

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Optimize Data Structures and Memory Access Patterns to Improve Data Locality」(http://software.intel.com/en-us/articles/optimize-data-structures-and-memory-access-patterns-to-improve-data-locality/) の日本語参考訳です。
編集注記:
本記事は、2011 年 5 月 4 日に公開されたものを、加筆・修正したものです。
はじめに
キャッシュとは、最も頻繁に使用されるメモリー位置のコピーが格納される小さく高速なプロセッサー内部のメモリー・サブシステムで、近年のプロセッサーにおいて最も重要なリソースの 1 つです。命令が必要とするデータがキャッシュにある場合、その命令はわずかなレイテンシーで実行できます。そうでない場合、命令はメモリーから必要なデータが読み込まれるまで、実行を保留しなければなりません。メモリーからデータをコピーする操作はレイテンシーが長いため、データの局所性を活用するようアルゴリズムとデータ構造を設計し、キャッシュミスを最小に抑えると良いでしょう。
この記事では、データの局所性が低い場合の兆候、関連するパフォーマンス・ボトルネックの検出手法、問題の解決につながる最適化について説明します。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
背景
データの局所性の問題とその影響を示す典型的な例として、行列乗算アルゴリズムが挙げられます。まず、C[] += A[] * B[]; という式に従って、正方行列 A と B の乗算を行い、その結果を行列 C に格納するアルゴリズムのシリアルバージョンから見てみましょう。行列は行優先で配列に格納され、各行列のサイズはかなり大きなもの (NxN) になります。

これは、計算負荷の高いアルゴリズムの例です。このアルゴリズムには、ほかの多くのアルゴリズムと共通の次のような特徴があります。
- 入れ子になった for ループを使用している
- 大きなデータを操作する。
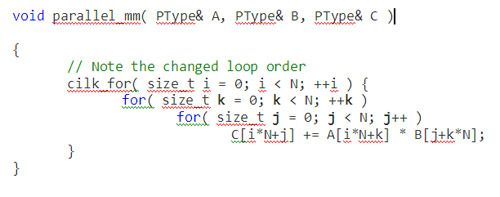
また、このほかにも、外側のループの反復は独立しており、並列化の候補として最適と考えられる、といった特徴もあります。以下に、インテル® Cilk™ Plus を使用して実装したこのアルゴリズムの並列バージョンを示します (これは、シリアルバージョンのキーワード for をインテル® Cilk™ Plus の cilk_for に置換し、インテル® Cilk™ Plus 言語拡張をサポートしているインテル® コンパイラーを使用しただけです)。インテル® Cilk™ Plus のサポートは終了しています。

大きな行列を使ってこの並列バージョンと最初のシリアルバージョンのパフォーマンスを比較したところ、実際には並列バージョンのほうが遅いことが分かりました。
これは、高レベルの解析では問題の原因を特定できないケースの一例です。実際、インテル® VTune™ Amplifier XE 2011 のコンカレンシー解析を実行してみたところ、時間のかかる関数 (parallel_mm) の実行中のコンカレンシー・レベルが低いことは分かりましたが、その原因は分かりませんでした。最新のインテル® VTune™ プロファイラーではスレッド化解析を使用します。
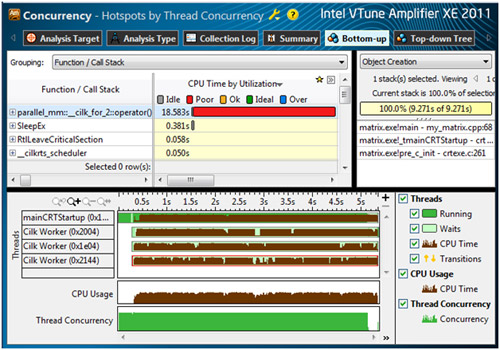
インテル® VTune™ Amplifier XE では、パフォーマンス統計をタイムライン・ビューで表示することができるという特徴があります。タイムライン・ビューにより、実行時間全体を通してアプリケーションのワーカースレッドとその動作を確認することができます。
前述の行列乗算プログラムに対してコンカレンシー解析を行ったところ、インテル® VTune™ Amplifier XE は、メインスレッドのほかにインテル® Cilk™ Plus のランタイムシステムにより生成される 3 つのワーカースレッド (これらはタイムライン・ビューでは “Cilk Worker” と示されます) と、実行時間全体を通したワーカースレッドごとの CPU 時間の使用状況 (これはタイムラインに茶色で示されます) を検出しました。コンカレンシー解析により収集されたデータから、ワーカースレッドの CPU 使用率が非常に低く、アルゴリズムの実行全体を通して CPU 時間が大量に消費されていることが判明しました。
