

この記事は、Dr.Dobb’s に掲載されている「Understanding Parallel Performance」の日本語参考訳です。
著者紹介: Herb Sutter 氏 - ソフトウェア開発トピックにおいてベストセラー著者でコンサルタント。また Microsoft 社でソフトウェア・アーキテクトを務める。コンタクト先: www.gotw.ca
編集注記:
本記事は、2012 年 6 月 11 日に公開されたものを、加筆・修正したものです。
この記事は並列プログラミングに取り組む開発者が、最初に取り組むべき課題と解決方法が明確に示されています。記事の初出は 2011 年ですが、現代でも十分に当てはまる内容です。
並列パフォーマンスの理解: どうしたら並列パフォーマンスが妥当であるか判断できるのか?
例えば、うまくコードを記述して、分割統治アルゴリズムや並行データ構造、並列トラバースなど、理論上はコードのスケーラビリティーを格段に向上させると言われるあらゆる技法を適用したとしよう。でも実際にこれがどの程度成果があったのか、どうやったら判断できるだろうか?
本当にこれが分かるのだろうか? それとも、クアッドコアで何種類かのテストを行い妥当な結果であれば、それで “良し” としているだけだろうか? コードのパフォーマンスを理解し、コードがスケーリングするかどうかを把握するだけでなく、さまざまな状況とワークロードでパフォーマンスを数値化するため、測定しなければならない重要な要素とは何だろう? 並行性のどのようなコストを考慮しなければならないのだろうか?
ここでは、並列コードの真のパフォーマンスを正確に解析するために注意しなければならないポイントについてまとめよう。いくつかの基本的な考慮事項と、共通するコストについてリストする。
基礎原理
コードのスケーラビリティーを理解するには、何を測定すべきか、また結果のどこに注目すべきか知る必要がある。まず始めに、ワークロード - 主な作業とデータの種類 - を特定する。例えば、異なる数の生産スレッドと消費スレッドで生産-消費システムのパフォーマンスを測定したり、異なるサイズのデータ項目でコンテナーのスケーラビリティーを測定してみる。
次に、耐久テストを行い、それぞれの値を変更することで、スループットまたは単位時間あたりに実行される作業量にどのような変化があるか測定する。これにより、相対的な影響を測定できる。ハードウェア・リソースの追加 (コア数の増加) によるスケーラビリティーの動向、スループットの変化に注目して、より多くのコアを効率良く使用することで、さらに速く解が得られるか、またはより多くの作業量を実行できるか考えてみよう。
図 1 と 2 は、コードの並列パフォーマンスを理解するのに役立つ 2 つの視覚化ツールである。
図 1 はサンプルの分散グラフで、選択済みアルゴリズムにおける 2 種類のワーカー (生産スレッドと消費スレッド) とそのスループットを示している。丸が大きいほど、スループットが良いことを表している。スループットがどこでどのように多くなったり小さくなったりするかを検証することで、このアルゴリズムがどのように、そしてどの方向にスケーリングするか判断できる。このサンプルでは、約 15 スレッドまではスケーラビリティーが増加し、またシステムで消費スレッドより生産スレッドがいくらか多いほうが良いスケーラビリティーを示していることが分かる。
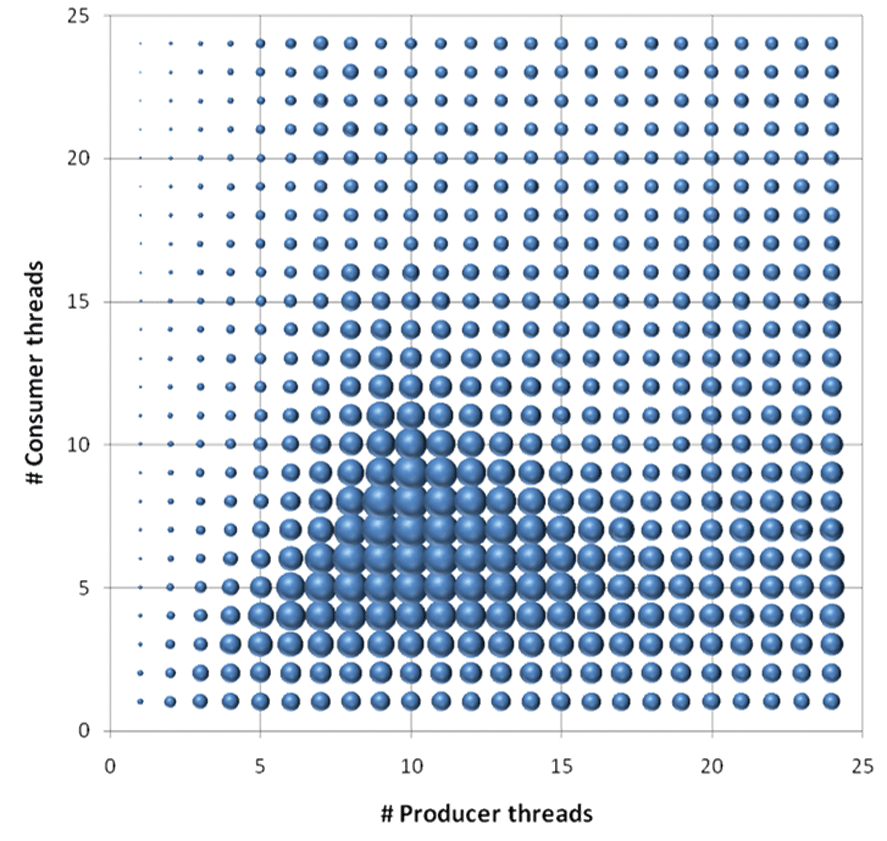
