

この記事は、The Parallel Universe Magazine 55 号に掲載されている「Using Intel’s New Built-in AI Acceleration Engines」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

人工知能 (AI) が注目されるとともに、パフォーマンスを向上させる方法として、低精度データ型の導入と、これらのデータ型のハードウェア・サポートが求められています。低精度モデルは計算が速く、メモリー・フットプリントが小さくなることから、AI トレーニングと推論には、32 ビットのデータ型よりも低精度のデータ型が推奨されます。これらの低精度データ型を最適化およびサポートするには、ハードウェアに特別な機能と命令が必要です。インテルは、これらをインテル® CPU とインテル® GPU でそれぞれ、インテル® アドバンスト・マトリクス・エクステンション (インテル® AMX) およびインテル® Xe マトリクス・エクステンション (インテル® XMX) として提供しています。最も使用されている 16 ビット形式は、16 ビット IEEE 浮動小数点数 (fp16) 、bfloat16、16 ビット整数 (int16) であり、最も使用されている 8 ビット形式は、8 ビット整数 (int8) と 8 ビット Microsoft* 浮動小数点数 (ms-fp8) です。これらの形式の違いの一部を図 1 に示します。
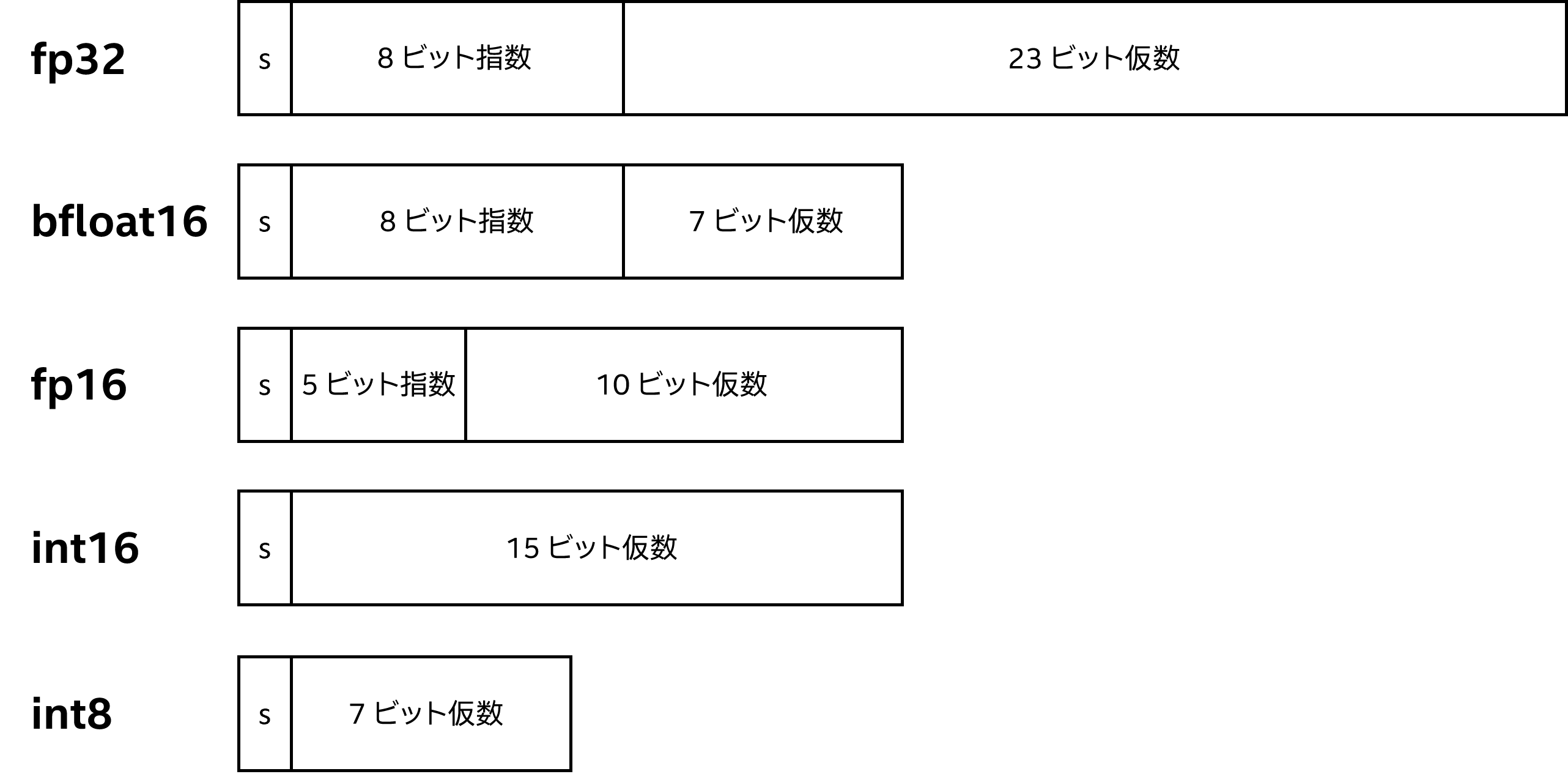
図 1. IEEE 標準データ型のさまざまな数値表現。s は符号付きビット (正の数は 0、負の数は 1) を表し、exp は指数を表します。
インテル® AMX とインテル® XMX を呼び出すプログラミング・パラダイムは、ハードウェアにより異なります。この記事では、それらをプログラムするさまざまな方法を紹介した後、これらの命令セットのパフォーマンスの利点を説明します。
インテル® AMX とインテル® XMX
インテル® AMX
インテル® AMX は、マイクロプロセッサー向けの x86 命令セット・アーキテクチャー (ISA) を拡張したものです。アクセラレーターが操作を実行できる、タイルと呼ばれる 2D レジスターを使用します。インテル® AMX の 1 つのユニットには、通常 8 つのタイルがあります。タイルは、ロード、ストア、クリア、または内積操作を実行できます。インテル® AMX は、int8 および bfloat16 データ型をサポートします。インテル® AMX は、第 4 世代インテル® Xeon® スケーラブル・プロセッサーでサポートされています (図 2)。

図 2. 第 4 世代インテル® Xeon® スケーラブル・プロセッサーのインテル® AMX
インテル® XMX
インテル® XMX (内積累算シストリック (Dot Product Accumulate Systolic、DPAS) とも呼ばれる) は、2D シストリック・アレイでの内積と累算命令の実行を専門としています。並列コンピューター・アーキテクチャーのシストリック・アレイは、密結合なデータ処理ユニットのホモジニアス・ネットワークです。各ユニットは、上流のユニットから受け取ったデータの関数として部分的な結果を計算し、その結果を保存して、下流のユニットに渡します。インテル® XMX は、ハードウェア世代に応じて、int8、fp16、bfloat16、tf32 などのさまざまなデータ型をサポートしています。インテル® XMX は、インテル® データセンター GPU マックス・シリーズまたはインテル® データセンター GPU フレックス・シリーズの一部です。インテル® データセンター GPU マックス・シリーズのインテル® Xe HPC 2 スタックは、図 3 では Xe として省略されています。スタックとは、タイルの代わりに使用される用語です。インテル® データセンター GPU マックス・シリーズは 8 つのインテル® Xe スライスで構成されます。各スライスには 16 個のインテル® Xe コアが含まれています。各コアには 8 つのベクトルエンジンと 8 つの行列エンジンが含まれています。

図 3. インテル® データセンター GPU マックス・シリーズ (開発コード名 Ponte Vecchio) のインテル® XMX
