
この記事は、インテル® AI Blog に公開されている「Voicebot Scaling Challenge: Throughput Leadership with CPU」(https://www.intel.ai/voicebot-scaling-challenge) の日本語参考訳です。
企業は優れたカスタマーサービスを提供する新しい方法を模索しています。いつでも、どこからでも高品質なカスタマーサービスを利用できるボイスボットは、そのような企業の要望に応えることができます。ガートナーの予測 (英語) では、2020 年までにカスタマーサービスとサポート業務の 25% が、音声、チャット、メールのエンゲージメント・チャネル全体で仮想カスタマー・アシスタント・テクノロジーを統合する見込みです。また、インタラクティブな音声応答市場は、2023 年までに 55.4 億米ドル (英語) に達すると予測されています。
ボイスボット展開の最初の (そして、最も計算負荷の高い) 段階は、音声をテキストに変換する自動音声認識 (ASR) プロセスです。オープンソースの Kaldi 音声認識ツールキット (英語) は、多様な言語モデルと電話音声を処理する汎用性により、今日の企業展開で最も広く使用されている ASR サービスを提供しています。そのため、インテル® Xeon® スケーラブル・プロセッサー上で動作する Kaldi ASR のパフォーマンス向上に注目して、顧客が大規模展開でリアルタイム応答機能を備えたボイスボットを実装できるように支援しました。私たちは、これを「ボイスボット・スケーリング・チャレンジ」と呼んでいます。
Kaldi 音声認識ツールキット
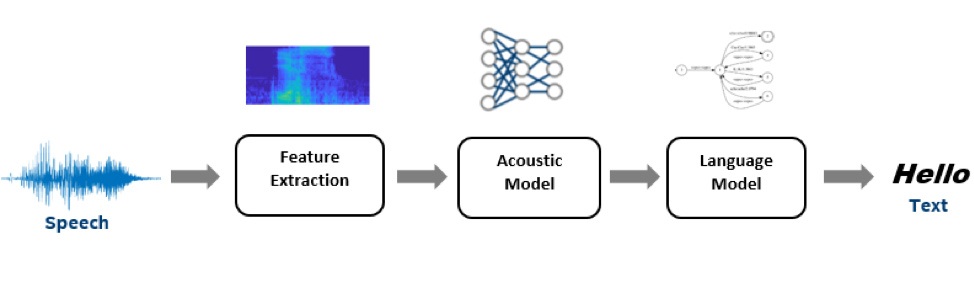
Kaldi ツールキットは、研究団体で非常に人気があり、ASR のデフォルトのツールキットになりました。典型的な Kaldi ASR パイプラインでは、入力音声信号 (波形) を処理して、MFCC、CMVN、i-vector などの一連の機能を抽出します。MFCC/CMVN は音声コンテンツを表現し、i-vector は発話や話者のスタイルを表現します。
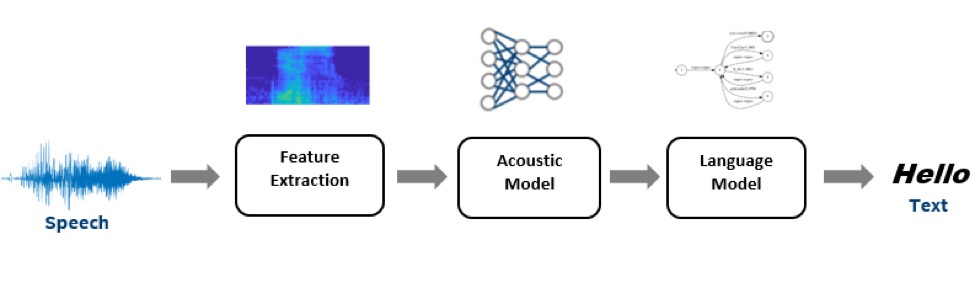
図 1: 高レベルの自動音声認識パイプライン
音響モデルは抽出された特徴を一連のコンテキスト依存音素 (特定の言語で単語を別の単語と区別する音の単位) に変換します。Kaldi はガウス混合モデル (GMM) ベースとディープ・ニューラル・ネットワーク (DNN) ベースの音響モデリングの実装をサポートします。AI とディープラーニングの進歩により、DNN は GMM ベースの実装に広く取って代わりつつあります。
言語モデルデコーダーは音素を受け取り、格子 (特定の音声部分の可能性が高い代替の単語シーケンスの表現) に変換します。デコードグラフは、データの文法に加えて、連続する特定の単語の分布と確率 (n-gram) を考慮します。このベンチマークでは、Kaldi の WFST デコーダーの標準実装を使用し、インテルの最適化されたデコーダーと比較しました。また、nnet3 ベースの遅延ニューラル・ネットワーク (TDNN) モデルの ASpIRE と Librispeech を使用しました。ベンチマークは、推論パフォーマンスを大幅に向上する可能性があるアクセラレーション・オプションを強調しています。
インテルによる Kaldi の CPU パフォーマンスの最適化