図 2 は、同じ種類のワークロードを実行するさまざまなアルゴリズムを比較している。スループットのピークは、ご覧のとおり、各カーブの頂点である。頂点に達するまで急激に上昇するほど、そして頂点がより右よりにあるほどスケーラビリティーが高いといえる。ここで、青のアルゴリズムは、コア数が増加するとスループットが減り、スケーラビリティーが低下する最悪のケースである。これは、問題外といえるだろう。
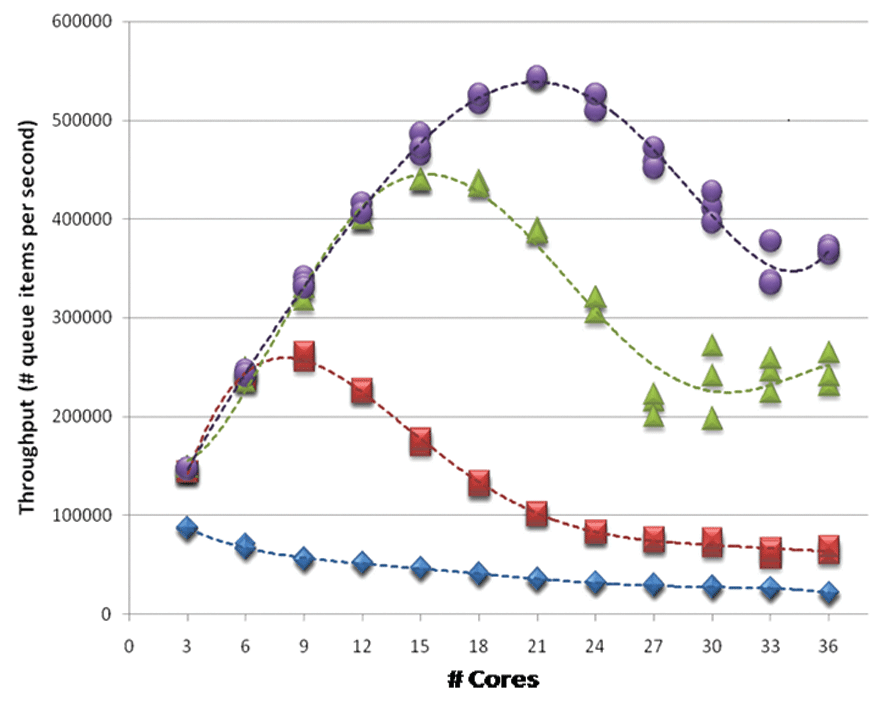
両図から基本的な 2 つの問題が見てとれる。1 つ目の問題は、異なるワーカーがリソースを奪い合う競合である (mutex、キャッシュスペース、またはフォルス・シェアリングによりキャッシュラインを競うなど)。最も極端なケースでは、新しいワーカーを 1 つ追加すると、競合による多くのコストが発生し、結果としてトータルではより少ない作業しか実行されなくなる。
実際、これらのグラフでそれを確認できる。図 1 では、いくつかの方向で、ワーカーの追加によりトータル・スループットが低下するエリアがある。図 2 では、右側の下向き部分で、ほかにアイドルコアがあっても、作業の追加がスループットを低下させる同じ影響が見てとれる。しかし、図 2 の方が明確に競合の影響を示している。頂点の手前では、スループットは向上しているものの、上昇率が鈍化していることが分かる。これは、競合の増加による典型的な影響である。
もう 1 つの問題はオーバーサブスクリプション、または CPU にバインドされた実行準備が整った作業が利用可能なハードウェア数以上ある点だ。このサンプルは、24 コアを搭載したマシンでテストされている。図 1 では、#生産スレッド + #消費スレッド = 24 の場合にスループットが著しく小さくなっている。結果が劇的に良くない箇所もある。同様に、図 2 では、最良のアルゴリズムでも利用可能なコア数を超えるとスケーリングしないことが分かる。また、利用可能なコア数を超えると、少なくとも CPU 時間で競合が発生し、多くの場合はその他のリソースでも競合が発生する。
これらの基礎原理を踏まえて、競合、オーバーサブスクリプション、その他の影響により発生し、スケーラビリティーに影響するいくつかのコストについて考えてみよう。
オーバーヘッドの原因と、スレッドとスレッドプールの比較
コードを並列に表現するだけで並行化によるオーバーヘッドが発生する。3 つの独立したサブ計算を行う次のサンプルについて考えてみよう。
// Example 1: Sequential code in MyApp 1.0
//
int NetSales() {
int wholesale = CalcWholesale();
int retail = CalcRetail();
int returns = TotalReturns();
return wholesale + retail - returns;
}
このコードは全体が CPU に依存しており、サブ計算は独立していて、互いに影響を及ぼさないと仮定する。そのため、サブ計算部分を並列に実行することで、より多くのコアを活用し解をより速く得ることができる。以下は、ラムダ関数を使用してこの方法を表した擬似コードである。しかし、このコードにはよくあるミスが内在する。
// Example 2 (flawed): Naïve parallel code for MyApp 2.0?
//
int NetSales() {