低コンカレンシーの原因を追究するための次のステップは、インテル® VTune™ Amplifier XE でサポートされている低レベルのプロファイラーを実行することです。
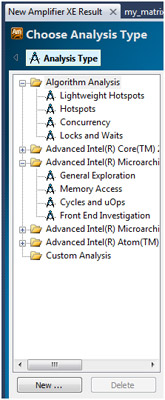
インテル® VTune™ Amplifier XE は、イベント・ベース・サンプリング (EBS) に基づく低レベルの解析タイプ (ライト Hotspot 解析と”高度な解析”グループ以下のいくつかの解析タイプ) をサポートしています。EBS 解析の目的は、プロセッサーに内蔵される PMU (パフォーマンス・モニタリング・ユニット) と呼ばれる特殊なレジスターのサンプリングを行い、ハードウェア・イベントを収集することです。PMU レジスターの値は、特定のハードウェア・イベント (例えば、分岐予測ミスやキャッシュミスなど) が発生したらインクリメントするようにプログラムすることができます。
プロセッサーはさまざまなイベントを生成します。そのうちの 1 つまたは 1 グループだけを見ても、プロファイラーによって示された数値が実際にパフォーマンス低下の原因であるかどうかは明らかでないため、あまり役に立たない場合があります。通常、アプリケーションに特定のパフォーマンス問題が存在するかどうかを判断するには、適切なイベントと特定の式を組み合わせて使用する必要があります。初めて低レベルのプロファイラーを実行する場合や、どのような問題に注目すべきか分からない場合は、”General Exploration (全般解析)” から始めると良いでしょう。
“General Exploration (全般解析)” とは事前に定義されている解析の 1 つで、複数のハードウェア・イベントを収集し、多数の式を使います。これは、アプリケーションにどのような問題が存在するかを把握するのに役立ちます。インテル® VTune™ Amplifier XE は、ハードウェア・イベントを収集し、いくつかの式を適用した結果のデータを示し、パフォーマンス問題の可能性がある数値をハイライトします。すべてのイベントと式の詳細な説明はインテル® VTune™ Amplifier XE ヘルプを、簡単な説明はツールヒントを参照してください。
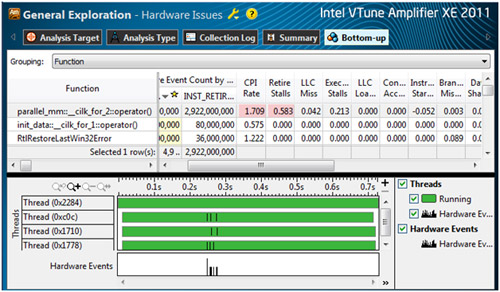
前述の行列乗算プログラムに対して “General Exploration (全般解析)” を行ったところ、いくつかのパフォーマンス・ボトルネック (ピンクのセル) が見つかりました。
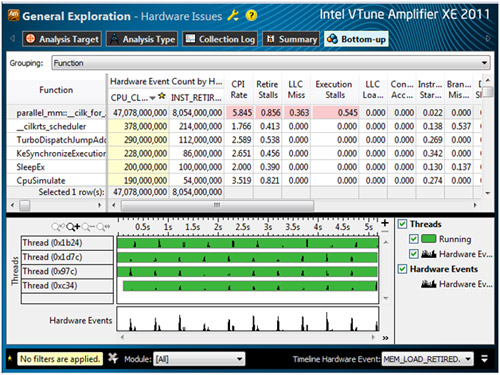
- CPI Rate (CPI レート): 1 命令あたりの CPU サイクル数の平均。1 以下が理想的ですが、このプログラムでは 5 を超えています。
- Retire Stalls (リタイアストール): すべてのサイクルに対してマイクロオペレーションがリタイアされなかったサイクルの比率。長いレイテンシーの操作や依存関係チェーンがない場合、1 以上になります。このプログラムでは約 0.8 です。
- LLC Miss (LLC ミス): すべてのサイクルに対して LLC (最終レベルキャッシュ) ミスが未処理のサイクルの比率です。LLC のメモリー要求ミスは、レイテンシーの長いローカルまたはリモート DRAM によって処理されます。できるだけ 0 に近いのが理想的です。
- Execution Stalls (実行ストール): すべてのサイクルに対してマイクロオペレーションが実行されなかったサイクルの比率。実行ストールは、クリティカルな演算リソースの待機によって発生します。
インテル® VTune™ Amplifier XE の解析結果から、高い LLC ミスが原因でローカルまたはリモート DRAM からデータがフェッチされるのを待機するのに多くの CPU 時間が費やされていることが判明しました。問題の関数を再度確認する際に、インテル® VTune™ Amplifier XE ではその関数のソースビューを表示し、ソース行ごとのハードウェア・イベントの状況を確認できます。この例では、ほとんどのサンプルが最も内側の for ループで報告されています。