インテル® プロセッサー上でパフォーマンスが向上するように、Kaldi 推論パイプライン全体が最適化されています。音響モデルの最適化の要約 (英語) と詳細 (英語) は、以前の出版物 (英語) で取り上げられています。これらの操作のパフォーマンスは、インテル® プロセッサー向けに最適化された BLAS ルーチンを含むインテル® マス・カーネル・ライブラリー (インテル® MKL) やニューラル・ネットワーク・プリミティブのディープ・ニューラル・ネットワーク・ライブラリー (DNNL) (英語) などのツールを使用して向上できます。
Kaldi デコーダーの概要
デコーダーは音響モデルからスコアを受け取り、言語モデルに基づいて格子やテキストにマップします。Kaldi ツールキットは、加重有限状態トランデューサー (WFST) ベースのデコードを使用します。デコードでは、異なるナレッジソースを統合する加重有限状態トランデューサー (WFST) でビーム検索が実行されます。
- 隠れマルコフ・モデル・トポロジー (H)
- コンテキスト依存 (C)
- 発音モデル (L)
- 言語モデル (G)
検索フェーズでは、音響スコアが HCLG トランデューサーの重みと組み合わされて、最高スコアの単語シーケンスが特定されます。「デコード」と呼ばれるこのプロセスは、ビーム幅、音響スケール係数など、多くのパラメーターによって制御されます。
ここでは、ASpIRE チェーンモデルを使用して、Kaldi デコーダーの計算シグネチャーを評価します。以下に示すシステム構成では、Kaldi デコーダーの実行に実行時間全体の約 38% が費やされています。これは、デコーダーのパラメーター、語彙、言語モデルの辞書によってはさらに高くなる可能性があります。
インテルの最適化されたデコーダー
インテルは、Kaldi ASR デコーダーの言語モデル・パフォーマンスを向上する新しいデコーダー・ライブラリーを開発しました。このライブラリーは、インテル® ディストリビューションの OpenVINO™ ツールキット (英語) の将来のリリースのおいて、バイナリー形式で提供される予定です。デコードプロセスを高速化するため、いくつかの改善が適用されています。例えば、WFST 表現はオリジナルの Kaldi HCLG WFST ではなく、高速なデコード向けに最適化されたデータ構造に基づいています。また、検索アルゴリズムは、ビーム・プルーニング手法の組み合わせを利用しています。ビーム・プルーニングは、前のステップのスコアが最高スコアよりも著しく悪いトークンを破棄することで検索領域を縮小します。トークンは WFST を通るパスを表します。トークンのバッチを個別にではなく一度に破棄することで、計算の複雑さが大幅に軽減されます。最後に、デコード・ライブラリー全体は、Kaldi デコーダーの最適化されたバージョンではなく、完全にゼロから実装されています。
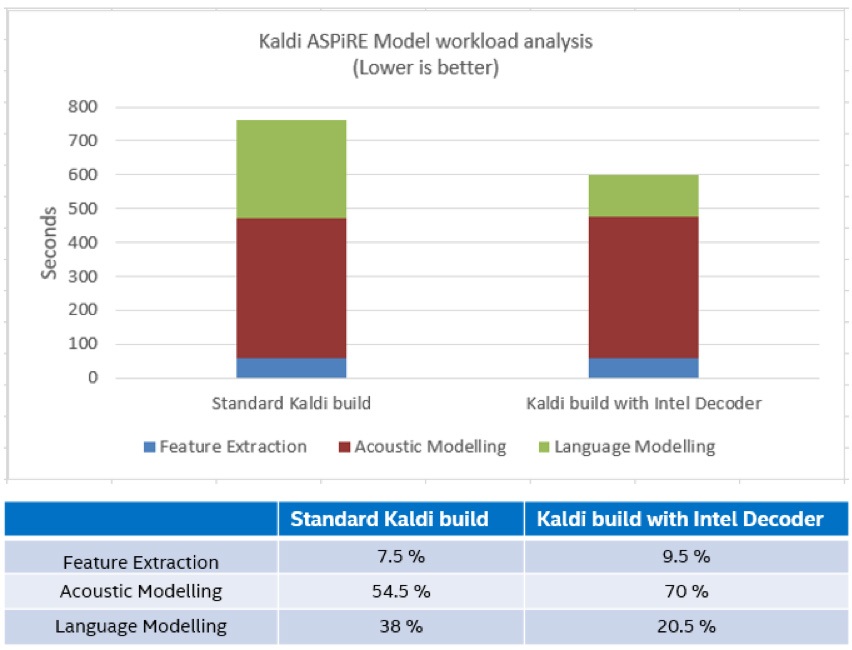
図 2: ASpIRE モデルの Kaldi ASR 計算分布[1]。ワークロード解析は、インテル® VTune™ プロファイラーでインテル® Xeon® Gold プロセッサーのシングルコア上で Librispeech test-clean データセットを使用して実行。
図 2 に示すように、インテルの最適化されたデコーダーは、実行時間全体に占める割合がはるかに小さいです。結果は、言語モデルの複雑さとサイズにより異なります。自動音声認識 (ASR) システムのパフォーマンスと精度は、リアルタイム係数 (RTF) (英語) と単語エラー率 (WER) (英語) の 2 つの主要メトリックから測定できます。RealTimeX は RTF の逆数です。RealTimeX の向上は、WER の整合性に影響しません。
