

この記事は、インテル® デベロッパー・ゾーンに公開されている「Direct3D 12 Overview Part 5: Bundles」(https://software.intel.com/en-us/blogs/2014/08/14/direct3d-12-overview-part-5-bundles) の日本語参考訳です。
D3D 12 における新たしい描画コンテキストについては、説明を終えたと思います。これまで、D3D 12 がどのように ‘ハードウェアに近い’ 制御をゲームに与えるか、その方法を見てきました。この記事の最後では、記述子ヒープとテーブルがどのようにバインドポイントを入れ替え、より効率良い描画コマンドパイプラインを作成する方法について説明します。さらに、D3D 12 が、API チャーンを削除もしくは合理化するために行うことがあります。API にはパフォーマンスを低下させるさらなるオーバーヘッドがあり、CPU を効率良く使用する多くの方法があります。コマンドシーケンスはどうでしょうか ?リピート・シーケンスがどれくらいあって、より効率良く行うにはどうすればいいでしょうか ?
冗長な描画コマンド:
フレーム間の描画コマンドを観察し、Microsoft の D3D 開発チームは、特定のパターンだけでなく可能性を見つけました。最近のゲームには、90-95% の驚異的な一貫性があります。フレーム全体のコマンド・シーケンスを見ると、5-10% のみが削除もしくは追加されていることが分かります。残りはフレーム間で再利用され、CPU はフレーム間で 90-95% もの時間を同じコマンド・シーケンスの繰り返しに費やしています。CPU は、大部分のサイクルを同じことの繰り返しに費やしているように見えます。これはどのように効率化できるでしょう ?なぜ D3D は、これまでこれに取り組んでいないのでしょう?Microsoft 社の D3D 開発チームのリードである Max McCullen は、BUILD 2014 で次のように述べています。
“適合性と信頼性の両方の面からコマンドを記録する方法を構築することは非常に困難です。そのため、複数の異なるドライバー上で複数の異なる GPU において同じように動作し、同時にそれらが効率的であるか確認します。”
それらは、信頼性が高く、高速である必要があります。ゲームは、個別のコマンドとして実行された場合、可能な限り迅速に記録されたコマンド・シーケンスを実行する必要があります。何が変わったのでしょう ?D3D が変わりました。新しい PSO では、記述子ヒープとテーブルに記録して再生するために必要なコマンドが大幅に簡素化されます。
バンドル:
バンドルは、一度記録され、複数回再利用される小さなコマンドリストです。それらは、フレームにまたがって、もしくは単独のフレームで再利用でき、再利用に制限はありません。バンドルは、任意のスレッドで生成し、回数無制限で利用することができます。しかし、バンドルは PSO 状態に拘束されません。バンドルが異なるバインドで再実行され、ゲームの結果が異なる場合、PSO が記述子テーブルを更新できることを意味します。Excel の表計算内の数式のように、数学的には常に同じですが、結果はソースデータによって異なります。ドライバーがバンドルを効率良く実装するには、いくつかの制限があります。明確に描画ターゲットを変更するコマンドはありませんが、記録して再生することが可能なコマンドはまだかなり存在します。
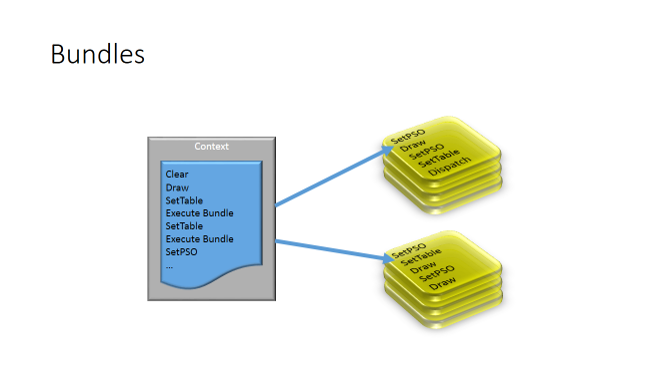
上記の図の左側は、描画コンテキストのサンプルであり、CPU によって生成され、実行のため GPU に渡される一連のコマンドです。右側には、再利用のため異なるスレッド上にあるコマンド・シーケンスの記録を含む 2 つのバンドルがあります。GPU がコマンドを実行すると、それは最終的に実行バンドル・コマンドになります。その後、記録されたバンドルを再生します。終了するとコマンド・シーケンスに戻り、継続して異なる実行バンドル・コマンドを探します。第 2 のバンドルは、継続する前に読み込まれ再生されます。これは、バンドルがどのように記録され、GPU 上で繰り返し同じコマンドが発行されるかを説明する例です。
コードの効率:
GPU の制御フローを見てきましたが、ここではバンドルがどのようにコードを簡単にするか説明します。
コード例 (バンドルなし):
