

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Curing Thread Imbalance Using Intel® Parallel Amplifier」(http://software.intel.com/en-us/articles/curing-thread-imbalance-using-intel-parallel-amplifier/) の日本語参考訳です。
編集注記:
本記事は、2011 年 5 月 4 日に公開されたものを、加筆・修正したものです。
はじめに
マルチスレッド・アプリケーションのパフォーマンスを制限する要因の 1 つに、ロード・インバランスがあります。スレッド間でワークロードのバランスをとることは、アプリケーションのパフォーマンスにとって非常に重要です。ロード・バランシングの主要な目的は、各スレッドのアイドル時間を最小化して、すべてのスレッドで均等になるようにワークロードを分散し、ワークシェアリングのオーバーヘッドを最小限に抑えることです。インテル® Parallel Studio に含まれるインテル® VTune™ Amplifier は、マルチコア・プロセッサーで最適なパフォーマンスを発揮できるように、並列アプリケーションのきめ細かな調整を支援します。インテル® VTune™ Amplifier は、マルチコアにおけるパフォーマンス・ボトルネックを素早く検出して、開発者が問題の識別と修正を迅速に行えるようにします。完璧なロードバランスの達成は容易ではなく、アプリケーション内の並列処理、ワークロード、スレッド化の実装に依存します。インテル® VTune™ Amplifier の後継製品であるインテル® VTune™ プロファイラーも同様の機能を持ちますが、より高度な解析ができます。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
背景
一般に、独立したタスク (ワークロード) のマッピングやスケジューリングは 2 つの方法 (静的および動的) で行われます。すべてのタスクが同じ長さの場合、単に利用可能なスレッド間でタスクを静的に分割する (タスクの総数をほぼ同じ長さのグループに分割して各スレッドに割り当てる) のが最良のソリューションです。個々のタスクの長さが異なる場合、スレッドにタスクを動的に割り当てるほうが良い結果が得られます。
インテル® VTune™ Amplifier のスレッド解析は、アプリケーションが利用可能なコアをどのように活用しているかを測定します。解析中に、インテル® VTune™ Amplifier は、アクティブなスレッド (実行中のスレッド、またはキューに追加されたスレッドのうち、待機 API やブロック API で待機していないもの) の数を収集して、その情報を表示します。実行中のスレッド数は、アプリケーションのコンカレンシー・レベルに対応します。コンカレンシー・レベルとプロセッサー数を比較することにより、インテル® VTune™ Amplifier は、アプリケーションが利用可能なプロセッサーをどのように使用しているか分類します。
ここでは、C で記述したサンプルプログラムを使用して、インテル® VTune™ Amplifier がどのようにホットスポットとロード・インバランスの問題を検出するかを説明します。このプログラムは、3 次元の距離に基づいて質点系の位置エネルギーを計算します。Win32* ネイティブスレッドを使用したマルチスレッド・アプリケーションで、NUM_THREADS 変数で指定した数のスレッドを生成します。この記事では、Win32* スレッドやスレッド化の手法、そしてスレッド化の実装方法については説明していません。インテル® VTune™ Amplifier がロード・インバランスの検出やスケーラブルな並列アプリケーションの開発にどのように役立つかについてのみ説明しています。
for (i = 0; i < NUM_THREADS; i++)
{
bounds[0][i] = i * (NPARTS / NUM_THREADS);
bounds[1][i] = (i + 1) * (NPARTS / NUM_THREADS);
}
for (j = 0; j < NUM_THREADS; j++)
{
tNum[j] = j;
tHandle[j] = CreateThread(NULL,0,tPoolComputePot,&tNum[j],0,NULL);
}
DWORD WINAPI tPoolComputePot (LPVOID pArg) {
int tid = *(int *)pArg;
while (!done)
{
WaitForSingleObject (bSignal[tid], INFINITE);
computePot (tid);
SetEvent (eSignal[tid]);
}
return 0;
}
各スレッドで並列実行されるルーチン computePot を下記に示します。各スレッドは、スレッドの割り当て識別番号 (tid) でインデックスされた境界を用いて、計算する質点の開始 (start) と終了 (end) を決定します。各スレッドは、反復空間 (start から end) を初期化した後、質点の位置エネルギーの計算を開始します。
