
この記事は、インテル® デベロッパー・ゾーンに公開されている「Accelerating Deep Learning Based Large-Scale Inverse Kinematics with Intel® Distribution of OpenVINO™ Toolkit」(https://software.intel.com/en-us/articles/accelerating-deep-learning-based-large-scale-inverse-kinematics-with-intel-distribution-of) の日本語参考訳です。
はじめに
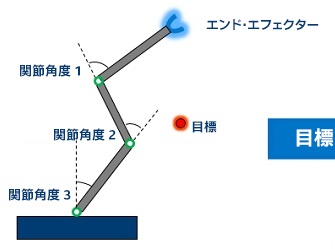
逆運動学 (IK) テクノロジーは、ロボット工学分野で開始されたテクノロジーで、特定の自由度でロボットアーム (エンド・エフェクター) を目標位置に移動する関節角度の算定に用いられます (図 1)。IK テクノロジーは、運動方程式を使用して、エンド・エフェクターが目的の位置に移動する関節角度を決定します。現在では、エンジニアリング、コンピューター・グラフィックス、ビデオゲームなどの多くの分野で利用されています。
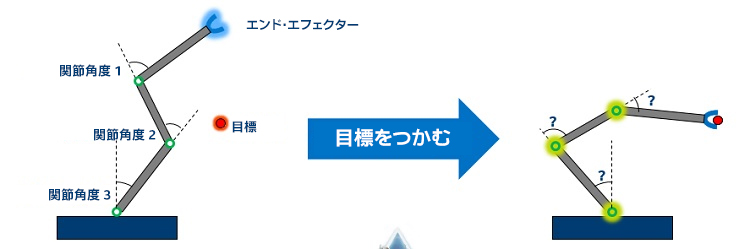
図 1. 逆運動学の例。左のロボットアームには、3 つの関節角度、1 つのエンド・エフェクター、対象物体があります。右のロボットアームは、エンド・エフェクターを対象物体に移動する関節角度を決定する必要があります。
3D アニメーションで骨格メッシュのアニメーションを行うには、一般に 2 つの方法があります。1 つ目の方法は、順運動学を使用して、回転データを直接骨格メッシュの骨に与え、回転データに従って関節または骨を直接移動します。2 つ目の方法は、IK を使用して、逆向きに目標位置を骨チェーンに与えます。IK ソルバーと呼ばれる IK アルゴリズムは、骨チェーン (エンド・エフェクター) の終了位置が目標位置に到達できる回転データを計算します。目標位置が変わると、IK ソルバーは回転データを再計算して骨を回転し、エンド・エフェクターを新しい目標位置に到達させます。
IK アニメーションを利用することで、ゲーム環境におけるキャラクターの動きが自然になり、反応が早くなります。例えば、平らでない地面や階段の上にあるキャラクターの足や、移動する物体につかまっているキャラクターの手を表現するのに利用できます。
2 つの IK ソリューションがあります。解析的アプローチは、式を使用して 1 つのソリューションを見つけます。リンクが 3 つ以上の場合の公式化は困難です (図 2)。数値的アプローチは、誤差が最小になるまで誤差関数を繰り返し使用してソリューションを見つけます (図 3)。
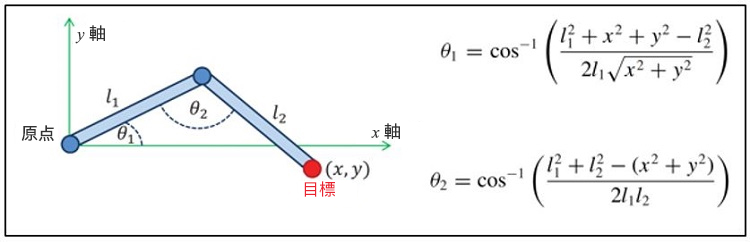
図 2. IK ソリューションの解析的アプローチ。θ1 および θ2 は式を使用して計算します。
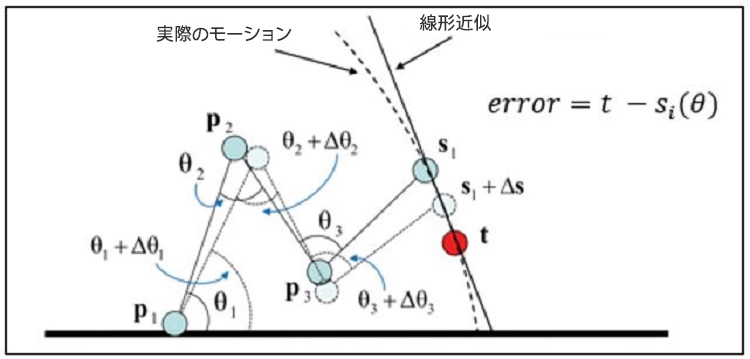
図 3. IK ソリューションの数値的アプローチ。θ1、θ2、および θ3 は誤差 (error) 関数を使用して計算します。
これらのアプローチには長所と短所があります。数値的アプローチは解析的アプローチよりも IK の品質が高くなりますが、解析的アプローチよりも多くの計算時間が必要になります。どちらのアプローチにも長所がありますが、PC 環境で高品質と大規模 IK を同時に提供することはできません。高品質 IK ソリューションには複雑な計算と膨大な計算リソースが必要になるため、PC 環境で大規模 IK をサポートすることは難しいためです。多くの 3D キャラクターのアニメーションを行う必要がある大規模多人数参加型オンライン・ロールプレイング・ゲーム (MMORPG) スタイルのアプリケーションでは、PC 環境で高品質の IK アニメーションをサポートする別のアプローチが必要になります (図 4)。

図 4. NCSOFT* のゲームの攻城戦のイラスト。MMORPG スタイルのゲーム・アプリケーションでは、多くの 3D キャラクターのアニメーションを行う必要があります。