ベンチマーク結果
オンラインの AI 推論サービスによるリアルタイムの人間と機械の対話では、バッチ推論パフォーマンスは関係ないため、レイテンシーが重要なサービスメトリックです。しかし、大規模な展開では、レイテンシー軽減のわずかな利点も急速になくなります。これらのユースケースで、ボイスボットのようなオンライン AI 推論サービスに最も有用なメトリックは、レイテンシー依存スループットまたは小さなバッチサイズのスループットです。
リアルタイムのボイスボット・シナリオでは、すべての音声入力が同時に利用できるわけではありません。そのため、リアルタイムの音声変換パフォーマンスを測定する代表的なテストとして、厳しいレイテンシー要件で処理するため非常に小さなバッチでのみ入力音声データを利用できる、小さなバッチのスループット・テストを選択しました。テストは、「最良のシナリオ」と「最悪のシナリオ」に分類することができます。
最良のシナリオテストでは、音響モデルと言語モデルはともに固定されており、入力音声ストリームごとに変わらないと仮定します。このシナリオの時間には、特徴抽出、音響モデル、および言語モデルに費やされた時間のみが含まれます。
最悪のシナリオテストでは、音響モデルと言語モデルは固定されておらず、モデルのロードに費やされた時間も含まれます。「モデルのロード」とは、ストレージから CPU または GPU のメインメモリーにモデルをフェッチする処理を指します。
スループット・テストのベンチマークは、NVidia* Tesla* V100 GPU ベースのシステム (AWS* P3 インスタンス) とインテル® Xeon® Gold 6252 プロセッサー・ベースのシステムで小さな入力/バッチサイズを使用して測定しました。システム構成の詳細は、付録を参照してください。インテルベースのシステムでは、デフォルトの Kaldi デコーダーとインテルの最適化されたデコーダーの両方の結果を示します。
次の図表は、Librispeech test-clean データセットを使用した ASpIRE と Librispeech モデルの小さなバッチサイズでのスループット・テストのパフォーマンスを示しています。
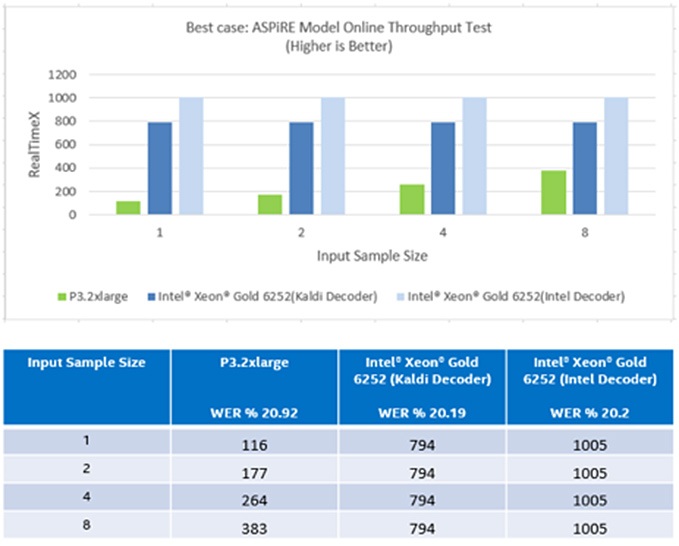
図 3: 小さなバッチサイズでの ASpIRE モデルのオンライン・スループット (最良のシナリオ)[1]
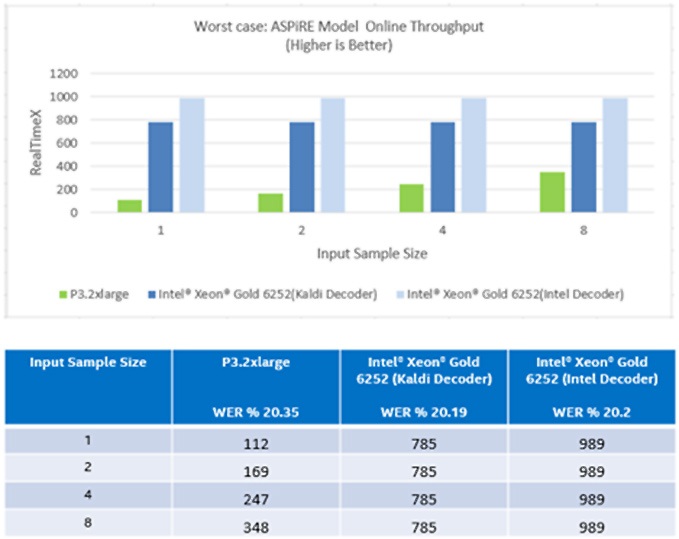
図 4: 小さなバッチサイズでの ASpIRE モデルのオンライン・スループット (最悪のシナリオ)[1]
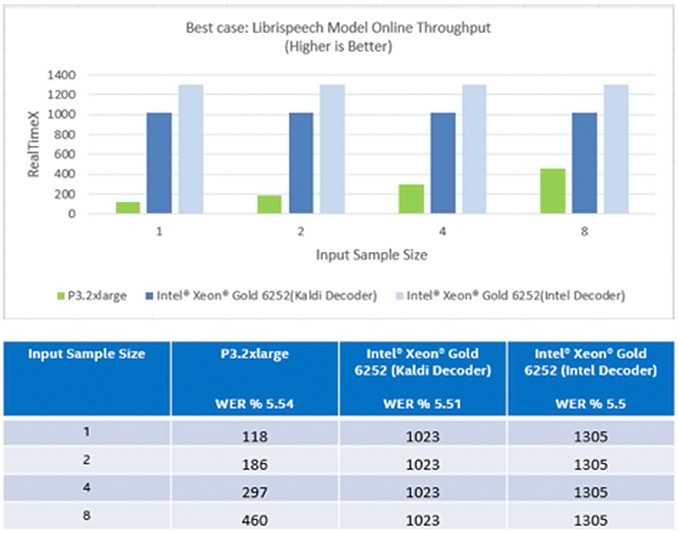
図 5: 小さなバッチサイズでの Librispeech モデルのオンライン・スループット (最良のシナリオ)[1]
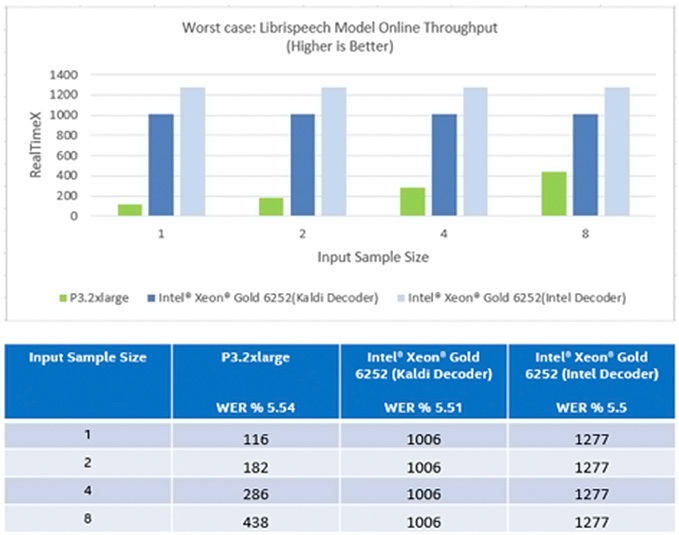
図 6: 小さなバッチサイズでの Librispeech モデルのオンライン・スループット (最悪のシナリオ)[1]
