

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Using AVX Without Writing AVX」の日本語参考訳です。
編集注記:
本記事は、2011 年 5 月 4 日に公開されたものを、加筆・修正したものです。
この記事は、「マルチスレッド・アプリケーションの開発のためのガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
1. 概要とツール
インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) は、インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) の新しい 256 ビット命令セットの拡張で、浮動小数点演算を多用するアプリケーション向けに設計されています。インテル® SSE とインテル® AVX はどちらも、SIMD (Single Instruction Multiple Data) 命令セットを実装しています。インテル® AVX は、第 2 世代インテル® Core™ プロセッサー・ファミリーでサポートされました。より広い 256 ビットのベクトル、新しい拡張可能な命令フォーマット (ベクトル・エクステンションまたは VEX)、豊富な機能により、パフォーマンスを向上させます。
新しい命令セットは、プログラミングの柔軟性を高め、非破壊的ソースオペランドを扱えるように、3 つのオペランドをサポートしています。従来の 128 ビット SIMD 命令も、3 つのオペランドと新しい命令エンコーディング・フォーマット (VEX) をサポートするように拡張されました。この新しい命令エンコーディング・フォーマットでは、より高いレベルの命令を、オペコードとプリフィックスを使用してプロセッサーが解釈するフォーマットで表現します。その結果、画像、オーディオ/ビデオ処理、科学シミュレーション、金融解析、3D モデリングなどの、データ処理および汎用アプリケーションの開発が容易になります。
この記事では、低水準のアセンブリー言語によるコーディングを行うことなく、アプリケーションでインテル® AVX を活用する方法について説明します。C/C++ 開発者がインテル® AVX の機能を活用する最も直接的な方法は、C 互換の組込み関数を使用することです。組込み関数を使用することで、インテル® AVX 命令セットやインテル® Short Vector Math Library (SVML) に含まれる高水準の関数にアクセスできます。これらの関数は、immintrin.h および ia32intrin.h ヘッダーファイルで定義されます。このほかにも、プログラマーがソースコードにインテル® AVX 命令を明示的に追加することなくインテル® AVX を利用できる方法があります。ここでは、インテル® C++ Composer XE 2011 を利用して、開発コード名 Sandy Bridge システムで実行するアプリケーションを生成する方法を示します (最新のコンパイラーでも利用できます)。インテル® C++ Composer XE は、Linux*、Windows*、Mac OS* X プラットフォームをサポートしています。ここでは、Windows* プラットフォームのコマンドライン・オプションを紹介しています。表1 に各プラットフォームのコマンドライン・オプションの対応表を示します。
2. SIMD (Single-Instruction-Multiple-Data) の概念
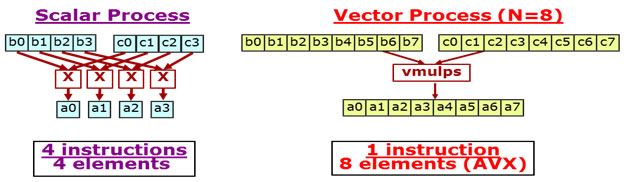
ベクトルまたは SIMD 対応のプロセッサーは、単一命令で複数のデータオペランドを同時に演算することができます。1 つのデータと別のデータを演算して、1 つの結果を生成する操作をスカラー処理といいます。一方、ベクトル処理は、N 個のデータを同時に演算して N 個の結果を生成する操作です (N > 1)。このテクノロジーは、SSE または AVX 命令をサポートしているインテル® プロセッサーおよび互換プロセッサーで利用できます。スカラーからベクトルにアルゴリズムを変換して実装することを、ベクトル化と呼びます。
次の multiplyValues 関数は、インテル® AVX を使用するスカラー処理とベクトル処理の違いを示す一般的な例です。
void multiplyValues(float *a, float *b, float * c, int size)
{
for (i = 0; i < size; i++) {
a[i] = b[i] * c[i];
}
}
3. インテル® AVX 向けに再コンパイル