最近の研究では、ディープラーニングやニューラル・ネットワークがキャラクターの制御や人間の動作向けのツールとして利用できることが報告されています1, 2, 3。これらの研究は、大規模 IK ソリューションに新しいアプローチをもたらしました。この記事では、それぞれ 4 つのエンド・エフェクターと 23 の関節がある 100 キャラクターのアニメーションを行う必要がある MMORPG におけるフルボディー IK の利用について考えます (図 5)。特定のチェーンではなく骨組み全体に対して、フルボディー IK を IK ソルバーに適用します。

図 5. 平らでない崖をよじ登る 100 キャラクターのフルボディー IK アニメーションのスクリーンショット。各キャラクターには 4 つのエンド・エフェクター (2 つの手および 2 つの足) と 23 の関節があります。
大規模キャラクター・アニメーションの IK 問題を解くため、2 つのディープ・ニューラル・ネットワーク (DNN) を使用します。2 つの DNN のアーキテクチャーについて述べた後、製品レベルの品質とパフォーマンスを満たすために必要な最適化手法を説明します。パフォーマンスの最適化については、PC クライアント環境 (グラフィックス・レンダリングと DNN 推論タスクを実行) のゲーム・アプリケーションのみ考慮します。最初に、CPU と GPU で DNN 推論タスクとゲームプレイ・ワークロードを同時に処理した場合を比較します。次に、NumPy*、TensorFlow*、ディープ・ニューラル・ネットワーク向けインテル® マス・カーネル・ライブラリー (インテル® MKL-DNN)、およびインテル® ディストリビューションの OpenVINO™ ツールキット4 などのさまざまな DNN ライブラリー間のパフォーマンスを比較します。最後に、バッチ処理のワークフローを変更する方法とパフォーマンスにおける効果を説明します。
この記事で述べたプロジェクトの考案、DNN モデルの設計、テスト・アプリケーションの開発を含む主要な作業は NCSOFT が担当しました。インテルは、テスト、インテル® ディストリビューションの OpenVINO™ ツールキットによる最適化、パフォーマンス解析を含むその他の作業を担当しました。
ディープラーニング・ベースの IK ソルバーのアーキテクチャー
フルボディー IK ソルバーは主に 2 つの DNN で構成されます。入力として、現在の手 (2 つのエンド・エフェクター)、現在の足 (2 つのエンド・エフェクター)、次の目標の手 (2 つの目標位置)、次の目標の足 (2 つの目標位置) の位置データを取得します。出力として、2 秒間のキャラクター・アニメーションのモーションデータ (60 フレーム) を生成します (図 6)。
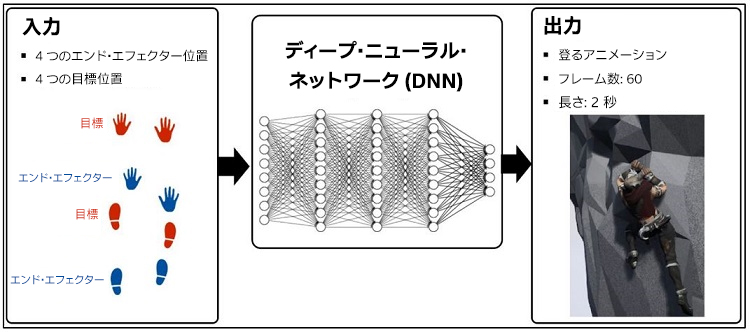
図 6. アーキテクチャーの概要。左: IK ソルバーは入力として 4 つの現在位置と 4 つの次の目標位置を取得します。中央: IK ソルバーは入力データを 2 つの DNN で処理します。右: IK ソルバーは出力として 2 秒間のキャラクター・アニメーションのモーションデータ (60 フレーム) を生成します。
当初は 1 つの DNN を使用してモーションを生成していましたが、すべてのモーションの推論と生成を同時に行うため、データが非常に大きくなり、出力結果は満足できるものではありませんでした。計算コストは高く、出力モーションの品質は低いものでした。そこで、2 つの DNN にワークロードを分散しました。
1 つ目の DNN はアニメーションの軌跡データ (5 つのキャラクターの移動経路のポイント) を作成します。2 つ目の DNN はアニメーションのポーズデータ (23 の骨の関節回転値) を作成します。2 つの DNN 間で、カーブ・フィッティング・ステップを使用して軌跡データを滑らかにします (図 7)。
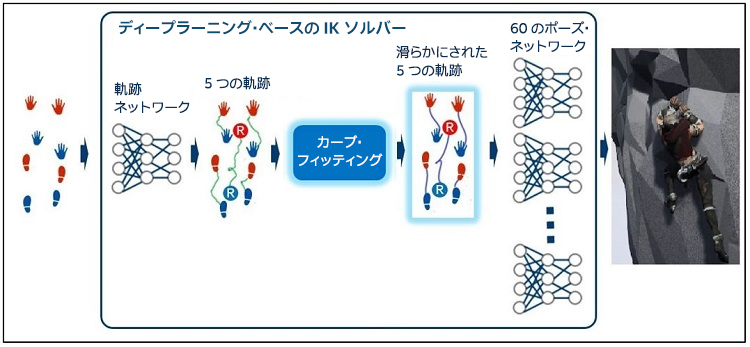
図 7. アーキテクチャーの詳細。1 つ目の DNN はアニメーションの軌跡データを作成し、2 つ目の DNN はアニメーションのポーズデータを作成します。2 つの DNN 間で、カーブ・フィッティング・ステップを使用して軌跡データを滑らかにします。
