

この記事は、The Parallel Universe Magazine 55 号に掲載されている「A Quantization Framework for Bayesian Deep Learning」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

ディープ・ニューラル・ネットワーク (DNN) は、優れた精度とパフォーマンスにより、医療診断、自動運転車、天気予報など、さまざまなセーフティー・クリティカル・アプリケーションにおける不可欠なコンポーネントとなっています。しかし、トレーニング・データの過剰適合や、間違った予測を過信してしまうことがあります。これにより、分布外のデータを検出する能力や、信頼できる信頼区間を含む予測の不確実性に関する情報を提供する能力が制限されます。この問題は、説明可能性と安全性が必要な実際のアプリケーションでは極めて重要です。例えば、医療診断では、モデルは予測に不確実性の尺度を示す必要があります。
データに最も適合する重みパラメーターの決定論的ポイントの推定を見つけることを目的とした従来の DNN モデルとは異なり、ベイズ・ディープ・ニューラル・ネットワーク (BNN) モデルは、ベイズの定理に基づいて重みの事後分布を学習することを目的としています (図 1)。ベイズモデルの重みは推論中に学習された分布からサンプリングされ、複数のモンテカルロ・サンプルにより予測の不確実性を推定します。
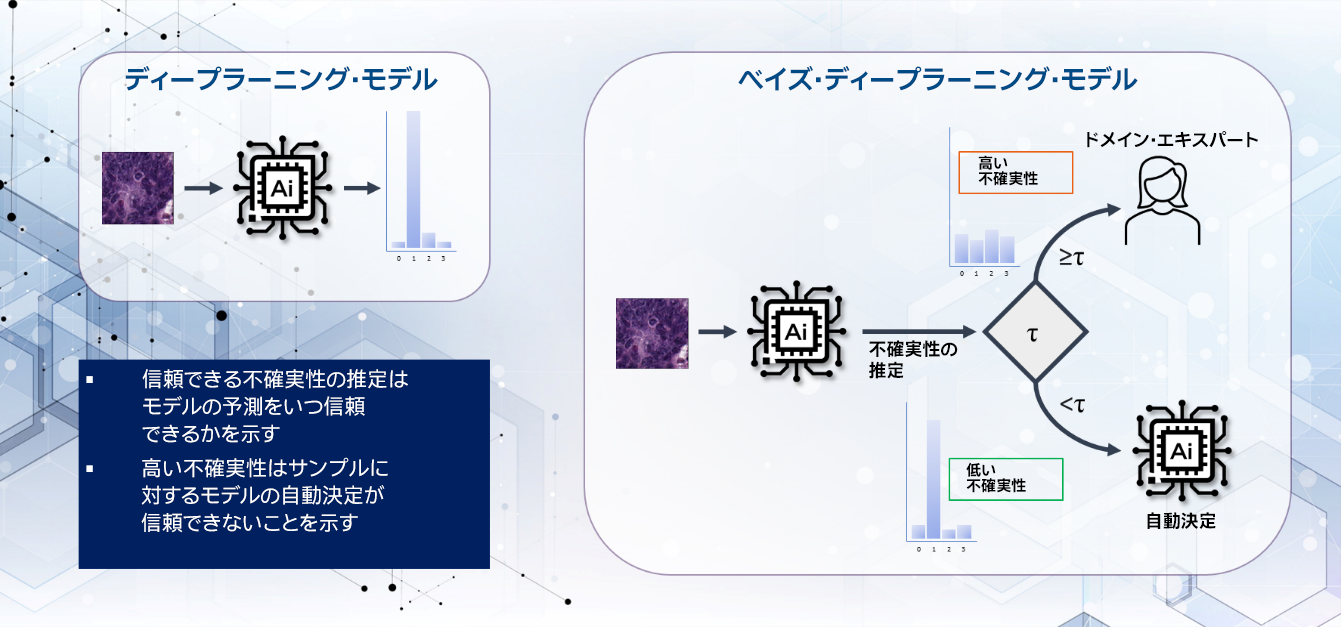
図 1. 大腸組織構造診断における不確実性に基づく選択的予測
BNN は、重みのサンプリングと複数の確率的フォワードパスにより追加のメモリーと計算コストが必要になるため、決定論的モデルよりもモデルのサイズが大きくなり、推論が遅くなります。これらの欠点のため、BNN を実際のアプリケーションにデプロイする際には大きな課題が生じます。ここで量子化の出番です。量子化は、重みと有効性を 8 ビット整数 (int8) などの低精度データ型で表すことにより、BNN 推論のメモリーと計算コストを削減するのに役立ちます。
ここでは、広く利用されているベイズ・ディープラーニング (BDL) 向けの PyTorch* ベースのオープンソース・ライブラリー、Bayesian-Torch (英語) を使用して構築された量子化モデルを含む BDL ワークロードを紹介します。Bayesian-Torch は、BDL の低精度の最適化をサポートします。Bayesian-Torch を使用して、量子化されたベイズモデルをインテル® アドバンスト・マトリクス・エクステンション (インテル® AMX) を搭載した第 4 世代インテル® Xeon® スケーラブル・プロセッサーにデプロイすることにより、モデルの精度と不確実性の質を犠牲にすることなく、完全な精度のベイズモデルと比較して ImageNet ベンチマークで 6.9 倍の推論速度の向上を達成しました。
BNN の量子化
Bayesian-Torch は、シンプルな API (dnn_to_bnn()) を使用して、あらゆる DNN モデルを BNN にシームレスに変換できます。我々は、IISWC 2023 (IEEE International Symposium on Workload Characterization) (英語) で発表された論文「Quantization for Bayesian Deep Learning: Low-Precision Characterization and Robustness (ベイズ・ディープラーニングの量子化: 低精度の特性化とロバスト性)」で、包括的な量子化ワークフローを紹介しました。以下の 3 つの簡単なステップで、トレーニング後の量子化 (PTQ) を BNN に適用できます。
- 準備: 「オブザーバーの挿入」などの前処理タスクを実行して、静的量子化のモデルを準備します。
- キャリブレーション: 代表的なデータを使用してキャリブレーションを行い、キャリブレーション統計を取得します。
- 変換: モデルのすべてのテンソルと演算についてスケールとゼロ点を計算し、量子化可能な関数を低精度の関数に置換することにより、完全な精度のベイズモデルを量子化モデルに変換します。
Bayesian-Torch 量子化フレームワークには、PyTorch* (英語) のような高水準 API があります (図 2)。

図 2. Bayesian-Torch でトレーニング後の量子化を実装するステップ
