 インテル® oneDAL
インテル® oneDAL インテル® DAAL を使用した Python* ナイーブベイズ・アルゴリズムのパフォーマンス向上
この記事は、インテル® デベロッパー・ゾーンに公開されている「Using Intel® Data Analytics Acceleration Library to Improve the Performance of Naïve Baye...
 インテル® oneDAL
インテル® oneDAL 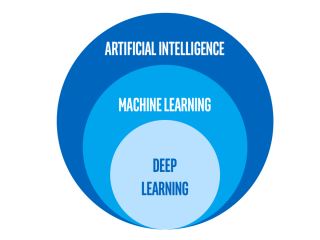 AI
AI  AI
AI 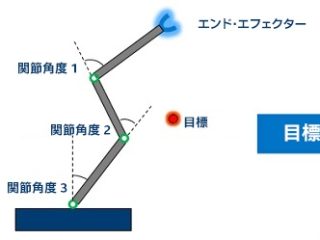 OpenVINO™ ツールキット
OpenVINO™ ツールキット  AI
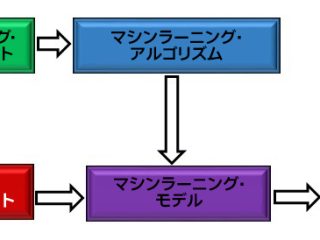
AI 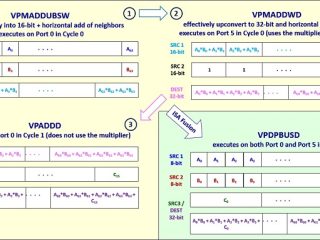 マシンラーニング
マシンラーニング  AI マシンラーニング
AI マシンラーニング 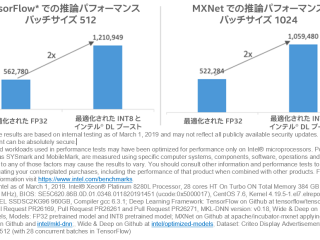 マシンラーニング OpenVINO™ ツールキット
マシンラーニング OpenVINO™ ツールキット  AI
AI 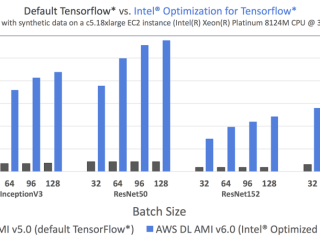 インテル® oneMKL
インテル® oneMKL 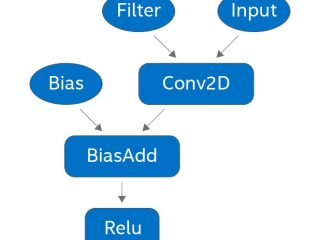 インテル® oneMKL
インテル® oneMKL 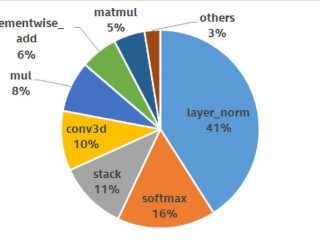 インテル® oneMKL
インテル® oneMKL 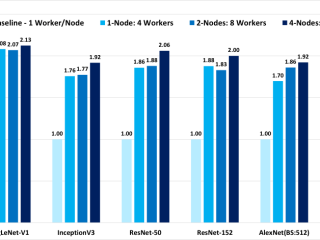 マシンラーニング
マシンラーニング 