最初のステップとして、入力データが軌跡 DNN に送られ、ルートと 4 つのエンド・エフェクター (2 つの手と 2 つの足) の軌跡が生成されます。軌跡は、60 フレームの個々のモーションに対応する 60 の連続する位置データで構成されます。一般に、DNN の出力には多少のノイズが含まれ、小さなサイズの DNN ではノイズが多くなる傾向があります。軌跡 DNN の出力にも、モーションが振動する原因となるノイズが含まれます。ここでは、2 つ目のステップとして 3 次エルミートスプライン5 カーブ・フィッティング・ソリューションを使用してノイズを最小化しています。最後のステップとして、ポーズ DNN は、60 モーションのフレームのそれぞれについて、カーブ・フィッティング・ステップで滑らかにされたルートと 4 つのエンド・エフェクターの位置を受け取り、1 つのポーズを構成する 23 の関節角度を生成します。アーキテクチャーの点から見て、ここでは 2 つの重要な変更を加えました。最初に、1 つの大きな DNN を 2 つの軽量の DNN に分割することにより、パフォーマンスを大幅に向上しました。次に、カーブ・フィッティング・ステップを追加することにより、軌跡のノイズを減らして、IK の品質を向上しました。
トレーニング・データ
一般に、DNN は、非常に大量の高品質トレーニング・データでトレーニングした後にのみ、高品質の出力の推論タスクを実行できます。このプロジェクトでは、軌跡 DNN とポーズ DNN のトレーニングに約 10,000 の高品質モーションデータを使用しています。モーション・キャプチャー・デバイスから直接モーションデータの量を取得することは不可能に近いため、数値的アプローチであるヤコビ法6 を使用してモーションデータを生成しています (図 8)。
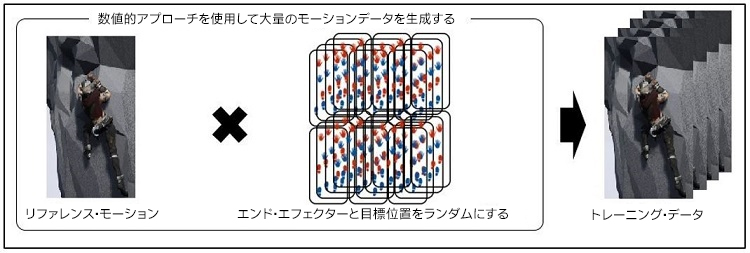
図 8. トレーニング・データの生成。最初に、リファレンス・モーションを手動で作成します。次に、リファレンス・モーションに基づいてエンド・エフェクターと目標位置をランダムにします。最後に、数値的アプローチを使用して追加のモーションデータを生成します。
最初に、好みのスタイルで 1 つのリファレンス・モーションを手動で作成します。次に、リファレンス・モーションに基づいて 10,000 のポジションセットをランダムにします (各セットは 4 つのエンド・エフェクターと 4 つの目標位置で構成されます)。最後に、1 つのリファレンス・モーションと各ポジションセットを組み合わせ、数値的アプローチを使用してモーションデータを生成します。
10,000 のモーションデータを使用し、TensorFlow* などのディープラーニング・フレームワークを利用して、専用のサーバーで 2 つの DNN をトレーニングします。DNN をトレーニングしたら、ゲーム・クライアントにデプロイします。デプロイ後、フルボディー IK ソルバーは、ゲーム・クライアント上で推論タスクを実行します。
IK の品質の比較
このセクションでは、Unreal* Engine のサンプルを使用して、フルボディー IK ソルバーのアニメーション品質を一般的な Two Bone IK ソリューションと比較します。同じ軌跡データを適用して身体の関節を比較すると、フルボディー IK ソルバーのほうがより自然な動きになります (図 9)。

図 9. 品質の比較。左: Two Bone IK を使用したキャラクター・アニメーション。右: フルボディー IK ソルバーを使用した、より自然な動きのキャラクター・アニメーション。
図 9 で、左のキャラクターは腕を不自然にまとめています。Two Bone IK は意図しないモーションを生成しているのに比べて、右のフルボディー IK ソルバーは、より自然な動きを生成しています。
最適化: CPU と GPU