void computePot (int tid) {
int i, j, start, end;
double lPot = 0.0;
double distx, disty, distz, dist;
start = bounds[0][tid];
end = bounds[1][tid];
for (i = start; i < end; i++)
{
for (j = 0; j < i-1; j++)
{
distx = pow ((r[0][j] - r[0][i]), 2);
disty = pow ((r[1][j] - r[1][i]), 2);
distz = pow ((r[2][j] - r[2][i]), 2);
dist = sqrt (distx + disty + distz);
lPot += 1.0 / dist;
}
}
gPot[tid] = lPot;
}
ホットスポット解析でアプリケーションのホットスポットを検出できるため、開発者は適切な関数を作成することに集中できます。このアプリケーションの合計経過時間は、インテル® Core™2 Quad プロセッサーを搭載したシングルソケット・システムで約 15.4 秒です。ホットスポット解析では、computePot ルーチンがメインのホットスポットで、CPU 時間のほとんど (23.331 秒) を費やしていることが分かります。関数 computePot のソースにドリルダウンすると、ホットスポットの詳細な内容が表示されます (図 1)。
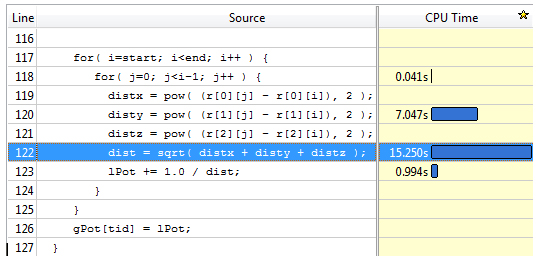
図 1. ホットスポット解析の [Sources (ソース)] ビュー
スレッド解析では、同じルーチンの CPU 使用率が poor で (図 2)、アプリケーションは平均 2.28 コアを使用していることが分かります (図 3)。メインのホットスポットではすべての利用可能なコアが利用されていないため、ほとんどの時間で CPU 使用率は poor (1 コアのみ使用) か OK (2 ~ 3 コアを使用) のいずれかになっています。次に、CPU 使用率が poor の原因となっているロード・インバランスがあるかどうかを調べます。最も簡単な方法は、図 4 で示されているように、新しい粒度として [Function-Thread-Bottom-up Tree (関数-スレッド-ボトムアップ・ツリー)] または [Thread-Function-Bottom-up Tree (スレッド-関数-ボトムアップ・ツリー)] を選択することです。
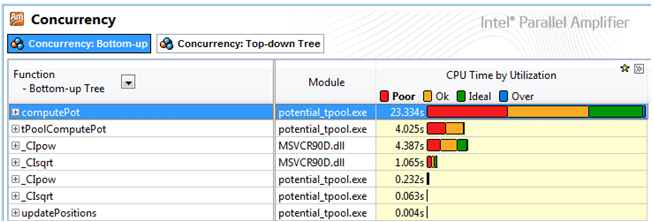
図 2. スレッド解析結果
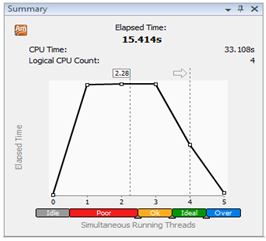
図 3. スレッド解析結果の [Summary (サマリー)] ビュー
スレッド解析結果の時間は、以下の使用率の種類に対応しています。
- Idle
 : プログラムのすべてのスレッドが待機中です。実行中のスレッドはありません。
: プログラムのすべてのスレッドが待機中です。実行中のスレッドはありません。 - Poor
 : デフォルトでは、スレッド数がターゲット・コンカレンシーの 50% 以下の状態です。
: デフォルトでは、スレッド数がターゲット・コンカレンシーの 50% 以下の状態です。 - OK
 : デフォルトでは、スレッド数がターゲット・コンカレンシーの 51% ~ 85% の状態です。
: デフォルトでは、スレッド数がターゲット・コンカレンシーの 51% ~ 85% の状態です。 - Ideal
 : デフォルトでは、スレッド数がターゲット・コンカレンシーの 86% ~ 115% の状態です。
: デフォルトでは、スレッド数がターゲット・コンカレンシーの 86% ~ 115% の状態です。
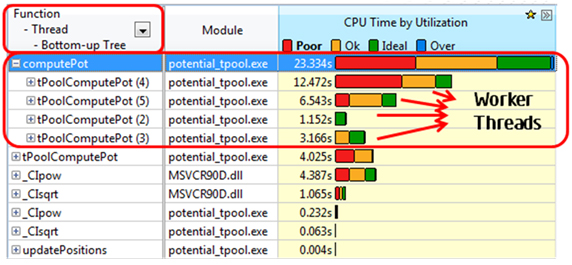
図 4. スレッド解析結果で [Function-Thread (関数-スレッド)] グループを表示
図 4 を見ると、このルーチンを並列に実行している 4 つのワーカースレッドが同量の作業を行っていないためにロード・インバランスが発生し、CPU 使用率が poor になっていることが分かります。この状態では、マルチスレッド・アプリケーションは適切にスケーリングされません。ソースコードをよく見ると、メインルーチン内の外側のループがスレッドプール内に生成されるワーカースレッドの数に基づいて質点の反復を静的に分割していることが分かります (start = bounds[0][tid], end = bound[1][tid])。このルーチン内の内側のループは、終了条件として外側のインデックスを使用しているため、外側のループでより大きな質点数が使用されると、内側のループでより多くの反復が実行されます。その結果、質点の各ペアが位置エネルギーの計算に一度しか利用されず、異なる計算量が割り当てられていることがロード・インバランスの原因です。