上記のとおり、ASpIRE モデルでは、バッチサイズが 1 の場合、インテル® Xeon® Gold プロセッサーのほうが NVIDIA* Tesla* V100 GPU よりも 6.8 倍優れています。インテルの最適化されたデコーダーを使用したテストでは、CPU のパフォーマンスは GPU よりも 8.6 倍優れています[2]。Librispeech モデルでは、単一バッチ推論においてインテル® Xeon® プロセッサーのスループットは NVIDIA* GPU と比較して 11 倍です。マルチコア CPU では、入力ストリームはバッチされるのを待たずに、受け取るとすぐに処理されます。
ASpIRE モデルはより複雑で、顧客が展開するプロダクション・モデルをより適切に表現しています。単一の CPU ノード上でスループットを向上することで、大規模なプロダクション・システムは、追加のアクセラレーター・ハードウェアを購入することなく、ボイスボットのような AI 推論サービスを展開できます。
まとめ
Kaldi ASR エンジンは、現在稼働している大多数のエンタープライズ・ボイスボットを支えています。インテル® Xeon® スケーラブル・プロセッサーは、このクラスのワークロードに対して独自のパフォーマンス上の利点を提供します。この記事では、Kaldi ASR の単一の計算ノードでのレイテンシー依存スループットを測定し、単一バッチ推論においてインテル® Xeon® Gold プロセッサーは NVIDIA* Tesla* V100 GPU と比較して、ASPiRE モデルでは 8.6 倍、Librispeech モデルでは 11 倍高速であることを示しました[2]。数百万の同時ボイスボットを展開している企業にとって、このスループットの向上は驚異的なパフォーマンスをもたらし、既存の大規模プロダクション・システムの価値を最大化します。
最後に、この記事に貢献してくれた Georg Stemmer 氏と Joachim Hofer 氏に感謝します。
関連情報 (英語)
- Kaldi Speech Recognition Toolkit (Povey et. al., 2012), https://publications.idiap.ch/downloads/papers/2012/Povey_ASRU2011_2011.pdf.
- Speaker Adaptive Model for Hindi Speech using Kaldi Speech Recognition toolkit
- Automatic Speech Recognition using the Kaldi Toolkit (Briere, 2018)
- How to Start with Kaldi and Speech Recognition (Ramon, 2018)
- Kaldi ASR: Extending the ASpIRE model (Varga, 2017)
付録
性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。性能の測定結果は 2019 年 9 月時点のインテルの社内テストに基づいています。また、現在公開中のすべてのセキュリティー・アップデートが適用されているとは限りません。絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。実際の性能はシステム構成によって異なります。詳細については、各システムメーカーまたは販売店にお問い合わせいただくか、http://www.intel.co.jp/ を参照してください。実際の費用と結果は異なる場合があります。インテルは、サードパーティーのデータについて管理や監査を行っていません。ほかの情報も参考にして、正確かどうかを評価してください。