このセクションでは、ゲーム・アプリケーションとフルボディー IK ソルバーの推論タスクの一般的なワークロードの性質を説明します。一般に、ゲームでは素早い反応がユーザー体験を向上する重要な要素であるため、ゲーム・アプリケーションのレイテンシーはできるだけ低くする必要があります。ゲームのラグは種類に関係なくユーザー体験を低下させます。ハイエンドのグラフィックス品質を達成することを目標とするゲームでは、GPU リソースはグラフィックス・レンダリングを実行するためにビジーになりがちですが、マルチコア CPU リソースは (レンダリング・スレッドをホストするコア 0 を除いて) 余裕があります。
フルボディー IK ソルバーの推論タスクのワークロードは、非常に小さなニューラル・ネットワークと小さなバッチサイズを使用します。ゲームループ反復中に IK アニメーションを使用して各ゲーム・キャラクターの推論タスクを実行する必要があります。絶対的なハードウェア・パフォーマンスはさておき、ワークロードそのものは、小さなサイズの推論タスクを頻繁に実行できる現在の CPU アーキテクチャーにどちらかといえば適しています。
一般的なゲームのプレイおよび IK ソルバーの推論タスクのワークロード特性を考えると、推論タスクの処理に CPU を使用するほうがパフォーマンス全体から見て適切な選択であると推測できます。この推測を検証するため、3 つの商用ゲームのプレイの全体的なパフォーマンスを比較します。パフォーマンス・メトリックとして、フレーム時間 (ミリ秒) と 1 秒あたりの推論タスクの数を使用します。CPU と GPU で推論タスクを処理する 3 つの異なる商用ゲームをプレイして、パフォーマンス・メトリックを比較します。このアニメーション推論計算は、テストしたゲームのアニメーションを実行したものではなく、推論計算がシステムのパフォーマンスに与える影響をモデル化するプロキシー・ワークロード構成によるものであることに注意してください。ランタイムの測定はテストマシン A (表 1) を使用して行われました。
表 1. テストマシン A のシステム構成
| CPU | インテル® Core™ i7-670px0K プロセッサー |
| GPU | NVIDIA* GeForce GTX* 1080 |
| メモリー | 16GB |
| OS | Microsoft* Windows* 10 |
ゲームのフレーム時間を測定する前に、ゲームプレイ中の CPU と GPU の使用率を調べました (図 10)。
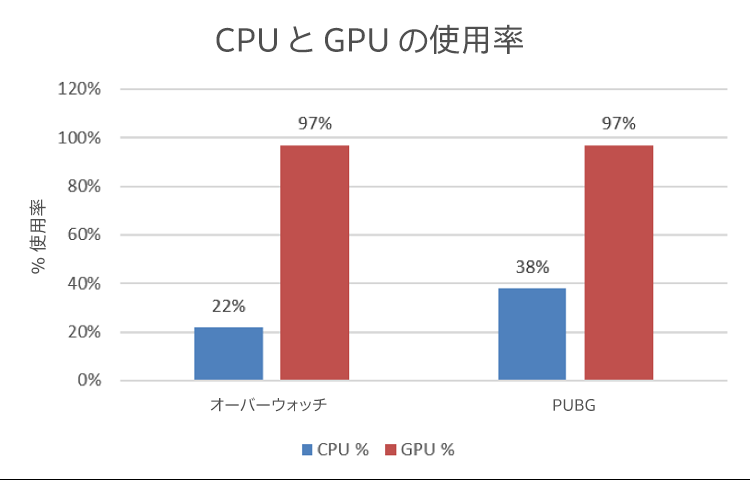
図 10. テストマシン A の CPU と GPU の使用率 (IK 推論タスクなし)。
結果を見ると、GPU リソースの大部分はゲームプレイ中に使用されているのに対して、マルチコア CPU は余裕があることが分かります。
追加された DNN 推論タスクがゲームのパフォーマンスにどのように影響するか詳しく確認するため、最初にベースラインとして DNN 推論タスクなしのゲーム・レイテンシーを測定しました。次に、TensorFlow* ベースの推論タスクを別のプロセスとして CPU と CPU で実行した場合のゲーム・レイテンシーを測定しました (図 11)。ゲーム・レイテンシーは 1 つのフレームが処理されるフレーム時間です。
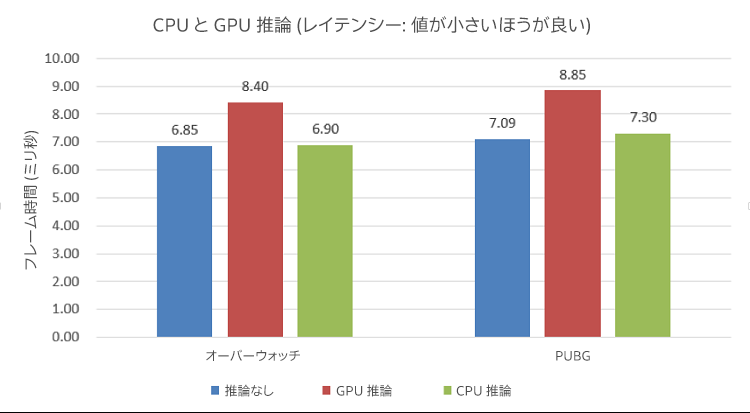
図 11. テストマシン A に IK 推論タスクを追加した場合のレイテンシーの変化。青のバーは推論タスクなしのフレーム時間を、赤のバーは GPU で推論タスクを処理した場合のフレーム時間を、緑のバーは CPU で推論タスクを処理した場合のフレーム時間を示しています。
結果を見ると、GPU で推論タスクを処理した場合はフレーム時間が大幅に増加しているのに対して、CPU で推論タスクを処理した場合はフレーム時間がそれほど増加していないことが分かります。
ゲーム実行中の GPU と CPU の推論スループットも測定しました (図 12)。推論スループットは 1 秒の間に処理された推論タスクの数です。
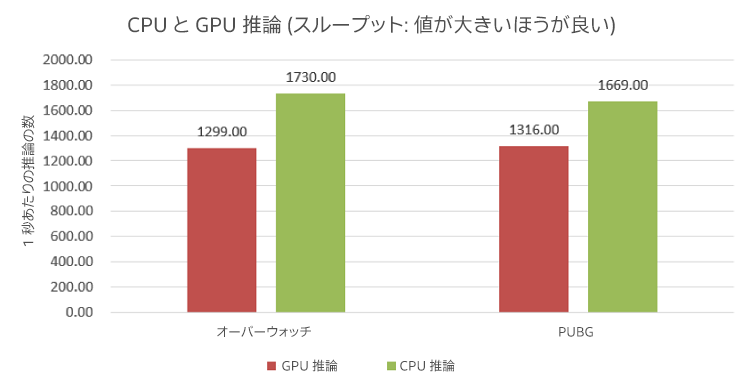
図 12. テストマシン A の GPU と CPU の推論スループット。赤のバーは GPU が処理した 1 秒あたりの推論の数を、緑のバーは CPU が処理した 1 秒あたりの推論の数を示しています。
