
この記事は、The Parallel Universe Magazine 57 号に掲載されている「Accelerating GGUF Models with Transformers」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

GGUF (GPT-Generated Unified Format、GPT によって生成された統一形式) は、ファイル内のテンソルとメタデータを素早く検査できる新しいバイナリー形式です (図 1)。これは言語モデルファイル形式の大きな飛躍であり、GPT などの大規模言語モデル (LLM) の保存と処理の効率を最適化します。PyTorch* モデルを GGUF 形式に変換するのは簡単です。

図 1. GGUF 形式 (出典 (英語))
Hugging Face* Transformers は最近、Transformers PR (英語) で GGUF をサポートしました。Transformers は、PyTorch* を使用して推論を実行する前に、GGUF モデルを FP32 に逆量子化します。使い方は簡単で、図 2 に示すように、from_pretrained で gguf_file パラメーターを指定するだけです。
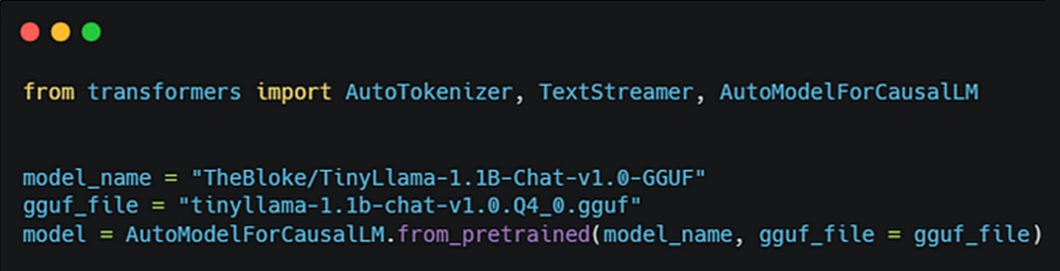
図 2. Hugging Face* Transformers での GGUF モデルの使用
Transformers 向けインテル® エクステンション (英語) は低ビットの LLM 推論を高速化します。Hugging Face* Transformers を拡張し、インテル® プラットフォーム上でパフォーマンスを向上します。幅広いモデルで GGUF 推論をサポートしており、使い方も簡単です (図 3)。

図 3. Transformers 向けインテル® エクステンション (英語) での GGUF モデルの使用
現在、Transformers は Llama* や Mistral* など、50 を超える一般的な LLM をサポートしています (表 1)。

表 1. サポートされる LLM
セットアップは簡単です。最初に、Neural Speed をインストールします。
git clone https://github.com/intel/neural-speed.git cd neural_speed python setup.py install
次に、Transformers 向けインテル® エクステンション (英語) をインストールします。
git clone https://github.com/intel/intel-extension-for-transformers.git cd intel_extension_for_transformers python setup.py install