SYSmark* や MobileMark* などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。 詳細については、www.intel.com/benchmarks (英語) を参照してください。
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。
注意事項の改訂 #20110804
[1] 性能やベンチマーク結果について、さらに詳しい情報をお知りになりたい場合は、http://www.intel.com/benchmarks/ (英語) を参照してください。インテル® ソフトウェア製品のパフォーマンスおよび最適化に関する注意事項については、http://software.intel.com/en-us/articles/optimization-notice#opt-jp を参照してください。
[2] システム構成:
beam、lattice-beam、max-active などの Kaldi デコーダーのパラメーターは、CPU と GPU の両方で同様の WER % を達成するように調整されています。max_q_capacity や aux_q_capacity などの CUDA* デコーダーのパラメーターも ASpIRE モデルを実行するため調整されています。
複数の反復で同じ入力音声を処理する必要はないため、cuda-flag 反復は 1 に設定しています。これにより、RealTimeX は向上しますが、ホストシステムのメモリーと GPU メモリー間のデータ移動コストが平準化されます。
CUDA* デコーダーの現在の実装は、NVIDIA* V100 GPU の単一の AWS* インスタンス上で batched-wav-nnet3-cuda の複数のインスタンスをサポートしていません。GPU テスト用のソフトウェアは、2019 年 10 月 17 日時点の NVIDIA が提供する情報 (英語) に基づいて選択しています。
| ソフトウェア構成 | Kaldi ASR – インテル CPU | Kaldi ASR – NVIDIA* GPU |
|---|---|---|
| コンパイラー | ICC 19.0.0.117 | GCC 5.4.0、 nvcc 10.1 |
| テストに使用したフレームワーク | Kaldi ASR (72ca1eb3e7630983c36a05053f72448ec707fcde) |
Kaldi ASR (72ca1eb3e7630983c36a05053f72448ec707fcde) |
| ベンチマークに使用した その他のライブラリー |
インテル® MKL 2019u2 | CUDA* 10.1 |
| データセット | Librispeech (test-clean test-other) |
Librispeech (test-clean test-other) |
| ASpIRE モデル設定フラグ 音響モデル: ~141MB、 言語モデル: ~1020MB |
beam=10 lattice-beam=1 max-active=1500 iterations=1 CPU-Threads=48 実行ファイル: online2-wav-nnet3-latgen-faster |
beam=11 lattice-beam=1 max-active=10000 batch_size=180 batch_drain_size=15 iterations=1 file_limit=-1 gpu-feature-extract=false main-q-capacity=40000 aux-q-capacity=500000 CPU-Threads=8 cuda-control-threads=3 cuda-worker-threads=5 実行ファイル: batched-wav-nnet3-cuda |