最初に行うべき手法は、/QaxAVX コンパイラー・オプション (Windows*) を使用して再コンパイルすることです。ソースコードを変更する必要はありません。インテル® コンパイラーは、VEX エンコードされた適切な 128 ビットおよび 256 ビットのインテル® AVX 命令を生成します。複数のインテル® プロセッサー向けに、各プロセッサー固有の自動ディスパッチ・コードパスを生成することもできます。この場合、その中で最も適切なコードがランタイムに実行されます。
4. コンパイラーの自動ベクトル化
適切なアーキテクチャー向けのオプションを使用してアプリケーションをコンパイルするのは、インテル® AVX 対応アプリケーションをビルドする最初のステップです。コンパイラーは、自動ベクトル化が指示されると、開発者に代わりさまざまなベクトル化作業を行います。自動ベクトル化は、一定の条件が満たされたときにコンパイラーが行う最適化です。インテル® C++ コンパイラーは、コード生成に際して自動的に適切なベクトル化を行います。ベクトル化についての詳細は、「インテル® C++ コンパイラーによるベクトル化」 (http://software.intel.com/en-us/articles/a-guide-to-auto-vectorization-with-intel-c-compilers/) を参照してください。インテル® コンパイラーは、最適化レベルが /O2 以上のときにベクトル化を行います。
では、インテル® C++ Compose XE に含まれる簡単な行列ベクトル乗算の例を使用して、ベクトル化の概念を説明しましょう。以下のサンプルコードは、vec_samples アーカイブの Multiply.c に含まれている matvec 関数です。
void matvec(int size1, int size2, FTYPE a[][size2], FTYPE b[], FTYPE x[])
{
for (i = 0; i < size1; i++) {
b[i] = 0;
for (j = 0;j < size2; j++) {
b[i] += a[i][j] * x[j];
}
}
}
ベクトル化を行わない場合、外側のループは size1 回実行され、内側のループは size1*size2 回実行されます。FTYPE が double である場合、/QaxAVX (Windows*) オプションを指定してベクトル化を行うと、演算ごとに単一命令で 4 つの乗算と 4 つの加算が実行されるため、内側のループはアンロールできます。ベクトル化されたループは、スカラーループよりも効率的です。float 型の場合、8 つのオペランドを保持できます。
ループがベクトル化されるには、一定の基準を満たす必要があります。ランタイムでループに入るときに、ループの反復回数が分かっている必要があります。反復回数は変数でもかまいませんが、ループの実行中は一定でなければなりません。ループの入口と出口はそれぞれ 1 つでなければならず、出口が入力データに依存してはなりません。分岐にはいくつかの条件があります (例えば、switch 文は使用できません)。if 文は、マスク割り当てとして実装できる場合は使用できます。最内ループは最も有望なベクトル化の候補です。ループ内で関数呼び出しを使用すると、ベクトル化が制限されます。組込み関数および組込み SVML 関数ではベクトル化される可能性が高くなります。
アプリケーション開発の実装およびチューニング段階でベクトル化の情報を確認することを推奨します。インテル® コンパイラーは、ベクトル化された項目とベクトル化されなかった項目に対してベクトル化レポートを出力できます。レポートを出力するには、/Qvec-report=<n> コマンドライン・オプション (最新のコンパイラーでは、/Qopt-report=<n>) を指定します (n はレポートの詳細レベル)。n が大きくなると、レポートの詳細レベルが高くなります。例えば、n=3 の場合、ベクトル化されたループ、ベクトル化されなかったループと依存性情報が出力されます。開発者は、レポートされた情報に基づいてソースを修正できます。特にループがベクトル化されなかった理由が参考になります。
コンパイラーがベクトル化できない場合でも、開発者がその原因の回避策をコンパイラーに通知することで、ベクトル化が可能になることもあります。プラグマを利用してループを常にベクトル化する、ループ内のデータがアラインされるように指定する、潜在的なデータ依存性を無視する、などの自動ベクトル化処理を支援する追加情報を記述できます。以下の addFloats サンプルには、重要なポイントが含まれています。コンパイラーが何を生成したか、生成されたアセンブリー言語命令を確認することは大切です。/S コマンドライン・オプションを指定すると、インテル® コンパイラーは、現在の作業ディレクトリーにアセンブリー・ファイルを生成します。
