

この記事は、インテル® デベロッパー・ゾーンに公開されている「New optimizations for X86 in upcoming GCC 5.0」(https://software.intel.com/en-us/blogs/2014/11/24/what-is-new-for-x86-in-upcoming-gcc-50) の日本語参考訳です。
パート 1 ロード/ストアグループのベクトル化
GCC 5.0 では、ロードグループとストアグループのベクトルコードの品質が大幅に向上しました。ロード/ストアグループとは、反復中のロード/ストアの連続したシーケンスを意味します。次に例を示します:
x = a[i], y = a[i + 1], z = a[i + 2] で、”i” で繰り返されるロードグループのサイズは 3 です。
グループサイズは、ロード/ストアアドレスの最下位と最上位間の距離です。例えば、(i + 2) – (i) + 1 = 3 の場合、グループ中のロード/ストアの数は、グループサイズと等しいかそれ以下です。次に例を示します:
x = a[i], z = a[i + 2] で、”i” で繰り返されるロードグループのサイズは 3 のままですが、ロードの数は 2 です。
GCC 4.9 では、2 の累乗 (2,4,8 …)サイズのグループをベクトル化します。
GCC 5.0 では、サイズ 3 と 2 の累乗 (2,4,8 …) のグループをベクトル化します。他のサイズ (5,6,7,9 …) は、ほとんど使用されません。
ロード/ストアグループが適用される最も一般的なケースは、構造体配列のアクセスです。
- イメージ変換 (RGB 構造体からその他へ)
(https://gcc.gnu.org/bugzilla/show_bug.cgi?id=52252 で、テストケースを試すことができます) - N 次元座標 (XYZ 点が正規化された配列)
(https://gcc.gnu.org/bugzilla/show_bug.cgi?id=61403 で、テストケースを試すことができます) - 定数行列によるベクトル乗算:
a[i][0] = 7 * b[i][0] – 3 * b[i][1];
a[i][1] = 2 * b[i][0] + b[i][1];
基本的に GCC 5.0 では、以下が適用されます。
- サイズ 3 のロード/ストアグループのベクトル化を導入
- すべてのサポートされるサイズにおけるロードグループのベクトル化を改善
- 特定の x86 CPU に最適なコードを生成することで、ロード/ストアグループのパフォーマンスを最大化します。
以下は、バイト構造体(ベクトル内の要素の最大数)におけるパフォーマンスへの影響を、GCC 4.9 と GCC 5.0 で以下のループを使用して推測したものです:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | int i, j, k; byte *in = a, *out = b; for (i = 0; i < 1024; i++) { for (k = 0; k < STGSIZE; k++) { byte s = 0; for (j = 0; j < LDGSIZE; j++) s += in[j] * c[j][k]; out[k] = s; } in += LDGSIZE; out += STGSIZE; } |
ここで “c” は、定数行列
1 2 3 4 5 6 7 8 | const byte c[8][8] = {1, -1, 1, -1, 1, -1, 1, -1, 1, 1, -1, -1, 1, 1, -1, -1, 1, 1, 1, 1, -1, -1, -1, -1, -1, 1, -1, 1, -1, 1, -1, 1, -1, -1, 1, 1, -1, -1, 1, 1, -1, -1, -1, -1, 1, 1, 1, 1, -1, -1, -1, 1, 1, 1, -1, 1, 1, -1, 1, 1, 1, -1, -1, -1}; |
“加算” と “減算” のような簡単な計算のループは、通常非常に高速です。
- “in” と “out” ポインターは、グローバル配列 “a[1024 * LDGSIZE]” と “b[1024 * STGSIZE]” を指します。
- “byte” は、unsigned char です。
- “LDGSIZE” と “STGSIZE” マクロは、ロードとストアグループのサイズに応じて定義します。
コンパイルオプション “-Ofast” に加えて Silvermont 向けには “-march=slm”、Haswell 向けには “-march=core-avx2” と “-DLDGSIZE={1,2,3,4,8} -DSTGSIZE={1,2,3,4,8}” のすべての組み合わせを使用します。
GCC 4.9 に対する 5.0 のゲイン (大きな値が良い)。
Silvermont: インテル® Atom™ CPU C2750 @ 2.41GHz
最大 6.5 倍のゲイン!
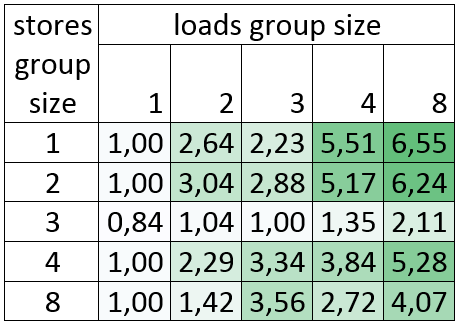
サイズ 3 のストアグループの結果を見ると、それほど良い結果ではありません。これは、現在サイズ 3 のストアグループのベクトル化には、Silvermon で約 5 クロックを要する “pshufb” 命令が 8 個生成されるためです。しかし、ループはベクトル化されているため、ループ内でよりコストの高い計算が行われるとゲインを得られるかもしれません (サイズ2、3、4、8 のロードグループでゲインが見られるように)。
Haswell: インテル® Core™ i7-4770K CPU @ 3.50GHz
最大 3 倍のゲイン!
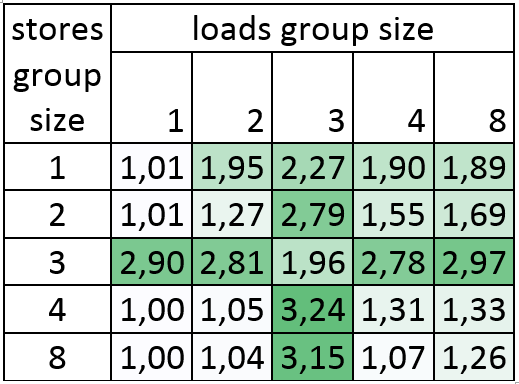
ここでのサイズ 3 のストアグループの結果は、Haswell では “pshufb” 命令は 1 クロックであるため良い結果となっています。新たに実装されたサイズ 3 のロード/ストアグループで最大の改善を見ることができます。
計測に使用したコンパイラーは以下で入手できます:
GCC 4.9: https://gcc.gnu.org/gcc-4.9
GCC 5.0 トランクビルドは、リビジョン 217914 です: https://gcc.gnu.org/viewcvs/gcc/trunk/?pathrev=218160
ダウンロード: matrix.zip
パート 2 は、こちらをご覧ください。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください