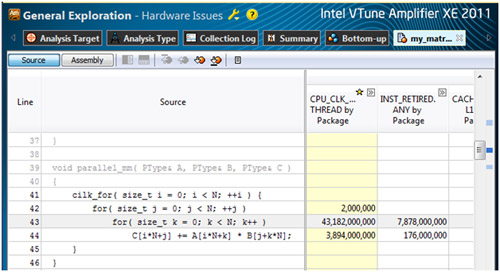
i = 0、j = 0 の場合の parallel_mm 関数のデータ・アクセス・パターンを見てみましょう。
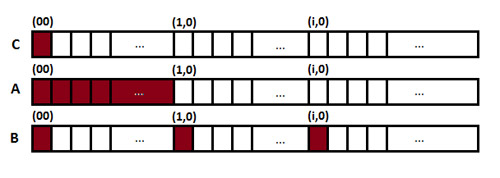
最も内側のループにおいて、各反復は行列 A の要素にアクセスしていますが、この要素はその前の反復でアクセスされる要素の近くにあるため、これはデータの局所性を利用した効率的なアクセスパターンといえます。一方、行列 B のアクセスパターンは効率的とはいえません。各反復において、プログラムは k 列の j 番目の要素にアクセスしなければなりません。これは k が内側のループカウンターであるためです。この効率の悪いデータ・アクセス・パターンはキャッシュミスを増加させ、これこそがプログラムのパフォーマンス低下の原因といえます。
このアルゴリズムのもっと効率の良い実装方法について考えてみましょう。コードを少し変更するだけで、データ・アクセス・パターンを劇的に改善することができます。
内側の 2 つのループを交換するだけで、データの局所性が向上します (以下は、i=0、k=0 の場合のアクセスパターン)。
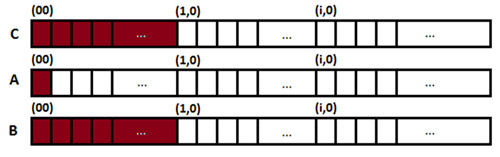
この新しい実装では、それぞれの i (外側のループのカウンター) に対して、行列 A と B の連続する要素にだけアクセスし、行列 C のすべての行を計算します。この変更は、CPI を向上させ、LLC ミスを減らすことで、パフォーマンスが大幅に向上します。
アドバイス
インテル® VTune™ Amplifier XE には、プログラムのパフォーマンス・ボトルネックを発見するのに役立つ便利な機能がたくさんあります。高レベルの解析タイプは通常アルゴリズムの最適化に役立ち、低レベルの解析タイプはアプリケーション実行中のプロセッサーの動作を理解するのに役立ちます。近年のプロセッサーは非常に複雑で、エキスパートでなければ低レベルのパフォーマンス解析を行うことは難しいでしょう。インテル® VTune™ Amplifier XE の理念は、低レベルのパフォーマンス解析を単純にし、誰もが簡単に行えるようにすることです。高レベルの解析タイプでは問題の原因が分からない場合、インテル® VTune™ Amplifier XE の General Exploration (全般解析) を実行してみてください。次に行うべきことや問題を絞り込むためのヒントが得られるかもしれません。
この記事では、データの局所性に関する問題の一例を説明しました。この例では、アルゴリズムを変更することでデータの局所性とパフォーマンスを向上させることができました。しかし、データの局所性が低い原因がデータ構造そのものにある場合、データのレイアウトを変更しなければ、データの局所性を向上させることは不可能です。この場合も、インテル® VTune™ Amplifier XE で同じ兆候 (低コンカレンシー・レベル、高い CPI、高いキャッシュ・ミス・レート) が検出されます。
優れたパフォーマンスとスケーラビリティーを得るためには、データの局所性を考慮してデータ構造とアルゴリズムを設計する必要があります。データの局所性を高めることで、シリアル・アプリケーションだけでなく、並列アプリケーションでもその利点が得られます。
利用ガイド
パフォーマンス解析は繰り返し作業です。インテル® VTune™ Amplifier XE の解析機能を使用する際は、コード変更後に再度その解析を実行してください。インテル® VTune™ Amplifier XE には自動比較機能があるため、2 つの実行のプロファイルを比較し、進捗状況を追跡することができます。
この記事では “General Exploration (全般解析)” について説明しました。General Exploration (全般解析) の目的は、低レベルのパフォーマンス解析への取りかかりを提供することです。その次のステップとして、調査が必要なパフォーマンス・ボトルネックの種類が判明したり、あるいは特定の詳細情報が必要になったら、より個別の解析 (“メモリーアクセス”、”サイクルとマイクロオペレーション” など) を行います。
注
ここで説明するインテル® VTune™ Amplifier XE 2011 の機能は、以降のインテル® VTune™ Amplifier やインテル® VTune™ プロファイラーでも使用できます。