void addFloats(float *a, float *b, float *c, float *d, float *e, int n) {
int i;
#pragma simd // (最新のコンパイラーでは #pragma omp simd を推奨)
#pragma vector aligned
for(i = 0; i < n; ++i) {
a[i] = b[i] + c[i] + d[i] + e[i];
}
}
simd プラグマと vector プラグマの使用には注意してください。この 2 つのプラグマは、インテル® AVX で 256 ビットのベクトル化を行う重要な役割を担っています。simd プラグマと vector プラグマを含む行を除く addFloats を、/QaxAVX オプションを指定してコンパイルすると、次のコードが生成されます。
simd プラグマと vector プラグマを使用しない場合
.B46.3::
vmovss xmm0, DWORD PTR [rdx+r10*4]
vaddss xmm1, xmm0, DWORD PTR [r8+r10*4]
vaddss xmm2, xmm1, DWORD PTR [r9+r10*4]
vaddss xmm3, xmm2, DWORD PTR [rax+r10*4]
vmovss DWORD PTR [rcx+r10*4], xmm3
inc r10
cmp r10, r11
jl .B46.3
このアセンブリー・コードは、128 ビットのインテル® AVX 命令のスカラーバージョンを使用していますが、目標は、256 ビットのインテル® AVX 命令のパックド (ベクトルの別名) バージョンを生成することです。vaddss の ss (scalar single) は、単精度浮動小数点オペランドの 1 つの要素だけが加算されること (スカラー操作) を示します。代わりに vaddps を使用したほうが、より効率良いアルゴリズムになります。ps (packed single) は、単精度浮動小数点オペランドに対するパックド操作を示します。
コードに “#pragma simd” を追加するだけで、128 ビットのインテル® AVX 命令を利用したベクトルコードが生成されます。コンパイラーは、ループをアンロールしてループの反復回数を減らすことも行います。それでもまだ 1 命令あたり 4 オペランドしか処理されないため、最適化の余地があります。
#pragma simd を使用した場合
.B46.11::
vmovups xmm0, XMMWORD PTR [rdx+r10*4]
vaddps xmm1, xmm0, XMMWORD PTR [r8+r10*4]
vaddps xmm2, xmm1, XMMWORD PTR [r9+r10*4]
vaddps xmm3, xmm2, XMMWORD PTR [rax+r10*4]
vmovups XMMWORD PTR [rcx+r10*4], xmm3
vmovups xmm4, XMMWORD PTR [16+rdx+r10*4]
vaddps xmm5, xmm4, XMMWORD PTR [16+r8+r10*4]
vaddps xmm0, xmm5, XMMWORD PTR [16+r9+r10*4]
vaddps xmm1, xmm0, XMMWORD PTR [16+rax+r10*4]
vmovups XMMWORD PTR [16+rcx+r10*4], xmm1
add r10, 8
cmp r10, rbp
jb .B46.11
“pragma vector aligned” を指定すると、すべての配列参照にアラインされたデータ移動命令を使用するようにコンパイラーに指示します。”pragma simd” と “pragma vector aligned” の両方を使用することで、256 ビットのインテル® AVX 命令が生成されます。第 2 世代インテル® Core™ プロセッサーでアラインされたメモリーにアクセスするときに、アラインされていない move 命令を使用してもペナルティーはないため、インテル® コンパイラーは vmovups を選択します。
#pragma simd と #pragma vector aligned を使用した場合
.B46.4::
vmovups ymm0, YMMWORD PTR [rdx+rax*4]
vaddps ymm1, ymm0, YMMWORD PTR [r8+rax*4]
vaddps ymm2, ymm1, YMMWORD PTR [r9+rax*4]
vaddps ymm3, ymm2, YMMWORD PTR [rbx+rax*4]
vmovups YMMWORD PTR [rcx+rax*4], ymm3
vmovups ymm4, YMMWORD PTR [32+rdx+rax*4]
vaddps ymm5, ymm4, YMMWORD PTR [32+r8+rax*4]
vaddps ymm0, ymm5, YMMWORD PTR [32+r9+rax*4]
vaddps ymm1, ymm0, YMMWORD PTR [32+rbx+rax*4]
vmovups YMMWORD PTR [32+rcx+rax*4], ymm1
add rax, 16
cmp rax, r11
jb .B46.4
上記のコードには、いくつかのインテル® コンパイラーの自動ベクトル化機能が適用されています。ベクトル化は、ベクトルレポート、simd アサートプラグマ、あるいは生成されたアセンブリー言語命令の調査により確認できます。アプリケーションをよく理解している開発者がプラグマを使用すると、コンパイラーはより適切にベクトル化を行えます。インテル® コンパイラーのベクトル化についての詳細は、「インテル® C++ コンパイラーによるベクトル化」 (http://software.intel.com/en-us/articles/a-guide-to-auto-vectorization-with-intel-c-compilers/ (英語)) を参照してください。『インテル® C++ コンパイラー・デベロッパー・ガイドおよびリファレンス』にも、ベクトル化、プラグマ、コンパイラー・オプションの使用方法に関する情報が含まれています。インテル® コンパイラーは、アプリケーションでインテル® AVX を利用できるように、さまざまなベクトル化処理を行います。
5. インテル® Cilk™ Plus の配列表記 C/C++ 拡張 (インテル® Cilk™ Plus のサポートは終了しました)
インテル® Cilk™ Plus の配列表記 (アレイ・ノーテーション) C/C++ 言語拡張は、配列アクセスを簡潔に記述できる、インテル固有の言語拡張です。アルゴリズムで配列表記が使用され、AVX オプションを指定してコンパイルされた場合、インテル® コンパイラーはインテル® AVX 命令を生成します。配列表記を使用すると、開発者はプログラムで高レベルの並列ベクトル配列演算を直接表現できます。コンパイラーは、データ依存性解析、ベクトル化、自動並列化の最適化時にこの機能を利用します。開発者の視点から見ると、ベクトル化がより予測可能になり、パフォーマンスが向上して、ハードウェアのリソース利用率が高まることになります。配列表記と別のインテル® Cilk™ Plus 言語拡張を組み合わせると、並列化されたベクトル・アプリケーションを容易に記述できます。
開発者は、スカラー構文を使用して演算を表現する標準 C/C++ 要素関数 (SIMD 対応関数) を記述することから始めます。配列表記を利用せずに呼び出された場合、この要素関数を使用して単一要素の演算を行います。要素関数は “__declspec(vector)” を使用して宣言します。この宣言により、呼び出し元は、配列表記を使用して要素関数を呼び出すことができます。
この例では、multiplyValues は要素関数として示されています。
__declspec(vector) float multiplyValues(float b, float c)
{
return b*c;
}
この例では、スカラー呼び出しが示されています。
float a[12], b[12], c[12]; a[j] = multiplyValues(b[j], c[j]);
関数は、配列表記を使用して、配列全体または配列の一部に対して演算を行うことができます。演算する配列の部分は、セクション・オペレーターを使用して指定します。構文は、[<lower bound> : <length> : <stride>] です。
lower はソース配列の開始インデックス、length は要素数、stride はソース配列のストライドです。stride はオプションで、デフォルトは 1 です。
配列セクションの例を以下に示します。
float a[12];
a[:] // 配列全体
a[0:2:3] // 配列 a の要素 0 と 3
a[2:2:3] // 配列 a の要素 2 と 5
a[2:3:3] // 配列 a の要素 2、5、8
この表記は、多次元配列もサポートしています。
float a2d[12][4];
a2d[:][:] // 配列 a2d 全体
