列処理向けに設計され、開発者が並列性を実装するためのそれに従うということです。D3D 12 は、以前のバージョンの D3D における制約を無くし、開発者が理解するどのような方法ででもゲームやエンジンを並列化することを可能にします。
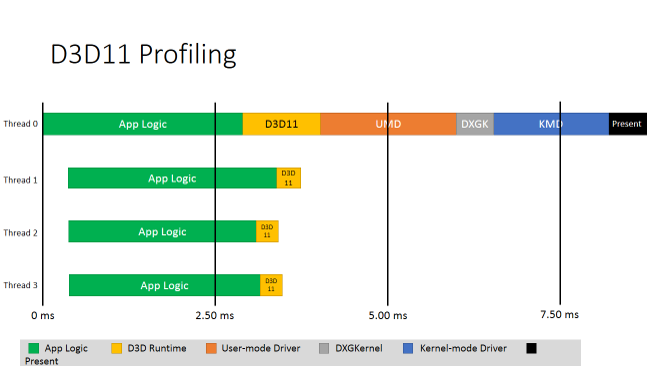
上図は、D3D 11 における一般的なゲームのワークロードを示しています。App Logic (アプリケーション・ロジック)、D3D 11 ランタイム、UMD、DXGKernel、KMD、そして Present が、4 つのスレッドで CPU を使用しているのが分かります。スレッド 0 が、すべての重い負荷を処理していることが見てとれます。スレッド 1-3 は、アプリケーション・ロジックと描画コマンドを生成する D3D 11 ランタイム以外の処理を行っていません。D3D 11 の設計により、ユーザーモードのドライバーはこれらのスレッド上でコマンドを生成していません。
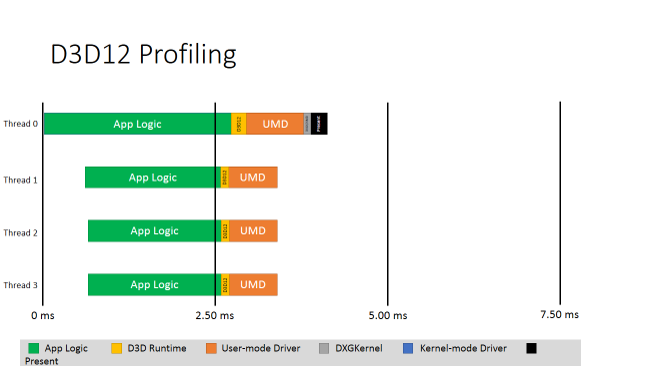
では、同じワークロードで D3D 12 の処理を見てみましょう。前述の図と同様に、App Logic (アプリケーション・ロジック)、D3D 11 ランタイム、UMD、DXGKernel、KMD、そして Present が、4 つのスレッドで CPU を使用しているのが分かります。しかし、D3D 12 の最適化によって、ワークは 4 つのスレッドに均等に分割されています。そしてこのコマンド生成のおかげで、D3D ランタイムが並列に動作していることが分かります。WDDM 2.0 におけるカーネル最適化により、カーネルのオーバーヘッドは劇的に減少しました。UMD は、スレッド 0 だけでなくすべてのスレッド上で動作し、並列にコマンドを生成しているのが分かります。そして、バンドルは D3D 11 の冗長な状態変更ロジックを置き換え、アプリケーション・ロジックの時間を短縮します。
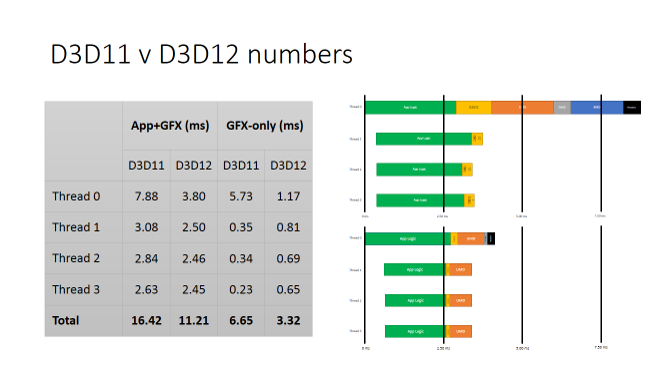
上図で 2 つの結果を比較しています。D3D 12 おける真の並列性では、スレッド 0 とスレッド 1-3 が比較的均等に CPU を使用しています。GFX のみに注目すると、スレッド 1-3 はより多くのワークを処理していることが分かります。また、スレッド 0 のワークロードが軽減され、新しいランタイムとドライバーは効率的で CPU の使用率を 50% 以下に抑えます。アプリケーションと GFX を見ると、ワークはスレッド間で均等に分割され CPU の使用率を 32% 以下に抑えています。
D3D 12 の新機能の概要をまとめました。CPU の効率と CPU のスケーラビリティーが達成されています。D3D 12 は、開発者にメモリー使用量の制御とライフタイムの再現性を提供し、CPU の並列性を高めます。D3D 12 を通じて、効率の向上とパフォーマンスのためより少ない階層の API とドライバーにより、開発者は “ハードウェアに近づく” ことができます。
図とコード例は、BUILD 2014 のプレゼンテーションから抜粋しました。マイクロソフトの D3D 開発リードである Max McCullen によるプレゼンテーションから抜粋したものです。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
