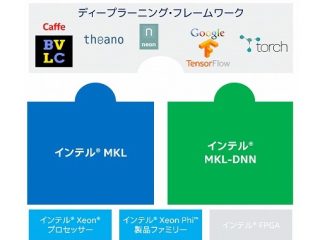
 インテル® oneDAL
インテル® oneDAL インテル® ライブラリーによるディープラーニングとマシンラーニングの促進
このセッションは、インテル® デベロッパー・ゾーンに公開されている「Accelerating Deep Learning and Machine Learning with Intel Libraries」( の日本語版です。 インテルは、...
 インテル® oneDAL
インテル® oneDAL 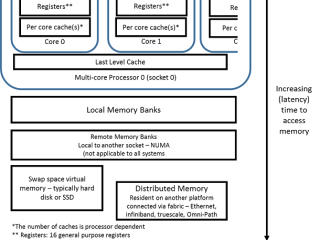 HPC
HPC  インテル® DPC++/C++ コンパイラー
インテル® DPC++/C++ コンパイラー  HPC
HPC  インテル® oneMKL
インテル® oneMKL  インテル® oneDAL
インテル® oneDAL  HPC
HPC  HPC
HPC 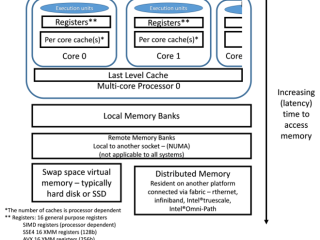 HPC
HPC 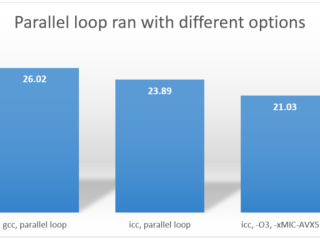 インテル® ディストリビューションの Python*
インテル® ディストリビューションの Python*  インテル® DPC++/C++ コンパイラー
インテル® DPC++/C++ コンパイラー  インテル® Advisor
インテル® Advisor 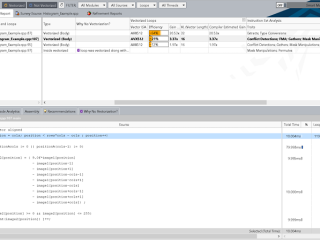 インテル® Advisor
インテル® Advisor 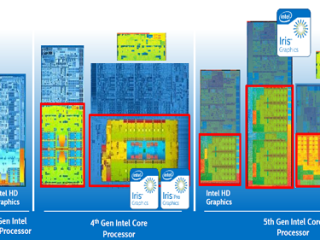 インテル® SDK for OpenCL* Application インテル® Advisor
インテル® SDK for OpenCL* Application インテル® Advisor 