このロード・インバランス問題を解決する 1 つの方法は、スレッドに対して質点をより動的に割り当てることです。例えば、オリジナルバージョンのように、質点の連続するグループを割り当てるのではなく、各スレッドをスレッド id (tid) でインデックスされた質点から開始すると、質点番号がスレッド番号と異なるすべての質点を計算できます。例えば、2 つのスレッドを使用する場合、1 つのスレッドで偶数番号の質点を処理して、別のスレッドで奇数番号の質点を処理します。
void computePot(int tid) {
int i, j;
double lPot = 0.0;
double distx, disty, distz, dist;
for(i=tid; i< NPARTS; i+= NUM_THREADS ) { // <-for( i=start; i< end; i++ )
for(j=0; j< i-1; j++) {
distx = pow( (r[0][j] - r[0][i]), 2 );
disty = pow( (r[1][j] - r[1][i]), 2 );
distz = pow( (r[2][j] - r[2][i]), 2 );
dist = sqrt( distx + disty + distz );
lPot += 1.0 / dist;
}
}
gPot[tid] = lPot;
この変更を行った後のスレッド解析では、ホットスポットになっていた関数がすべての利用可能なコアを使用していることが分かります (図 5)。
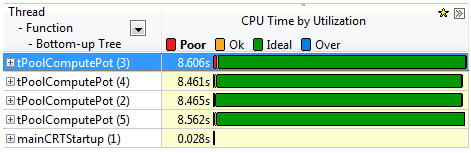
図 5. 変更後のコンカレンシー解析結果
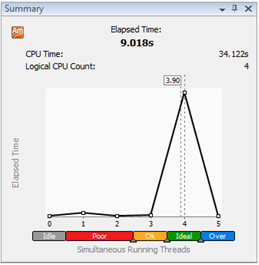
図 6. ロードのバランスが取れたバージョンの [Summary (サマリー)] ビュー
サマリーとスレッド解析結果から分かるように、変更後のアプリケーションはほぼすべての利用可能なコアを使用しており、シリアルコードのセグメント (使用率が poor) と使用されていないセグメントがなくなっています。
推奨事項
スレッド化の手法はさまざまで、スレッドに対するタスクの分配を制御する方法は手法によって異なります。一般的なスレッド化手法を以下に示します。
- 明示的またはネイティブなスレッド化手法 (Win32* や POSIX* スレッドなど)
- スレッドの抽象化
明示的なスレッド化手法 (Win32* や POSIX* スレッドなど) では、独立したタスクをスレッドに自動的にスケジュールする方法がないため、必要に応じてその機能をアプリケーションに実装する必要があります。この例で示しているように、タスクの静的スケジューリングは単純です。動的スケジューリングでは、生産者/消費者とボス/ワーカーの 2 つの関連するモデルを容易に実装できます。前者は、1 つまたは複数の生産者スレッドがタスクをキューに入れ、必要に応じて消費者スレッドがタスクをキューから取り出して処理します。必須ではありませんが、生産者/消費者モデルではタスクが消費者スレッドで利用できるようになる前に前処理を行います。ボス/ワーカーモデルでは、ワーカースレッドは処理がある場合は常にボススレッドを待ち、直接処理の割り当てを受けます。
どちらのモデルを使用する場合でも、正しいスレッド数とスレッドの組み合わせを使用して、計算を行うタスクを処理するスレッドがアイドル状態にならないようにします。単一のボススレッドは、容易にコード化してタスクが適切に分配されることを保証する一方、消費者スレッドがアイドル状態になったときに、消費者の数を減らすか生産者スレッドの数を増やす必要があります。適切なソリューションは、アルゴリズムに加えて、割り当てられるタスクの数と長さによって決まります。
OpenMP* では、ループのワークシェアリング構造に 4 つのスケジューリング手法が用意されています (各手法の詳細な説明は、OpenMP* の仕様を参照してください)。デフォルトでは、反復の静的スケジューリングが使用されます。反復ごとの作業量が変化してパターンが予測できない場合、反復の動的スケジューリングのほうがワークロードのバランスが向上します。
動的スケジューリングを使用すると、フォルス・シェアリングと呼ばれるマイクロアーキテクチャー上の問題が発生することがあります。フォルス・シェアリングは、パフォーマンスを低下させるパターンアクセス問題です。フォルス・シェアリングは、2 つ以上のスレッドが同じキャッシュライン (インテル® アーキテクチャーでは 64 バイト) に繰り返し書き込みを行うと発生します。ワークロードをスレッド間で動的に分配している場合は特に注意が必要です。
インテル® スレッディング・ビルディング・ブロック (インテル® TBB) は、テンプレート・ベースのランタイム・ライブラリーで構成された、ランタイムベースのプログラミング・モデルで、マルチコア・プロセッサーの潜在的なパフォーマンスを活用できるように開発者を支援します。インテル® TBB を利用することで、開発者は、コンカレント・コレクションと並列アルゴリズムを活用して、スケーラブルなアプリケーションを作成できます。ワークスチール・メカニズムによる分割統治スケジューリング・アルゴリズムが提供されるため、開発者はさまざまなスケジューリング・アルゴリズムについて考慮する必要がありません。インテル® TBB は、ワークスチール・メカニズムを利用して、動的にワーカースレッド間のタスクのバランスをとります。
