

この記事は、The Parallel Universe Magazine 55 号に掲載されている「Usher in a New Era of Accelerated AI on Intel CPUs」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

問題ステートメント
2024年を迎えて、さまざまな業界の企業が大規模言語モデル (LLM) の可能性を目の当たりにしています。しかし、主にコスト、複雑さ、高い消費電力、データ保護への懸念により、企業は LLM を自社の業務に統合することに苦労しています。GPU はこれまで LLM にとって主要なハードウェアでしたが、IT の複雑さとコストの増加により、成長する運用を維持することは容易ではありません。さらに、世界的な需要の増加と供給不足のため、企業は現在、AI プロジェクト向けの GPU を確保するのに 1 年以上待つこともあります。
新しいアプローチ
そこで、Numenta とインテルは、GPU への依存から企業を解放する、LLM 導入の新しいアプローチを作り出しました。Numenta Platform for Intelligent Computing (NuPIC*) は、神経科学に基づく概念をインテル® アドバンスト・マトリクス・エクステンション (インテル® AMX) 命令セットにマップします。NuPIC* を使用すると、インテル® CPU 上に LLM を大規模にデプロイして、コストとパフォーマンスの劇的な向上を実現できます (第 4 世代インテル® Xeon® スケーラブル・プロセッサーのパフォーマンス・インデックス (英語) のベンチマーク P6 および P11 を参照)。
テクノロジー
インテル® AMX
インテル® AMX は、専用のハードウェア・サポートを提供することにより行列演算を高速化します (図 1) 。このテクノロジーは、ディープラーニング推論など、行列計算に大きく依存するアプリケーションでは特に有益です。インテル® AMX は、第 4 世代インテル® Xeon® プロセッサーで最初に導入され、新しい第 5 世代インテル® Xeon® プロセッサーでさらに高速化されました。
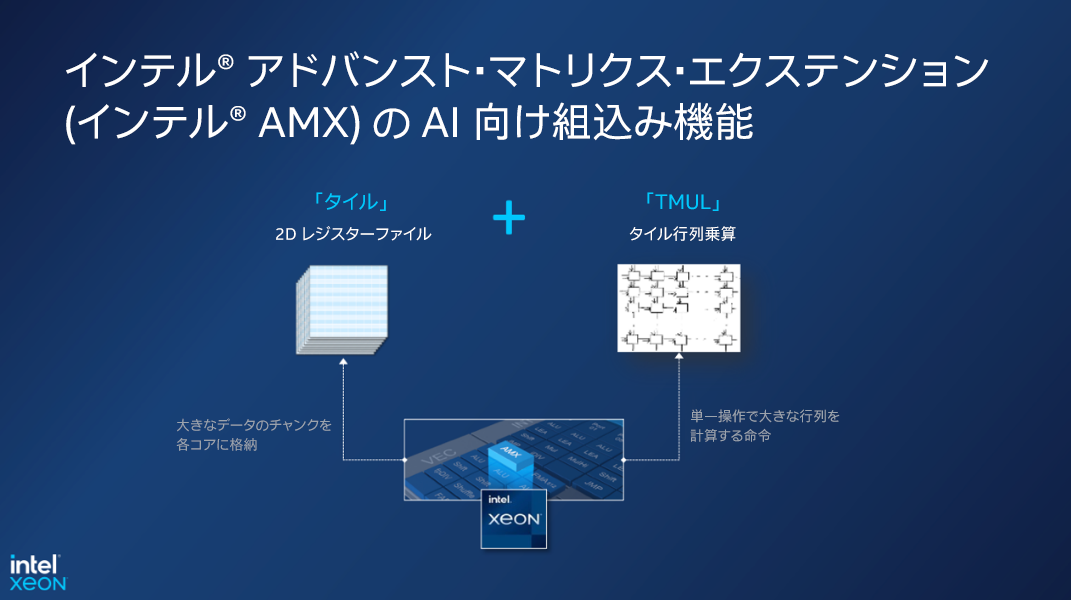
図 1. インテル® AMX 命令セットには、タイルと TMUL という 2 つの主要なコンポーネントが含まれています。タイルは、大きな行列の並列処理を可能にする 2D ユニットです。TMUL は、わずか 16 クロックサイクルで 16x16x32 の行列乗算を実行できます。
NuPIC*