ここでは、パイプライン状態と記述子テーブルを設定するセットアップ・ステージがあります。次に 2 つのオブジェクトを描画します。どちらも定数のみが異なる、同じコマンド・シーケンスを使用します。これは、典型的な D3D 11 とそれ以前のコードです。
1 2 3 4 5 | // SetuppContext->SetPipelineState(pPSO);pContext->SetRenderTargetViewTable(0, 1, FALSE, 0);pContext->SetVertexBufferTable(0, 1);pContext->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST); |
1 2 3 4 5 6 | // Draw 1pContext->SetConstantBufferViewTable(D3D12_SHADER_STAGE_PIXEL, 0, 1);pContext->SetShaderResourceViewTable(D3D12_SHADER_STAGE_PIXEL, 0, 1);pContext->DrawInstanced(6, 1, 0, 0);pContext->SetShaderResourceViewTable(D3D12_SHADER_STAGE_PIXEL, 1, 1);pContext->DrawInstanced(6, 1, 6, 0); |
1 2 3 4 5 6 | // Draw 2pContext->SetConstantBufferViewTable(D3D12_SHADER_STAGE_PIXEL, 1, 1);pContext->SetShaderResourceViewTable(D3D12_SHADER_STAGE_PIXEL, 0, 1);pContext->DrawInstanced(6, 1, 0, 0);pContext->SetShaderResourceViewTable(D3D12_SHADER_STAGE_PIXEL, 1, 1);pContext->DrawInstanced(6, 1, 6, 0); |
コード例 (バンドルあり):
次にバンドルを使用した同じコマンド・シーケンスを見てみましょう。最初の呼び出しはバンドルを作成しますが、これは任意のスレッドで行われる可能性があります。次のステージでコマンド・シーケンスが記録されます。これは、前述の例と同じコマンドです。
1 2 | // Create bundlepDevice->CreateCommandList(D3D12_COMMAND_LIST_TYPE_BUNDLE, pBundleAllocator, pPSO, pDescriptorHeap, &pBundle); |
1 2 3 4 5 6 7 | // Record commandspBundle->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST);pBundle->SetShaderResourceViewTable(D3D12_SHADER_STAGE_PIXEL, 0, 1);pBundle->DrawInstanced(6, 1, 0, 0);pBundle->SetShaderResourceViewTable(D3D12_SHADER_STAGE_PIXEL, 1, 1);pBundle->DrawInstanced(6, 1, 6, 0);pBundle->Close(); |
上記のコード例は、バンドルを使用しないコードを同じことを行っています。ここでは、同じタスクを実行するのに必要な呼び出し数を大幅に減らす方法を見ることができます。GPU はまだ同じコマンドを実行し、同じ結果を得ていますが、より効率良くなっています。
この記事では、D3D 12 がバンドル、記述子ヒープ、テーブル、そして PSO を利用することで、CPU の効率を改善する方法を述べました。ゲームにさらに制御が与えられ、ゲームとハードウェアにあるレイヤーはより少なくなります。以降は、D3D 開発チームが D3D 12 で並列性を高めるため何に取り組んでいるか説明します。重要なコンポーネントは、”コンソール API の効率とパフォーマンス” です。
次のパート 6 では、コマンドリストについて説明します。
図とコード例は、BUILD 2014 のプレゼンテーションから抜粋しました。マイクロソフトの D3D 開発リードである Max McCullen によるプレゼンテーションから抜粋したものです。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