結果を見ると、GPU で推論タスクを処理してゲームをプレイすると GPU リソースを互いに取り合うことになるため、推論スループットは CPU のほうが高くなっています。これらの結果から、推論タスクは CPU で処理することに決めて、推論スループットを向上する CPU の最適化に取り組みました。
最適化: DNN ライブラリー
このセクションでは、Naïve C++ (OpenMP*)、NumPy* (OpenBLAS)、TensorFlow* (Eigen 1.12.0)、およびインテル® ディストリビューションの OpenVINO™ ツールキット (2018 R5) の推論エンジンのパフォーマンスを測定します。ランタイムの測定はテストマシン B (表 2) を使用して行われました。
表 2. テストマシン B のシステム構成
| CPU | インテル® Core™ i9-7900X プロセッサー |
| メモリー | 16GB |
| OS | Ubuntu* 16.04 LTS |
パフォーマンス・メトリックとして、各ライブラリーの平均応答時間 (レイテンシー) を使用します。パフォーマンスのスケーリングを確認するため、異なるコア数のレイテンシーを測定します (図 13)。レイテンシーは、100 の IK モーションを作成するためにすべての推論タスクで費やされた処理時間です。
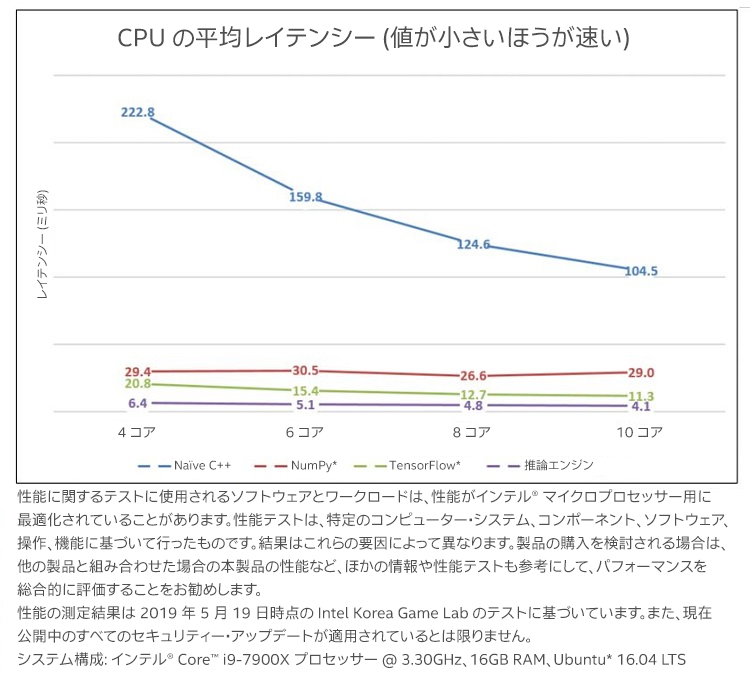
図 13. テストマシン B の DNN ライブラリーの平均レイテンシー。青のバーは Naïve C++ バージョンの各 4 コア構成のレイテンシー (推論タスクの合計処理時間) を示しています。赤のバーは NumPy* バージョンのレイテンシーを、緑のバーは TensorFlow* バージョンのレイテンシーを、紫のバーは推論エンジンバージョンのレイテンシーを示しています。
図 13 から、インテル® ディストリビューションの OpenVINO™ ツールキットの推論エンジンのパフォーマンスが最も優れていることが分かります。
DNN モデルをゲーム・クライアントにデプロイする一般的なワークフローでは、最初にモデルをさまざまな環境でトレーニングします。次に、モデル・オプティマイザーはトレーニング済みモデルを中間表現 (IR) フォーマットに変換します。最後に、推論エンジンはこの IR をロードしてゲーム・クライアントで推論タスクを処理します (図 14)。
インテル® ディストリビューションの OpenVINO™ ツールキットを利用すると、ユーザーはインテル® プロセッサー向けにディープラーニング・モデルを最適化できます。ツールキットは、モデルのトレーニングに使用されたハードウェア・プラットフォームにかかわりなく、Caffe*、Apache* MXNet、TensorFlow* からトレーニング済みのモデルをインポートできます。開発者は、統一されたアプリケーション・プログラミング・インターフェイスを使用して、さまざまなトレーニング済みのニューラル・ネットワーク・モデルとアプリケーションのロジックを素早く統合できます。ツールキットは、ソリューション全体のフットプリントを減らし、インテル® アーキテクチャー・ベースのハードウェア向けにパフォーマンスを最適化することにより、推論のパフォーマンスを最大化します。
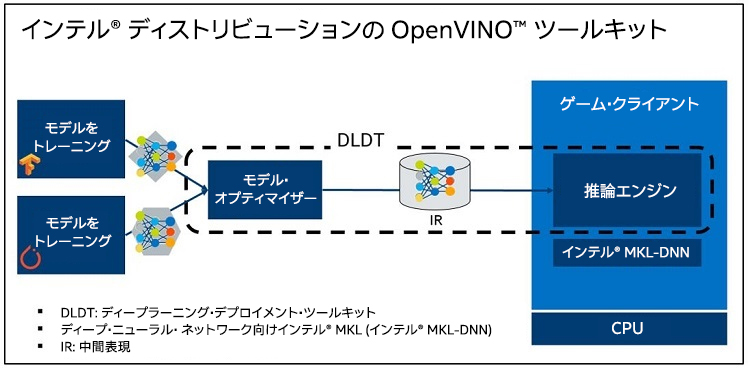
図 14. インテル® ディストリビューションの OpenVINO™ ツールキットはディープラーニング・デプロイメント・ツールキット (DLDT) を含みます。DLDT はモデル・オプティマイザーと推論エンジンなどで構成されます。
インテル® VTune™ プロファイラーを実行したところ、Naïve C++ では OpenMP* ライブラリー、NumPy* では OpenBLAS ライブラリー、TensorFlow* では Eigen ライブラリー、推論エンジンではインテル® MKL-DNN ライブラリーが、hotspot 関数の 1 つとして示されました (図 15)。
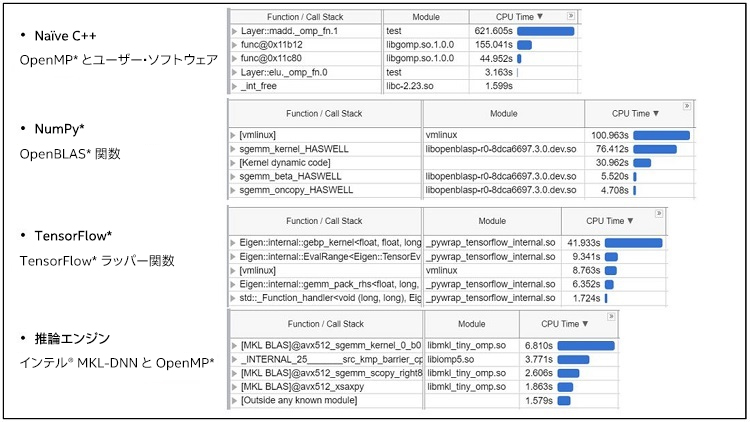