NuPIC* は数十年にわたる神経科学研究に基づいて構築されており、強力な言語ベースのアプリケーションを迅速かつ容易に構築できます (図 2)。NuPIC* の中心となるのは、インテル® CPU 上で LLM を効率的に実行できるようにする、インテル® AMX を活用して高度に最適化された推論サーバーです。さまざまな自然言語処理のユースケースに合わせてカスタマイズできる、実用的な事前トレーニング済みモデルのライブラリーを使用して、NuPIC* 推論サーバーでモデルを直接実行できます。NuPIC* トレーニング・モジュールを使用してユーザーデータでモデルを調整し、そうしたカスタムモデルを NuPIC* モデル・ライブラリーにデプロイして推論サーバーで実行することもできます。
標準の推論プロトコルをベースに構築された NuPIC* は、標準の MLOps パイプラインにシームレスに統合できます。このソリューションは Docker* コンテナとしてデプロイされ、スケーラブル、セキュア、高可用性、ハイパフォーマンスの環境としてインフラストラクチャー内に保持できます。カスタムモデルは完全に制御できます。データは完全にプライベートのままで、システムの外にエクスポートする必要はありません。
インテル® Xeon® CPU 上の NuPIC* が AI 推論に最適な理由
Numenta とインテルは、この物語の新たな章を開き、非常にコスト効率に優れた方法で LLM を CPU 上に大規模にデプロイできるようにしました。その理由をいくつか紹介しましょう。
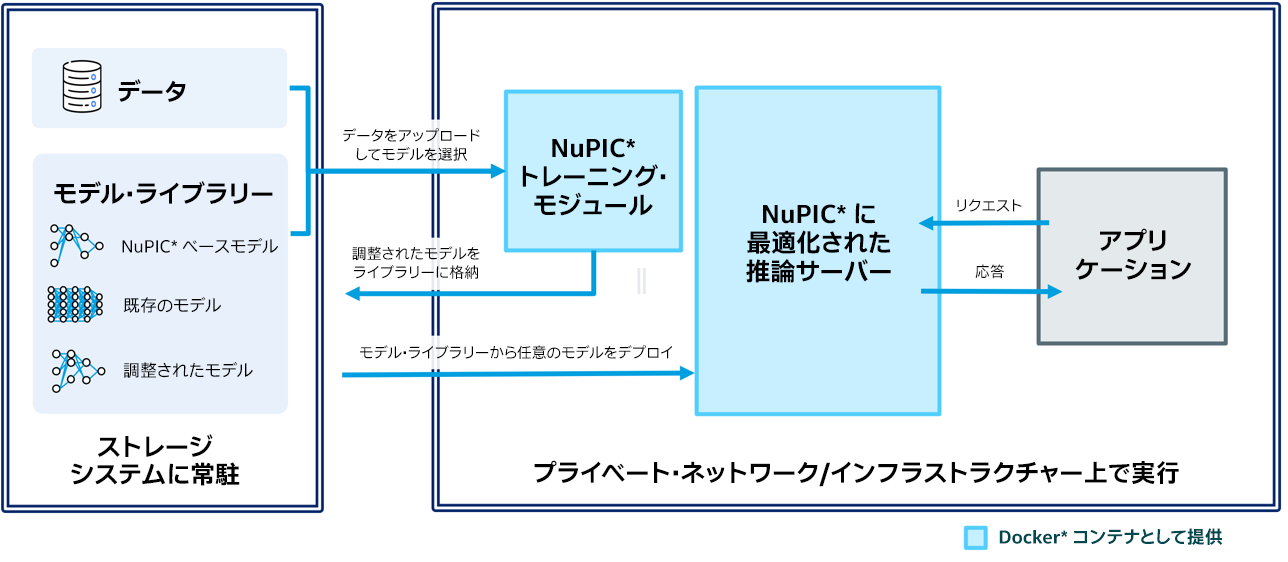
図 2. NuPIC* アーキテクチャー
パフォーマンス: NVIDIA* A100 Tensor Core GPU より 17 倍高速
Transformer 構造への最小限の変更により、NuPIC* は、インテル® AMX 対応の CPU で、前世代の CPU と比較して推論スループットを 2 桁以上向上し、GPU と比較しても大幅な速度向上を実現します (表 1)。BERT-Large で、第 5 世代インテル® Xeon® CPU 上の NuPIC* は、NVIDIA* A100 GPU よりも最大でおよそ 17 倍優れています。GPU で最高の並列パフォーマンスを実現するには、より大きなバッチサイズが必要です。しかし、バッチ処理は推論の実装が複雑になり、リアルタイム・アプリケーションでレイテンシーが生じます。対照的に、NuPIC* ではバッチ処理が必要ないため、アプリケーションは柔軟で、スケーラブルで、管理が容易になります。参考として、バッチサイズ 8 の NVIDIA* A100 のパフォーマンスをリストします。バッチサイズ 1 の NuPIC* は、このバッチサイズ 8 の NVIDIA* GPU 実装と比較した場合でも 2 倍以上優れています。