a2d[:][0:2:2] // a2d のすべての行の列 0 と 2 の要素
この配列表記を利用することで、配列を使用して multiplyValues を呼び出すことが容易になります。インテル® コンパイラーは、ベクトル化されたバージョンを生成して、実行を適切にディスパッチします。次に例を示します。最初の例は配列全体に対して演算を行い、次の例は配列のサブセット (一部) またはセクションに対して演算を行います。
この例は、配列全体に対して関数を実行します。
a[:] = multiplyValues(b[:], c[:]);
この例は、配列のサブセットに対して関数を実行します。
a[0:5] = multiplyValues(b[0:5], c[0:5]);
配列表記は、配列を利用するアプリケーションの記述を容易にします。自動ベクトル化と同様に、インテル® AVX 命令が使われているかどうか、インテル® コンパイラーにより生成された命令を確認する必要があります。/S オプションを指定してコンパイルすると、アセンブリー・ファイルが生成されます。mutliplyValues の例では、スカラーバージョンとベクトルバージョンの両方が使用されていることが分かります。
スカラー実装は、VEX エンコード・フォーマットの 128 ビットのインテル® AVX 命令のスカラー (ss) バージョンを使用しています。
vmulss xmm0, xmm0, xmm1
ret
ベクトル実装は、VEX エンコード・フォーマットの 256 ビットのインテル® AVX 命令のスカラー (ps) バージョンを使用しています。
sub rsp, 40 vmulps ymm0, ymm0, ymm1 mov QWORD PTR [32+rsp], r13 lea r13, QWORD PTR [63+rsp] and r13, -32 mov r13, QWORD PTR [32+rsp] add rsp, 40 retこれらの例は、インテル® AVX 命令を明示的に使用することなく、配列表記 C/C++ 言語拡張がどのようにインテル® AVX の機能を使用しているかを示しています。配列表記は、要素関数の有無に関係なく使用できます。この機能により、より多くの柔軟性と選択肢が開発者に提供されます。また、最新のインテル® AVX 命令セット・アーキテクチャーを使用できます。
開発者は、インテル® AVX 命令を生成し、アプリケーションの自動ベクトル化を行うようにコンパイラーに指示できます。また、インテル® Cilk™ Plus の配列表記 C/C++ 拡張によって、インテル® AVX を利用することができます。また、インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) とインテル® マス・カーネル・ライブラリー (インテル® MKL) は、インテル® AVX のようなインテルの最新テクノロジーのサポートを含む、豊富な機能を提供しており、アセンブリー言語によるコーディングを行うことなく、インテル® AVX を利用することができます。
6. インテル® IPP とインテル® MKL ライブラリーの利用
インテルでは、マルチメディア、データ処理、暗号化、通信アプリケーション向けに高度に最適化された、さまざまなソフトウェア関数を含む、インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) およびインテル® マス・カーネル・ライブラリー (インテル® MKL) を提供しています。これらのスレッドセーフなライブラリーは、さまざまなオペレーティング・システムをサポートしており、指定されたプラットフォームで最も高速なコードを実行します。これらのライブラリーを利用することで、アプリケーションにマルチコアの並列化とベクトル化を実装して、コードを実行するプロセッサー向けの最新の命令を生成できます。インテル® IPP 7.0 には、インテル® AVX 向けに最適化された 170 以上の関数が含まれています。これらの関数を使用して、FFT、フィルタリング、畳み込み、相関、サイズ変更、その他の演算を実行できます。インテル® MKL 10.2 では、BLAS (DGEMM)、FFT、VML (exp、log、pow) にインテル® AVX のサポートが追加されました。インテル® MKL 10.3 では実装が簡素化され、最初に mkl_enable_instructions を呼び出す必要がなくなりました。また、インテル® MKL 10.3 では、DGMM/SGEMM、基数 2 の複素 FFT、ほとんどの実数 VML 関数、VSL 分布ジェネレーターでインテル® AVX のサポートが拡張されました。