図 15. Naïve C++ バージョン、NumPy* バージョン、TensorFlow* バージョン、推論エンジンバージョンの上位 5 つの hotspot 関数。
最適化: バッチ処理
同じ操作を複数回処理する場合、複数の操作をグループ化してバッチで一括処理すればパフォーマンスを向上できることは明白です。例えば、3 つの入力と 3 つの出力がある 4 つの全結合層は、同じ形状のインスタンスをバッチで一括処理できます (図 16)。
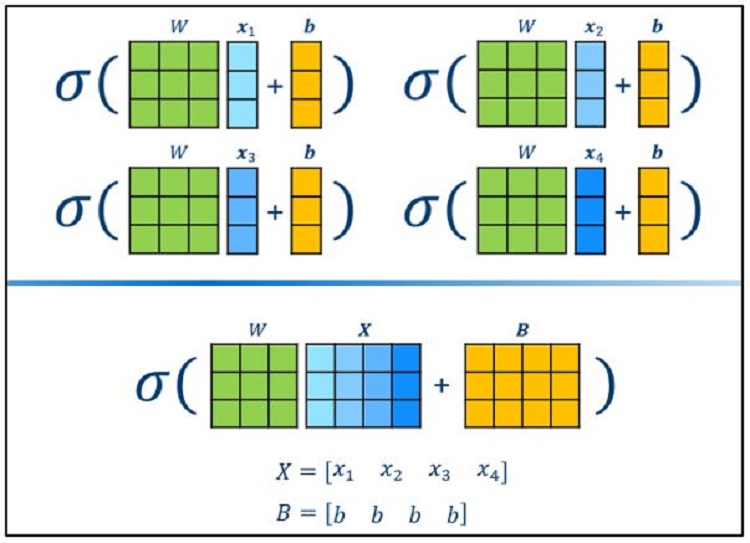
図 16. バッチ処理の例。一般に、同じ方法の複数の操作をグループ化してバッチで一括処理するとスループットが向上します。
このセクションでは、バッチ処理のワークフローを変更してスループットの効率を向上する方法を説明します。初期の IK ソルバーはキャラクターのリクエストをバッチで処理できませんでした。ゲーム・アプリケーションでは、複数のキャラクターが IK ソルバーにリクエストして IK アニメーションのポーズデータを生成します。すべてのゲームループで、アニメーションするキャラクターは次のフレームをリクエストします。IK ソルバーがリクエストを 1 つずつ処理すると時間がかかるため、バッチ・マネージャーを追加して IK ソルバーのリクエストを効率的に収集して管理するように変更しました (図 17)。
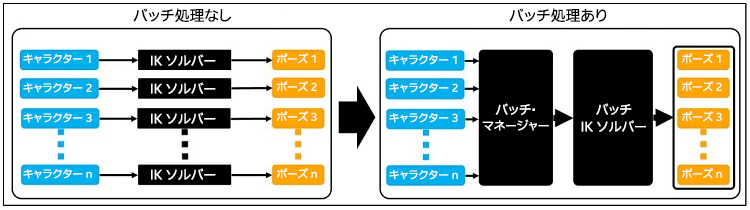
図 17. バッチ処理でのワークフローの変更。左: 各キャラクターが専用の IK ソルバーにリクエストしてそれぞれ IK アニメーションのポーズデータを生成します。右: すべてのキャラクターが 1 つのバッチ・マネージャーにリクエストして IK リクエストをバッチで処理します。
この記事のセクション 2 で述べたように、フルボディー IK ソルバーは、軌跡、カーブ・フィッティング、ポーズの 3 つの処理ステップで構成されています。バッチ・マネージャー使用することで、軌跡ステップとポーズステップはバッチで処理できるようになりました。しかし、3 次エルミート・スプライン・アルゴリズムを 3 次多項式形式で使用していたため、カーブ・フィッティング・ステップはバッチで処理できませんでした。図 18 は、3 次エルミートスプラインの多項式の定義です。
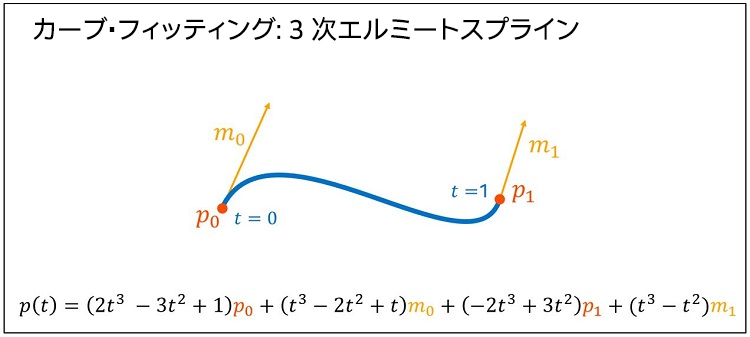
図 18. 3 次エルミートスプラインの多項式。t を 0 から 1 の値の代わりに使用して、カーブ上のポイントを得ることができます。
p(t) の計算は単純です。しかし、100 キャラクターのモーションを作成するには 25,000 の計算を行う必要があるため、効率的な計算メソッドが必要です。一般に、多項式の乗算は 1 つの行列形式で表現できます。例えば、t0 から t5 の 6 つのポイントを解く 6 つの多項式を組み合わせて 1 つの行列形式で表現できます (図 19)。
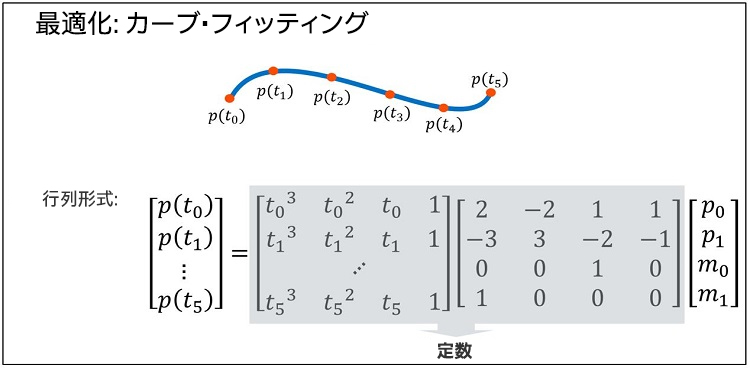
図 19. 行列形式で表現された多項式の乗算。p(t0) から p(t5) を解く 6 つの多項式を 1 つの行列で表現できます。t0 から t5 の値は定数で、グレイの領域も 1 つの行列乗算の後に定数になります。
この行列形式で、グレイの領域は 1 つの行列乗算の後に定数として見なすことができ、6 つのポイントは実行時に 1 つの行列乗算で得ることができます。そのため、軌跡ステップとバッチステップのようにバッチでカーブ・フィッティング・ステップを実行します (図 20)。
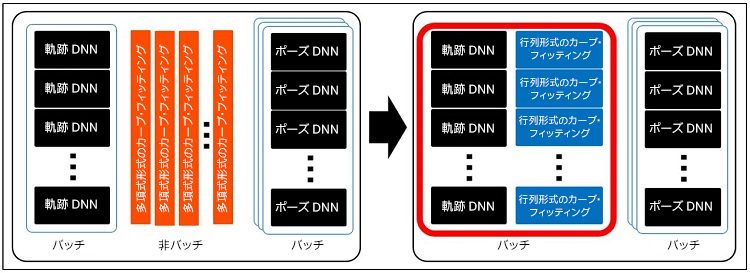
図 20. バッチ処理でのカーブ・フィッティング。左: カーブ・フィッティング・ステップは多項式形式で 3 次エルミート・スプライン・アルゴリズムを使用します。右: バッチ処理のためアルゴリズムは行列表現に変換されます。
3 つのテストを実行して、バッチプロセスによりパフォーマンスがどの程度向上するか (レイテンシーを) 確認しました。ワークロードは、60 フレームの 100 キャラクターのモーションデータを生成することです (図 21)。