| Librispeech モデル設定フラグ 音響モデル: ~78MB、 言語モデル: ~192MB |
beam=8 lattice-beam=1 max-active=4000 iterations=1 CPU-Threads=48 実行ファイル: online2-wav-nnet3-latgen-faster |
beam=10 lattice-beam=7 max-active=10000 batch_size=180 batch_drain_size=15 iterations=1 file_limit=-1 gpu-feature-extract=false main-q-capacity=30000 aux-q-capacity=400000 CPU-Threads=8 cuda-control-threads=3 cuda-worker-threads=5 実行ファイル: batched-wav-nnet3-cuda |
| CUDA* | ドライバーバージョン: 418.87、 CUDA* バージョン: 10.0 |
|
| インテルのデコーダー・ライブラリー | OpenVINO™ ツールキットの 将来のリリースで提供予定 |
| ハードウェア構成 | インテル CPU | NVIDIA* GPU |
|---|---|---|
| プラットフォーム | S2600WFS | Amazon EC2* |
| ノード数 | 2 | 1 |
| CPU | インテル® Xeon® Gold 6252 プロセッサー @ 2.10GHz | インテル® Xeon® プロセッサー E5-2686 v4 @ 2.30GHz |
| ソケットごとのコア数とスレッド数 | 24/24 | 4/8 |
| ucode | 0x4000013 | 0xb000037 |
| インテル® ハイパースレッディング・テクノロジー | 無効 | 有効 |
| インテル® ターボ・ブースト・テクノロジー | 有効 | 有効 |
| BIOS バージョン | SE5C620.86B.0D.01.0286.011120190816 | 4.2、Amazon EC2* |
| システム DDR メモリー構成 | 12 スロット / 16GB / 2933MHz | 4 / 16384MB / 不明 RAM |
| ノードごとの合計メモリー (DDR + DCPMM) | 192GB | 128GB |
| NIC | インテル® イーサネット X527DA2OCP | Amazon.com, Inc. Elastic Network Adapter (ENA) |
| PCH | インテル® C620 | 不明 |
| その他の HW (アクセラレーター) | – | Tesla* V100-SXM2-16GB、 |
| OS | CentOS* 7 | Ubuntu* 16.04.6 LTS |
| カーネル | 3.10.0-957.10.1.el7.x86_64 | 4.4.0-1092-aws |
Intel、インテル、Intel ロゴ、Xeon、OpenVINO、VTune は、アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
© Intel Corporation