// perform the subcomputations concurrently
future<int> wholesale = new thread( [] { CalcWholesale(); } );
future<int> retail = new thread( [] { CalcRetail(); } );
future<int> returns = new thread( [] { TotalReturns(); } );
// now block for the results
return wholesale.value() + retail.value() - returns.value();
}
通常、コードで new Thread と明示的に指定するとスケールしないコードとなる。多くの環境では、スレッドプールを使用せずに、作業ごとに新しいスレッドを作成した場合、効率性が低下する - まず、毎回新しいスレッドの作成と破棄を行うと、既存のスレッドプールへ作業を渡すより大幅にオーバーヘッドが発生する。次に、現在利用可能なコア数より多くの作業がある場合、多くのスレッドを作成し、オペレーティング・システムのスケジューラーを通して利用可能なコアを自由に取得させると、不要な競合が起こる。これは、コア数の少ないハードウェアだけで発生するわけではなく、アプリケーションやシステムが多くのほかの作業を実行していると、メニーコア・ハードウェアでも発生する。
この 2 つの状況は異なる種類のオーバーサブスクリプションだ。いくつかのスレッドは、利用可能なコアにインターリーブするためにより多くのコンテキストスイッチが必要になる。それよりも複数のスレッドで同じコアを共有したほうが、効率がいいだけでなく、キャッシュ・フレンドリーといえる。
スレッドプールはこのような問題に対処している。なぜなら、プールは、マシンで並行動作可能なハードウェアに対して “最適なサイズ” になるよう設計されているからだ。プールは、自動で 1 コアにつき 1 つのアクティブなスレッドを維持しようと試みる。そして、コア数以上の作業量がある場合は、作業をキューに追加し、利用可能なコア数と同等のタスクの実行を行う。以下が、プールを使用した擬似コードである。
// Example 3 (better): Partly fixed parallel code for MyApp 2.0
//
int NetSales() {
// perform the subcomputations concurrently
future wholesale = pool.run( [] { CalcWholesale(); } );
future retail = pool.run( [] { CalcRetail(); } );
future returns = pool.run( [] { TotalReturns(); } );
// now block for the results
return wholesale.value() + retail.value() - returns.value();
}
このコードの良い点は、より多くのコア、少なくとも 3 つのコアまではより速く解が得られることだ。しかしながら、コストも発生する。現在のスレッドプールでは、通常、2 つのコンテキストスイッチ - スレッドプールへ作業を渡すときと結果を受け取るとき - が必要になる。どのようにこのコストを軽減できるだろうか?