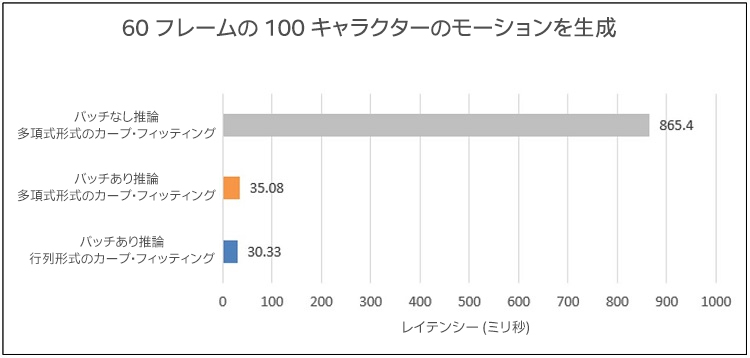
図 21. テストマシン B で 60 フレームの 100 キャラクターのモーションデータを生成するレイテンシー。グレイのバーはバッチなしの多項式形式のカーブ・フィッティングのレイテンシー (推論タスクの合計処理時間) を示しています。オレンジのバーはバッチありの多項式形式のカーブ・フィッティングのレイテンシーを示しています。青のバーはバッチありの行列形式のカーブ・フィッティングのレイテンシーを示しています。
最初のテストでは、バッチなしで一度に 1 つの推論タスクを実行しました (カーブ・フィッティングは多項式形式)。結果は非常に低速でした。2 回目のテストでは、バッチありで推論タスクを実行しました (カーブ・フィッティングは多項式形式)。レイテンシーは大幅に軽減されました。最後に、多項式形式のカーブ・フィッティング・ステップを行列形式に変換して、すべての推論ステップをバッチで (一括) 処理しました。レイテンシーはさらに軽減されました。
最終結果を標準パフォーマンス・メトリックであるフレーム時間に変換するため、最終レイテンシーを平均軌跡とカーブ・フィッティングおよび平均ポーズに分割しました (図 22)。
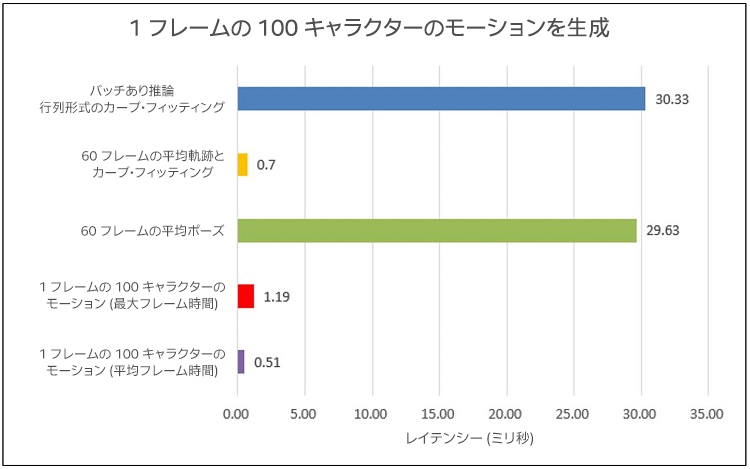
図 22. テストマシン B で 100 キャラクターのモーションデータを生成するレイテンシーのフレーム時間の変換。青のバーはバッチありの行列形式のカーブ・フィッティングの最終レイテンシーを示しています。オレンジのバーは最終レイテンシーで軌跡とカーブ・フィッティング・ステップが占める時間を示しています。緑のバーは最終レイテンシーでポーズステップが占める時間を示しています。赤のバーは最大フレーム時間を示しています。紫のバーは平均フレーム時間を示しています。
軌跡とカーブ・フィッティング・ステップは 60 フレームで 1 回実行され、ポーズステップは 1 フレームで 1 回実行されます。軌跡とカーブ・フィッティングの時間を 1 フレームあたりのポーズ時間に追加して、最大フレーム時間を計算しました (1.19 ミリ秒 = 0.7 ミリ秒 + (29.63 ミリ秒 ÷ 60))。最終フレーム時間を 60 で割って、平均フレーム時間を計算しました (0.51 ミリ秒 = 30.33 ミリ秒 ÷ 60)。目標 (5 ミリ秒) を上回る最終結果が得られました。
まとめ
この記事では、ディープラーニングを使用して大規模な逆運動学モーションデータを生成する方法を示しました。1 つの大きな DNN を 2 つの軽量の DNN に分割し、カーブ・フィッティング処理を使用して軌跡 DNN のノイズを軽減しました。パフォーマンスの最適化という点では、CPU 上で推論タスクを処理しても、GPU 上で同じワークロードを処理した場合と比べて、全体的なゲームのパフォーマンスにはほとんど影響しませんでした。これは、GPU には多くのワークロードを処理するためにすでに大きな負荷がかかっている一方で、マルチコア CPU にはアイドル状態のコアやスレッドが多く存在するためです。次に、異なる DNN ライブラリーのパフォーマンスを評価しました。最後に、推論タスクをバッチ処理することでパフォーマンスを向上できることを示しました。
インテル® ディストリビューションの OpenVINO™ ツールキットの推論エンジンについては、CPU 上で推論タスクを処理するとパフォーマンスの利点があることが分かりました。今後は、インテル® プロセッサー・グラフィックスを使用してこれらのワークロードを処理する方法を調べる予定です。
NCSOFT は、Unreal* Engine* およびフルボディー IK ソルバーを使用して 100 のゲームキャラクターが平らでない崖をよじ登る単純なデモゲームを開発しました。各キャラクターは、崖から落ちることなく、手と足を正しく動かしていました。NCSOFT は、近い将来、商用ゲームで IK ソルバーを利用することを計画しています。
著者紹介
インテル コーポレーション
Tai Ha は、インテル コーポレーションのシニア・ソフトウェア・エンジニアで、ソフトウェア開発において 10 年以上およびデータセンター、メディア、ゲーム・アプリケーション向けのソフトウェア最適化において 13 年の経験があります。