ライブラリーの上記のバージョンをすでに使用している場合、あるいはこれから使用する場合、アプリケーションでインテル® AVX 命令セットを利用できます。ライブラリーは、開発コード名 Sandy Bridge プラットフォームで実行されたときにインテル® AVX 命令を実行します。Linux*、Windows*、Mac OS* X プラットフォームをサポートしています。
インテル® AVX 用に最適化されたインテル® IPP 関数についての詳細は、http://software.intel.com/en-us/articles/intel-ipp-functions-optimized-for-intel-avx-intel-advanced-vector-extensions/ (英語) を参照してください。
インテル® MKL の AVX サポートについての詳細は、「インテル® MKL V10.3 におけるインテル® AVX の最適化」 (https://software.intel.com/en-us/articles/intel-avx-optimization-in-intel-mkl/) を参照してください。
7. まとめ
増大する計算パフォーマンスの必要性に応えるため、インテルはマイクロアーキテクチャーと命令セットの改良を続けています。開発者は、開発に膨大な労力をかけることなく、製品で最新の機能を活用する手法を求めています。この記事で説明した手法、ツール、ライブラリーを利用することで、開発者は、インテル® AVX のアセンブリー言語を全く記述することなく、インテル® AVX の機能を活用することができます。2013 年 6 月に発表された第4世代インテル® Core™ プロセッサー・ファミリー(開発コード名: Haswell)では、インテル® AVX2 がサポートされています。この記事で紹介した内容は、インテル® AVX2 にも適用できます。
8. 参考文献
- インテル® アドバンスト・ベクトル・エクステンション (https://software.intel.com/en-us/avx/)
- インテル® コンパイラー (http://software.intel.com/en-us/articles/intel-compilers/)
- インテル® C++ コンパイラー – ドキュメント (英語)
- インテル® AVX のコンパイル方法 (http://software.intel.com/en-us/articles/how-to-compile-for-intel-avx/)
- インテル® C++ コンパイラーによるベクトル化 (http://software.intel.com/en-us/articles/a-guide-to-auto-vectorization-with-intel-c-compilers/ (英語))
- インテル® アドバンスト・ベクトル・エクステンション向けに最適化されたインテル® インテグレーテッド・パフォーマンス・プリミティブ関数 (http://software.intel.com/en-us/articles/intel-ipp-functions-optimized-for-intel-avx-intel-advanced-vector-extensions/)
- インテル® MKL でインテル® アドバンスト・ベクトル・エクステンションの最適化を有効にする (http://software.intel.com/en-us/articles/enabling-avx-optimizations-in-mkl/ (英語))
- インテル® MKL V10.3 におけるインテル® AVX の最適化 (https://software.intel.com/en-us/articles/intel-avx-optimization-in-intel-mkl/)
表 1 – インテル® コンパイラーのコマンドライン・オプションの要約
| インテル® コンパイラーの コマンドライン・オプションの説明 |
Windows* | Linux* | Mac OS* X |
|---|---|---|---|
| パフォーマンス上の利点がある場合は複数のプロセッサー固有の自動ディスパッチ・コードを生成 | /Qax | -ax (最新のコンパイラーでは -qax) |
-ax (最新のコンパイラーでは -qax) |
| ベクトル化レポートの生成 | /Qvec-report<n> (最新のコンパイラーでは /Qopt-report) |
-vec-report<n> (最新のコンパイラーでは -qopt-report) |
-vec-report<n> (最新のコンパイラーでは -qopt-report) |
| アセンブリー言語ファイルの生成 | /S(/Fa) | -S | -S |