Kyle Park は、インテル コーポレーションのシニア・ソフトウェア・エンジニアで、クラウドサービスのバックエンド・サーバーにおいて 10 年以上および AI、データセンター、ハイパフォーマンス・コンピューティング (HPC)、ゲーム・アプリケーション向けのソフトウェア最適化において 9 年の経験があります。
Jeff Park は、インテル コーポレーションのシニア・テクニカル・コンサルティング・エンジニアで、6 年にわたり、インテルのシステムおよびソフトウェアの最適化とデバッグに取り組んでいます。その前の 14 年間は、組込みソフトウェア開発者およびシステム・デバッグ・エンジニアとして働いていました。
NCSOFT* AI Center、Game AI Lab (敬称略)
Dr. Hanyoung Jang は、世界的なゲーム会社、NCSOFT のモーション AI チームのチームリーダーです。ロボット工学、GPGPU (GPU による汎目的計算)、コンピューター・グラフィックス、AI などの分野で研究を行ってきました。現在は、ディープラーニングを利用した自然なキャラクター・アニメーションの作成について研究を行っています。
Hyoil Lee は、NCSOFT の AI システムチームのチームリーダーです。ソウルの高麗大学校でコンピューター・サイエンスの修士号を取得しており、ソフトウェア開発、組込みシステム、アルゴリズムの最適化において 10 年の経験があります。過去 3 年間は、マシンラーニング・システムの設計と開発を行っていました。
Dongwon Yoon は、NCSOFT のシニアゲーム AI 研究者です。サーバー・エンジニアリングとサーバー・オペレーションを専門としており、10 年以上の経験があります。過去数年にわたり、ディープラーニング推論の最適化および強化学習システムのシミュレーションに焦点を当てた、AI 関連のソリューションを開発していました。
脚注
1. Katerina Fragkiadaki, Sergey Levine, Panna Felsen, and Jitendra Malik. Recurrent Network Models for Human Dynamics. In Proceedings of the IEEE International Conference on Computer Vision, pp. 4346–4354, 2015.
2. Daniel Holden, Taku Komura, and Jun Saito. Phase-Functioned Neural Networks for Character Control. ACM Transactions on Graphics (TOG), 36(4):42, 2017.
3. Julieta Martinez, Michael J Black, and Javier Romero. On Human Motion Prediction Using Recurrent Neural Networks. arXiv preprint, arXiv:1705.02445, 2017.
4. インテル® ディストリビューションの OpenVINO™ ツールキット (英語)
5. Gerald Farin. Curves and Surfaces for CAGD: A Practical Guide (5th edition). Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 2002.
6. Samuel R. Buss. Introduction to Inverse Kinematics with Jacobian Transpose, Pseudoinverse and Damped Least Squares Methods. IEEE Journal of Robotics and Automation, 17(1), 2004.
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
