
この記事は、The Parallel Universe Magazine 52 号に掲載されている「Optimize Utility Maintenance Prediction for Better Service」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

世界的に電力需要が増加する中、信頼性の高いサービスを提供し、コストのかかる予期しないダウンタイムを回避するには、インフラ設備を正確かつ効率的に監視する必要があります。現在の手動による問題の特定は 50% 未満の精度であり、電柱の保守と交換のコストは 100 億米ドルを超えています (出典: Utility Poles: Maintenance or Replacement (英語)、Utility Partners of America、2020年8月8日)。
インテルは Accenture と協力して、Predictive Asset Analytics Reference Kit (https://github.com/oneapi-src/predictive-asset-health-analytics) を開発しました。これは、インフラ設備を予防的に保守し、システムの安定性を向上し、機能停止やダウンタイムを回避し、運用コストを抑えるため、インフラ設備の健全性と障害の可能性を予測するように設計されています。このリファレンス・キットには、トレーニング・データ、オープンソースのトレーニング済みの資産予測分析モデル、ライブラリー、ユーザーガイド、およびトレーニング・サイクル、予測スループット、精度を最適化する oneAPI コンポーネントが含まれています。
このリファレンス・キットの実装方法を示すため、このチュートリアルで使用するデータセットは、ユーザーガイド (https://github.com/oneapi-src/predictive-health-analytics) の手順に従って生成されました。ワークフローを図 1 に示します。これは、電柱の使用年数、保守履歴、機能停止記録、地理空間データなど、インフラ設備の全体的な健全性に関する 34 の特徴で構成されています。ターゲット変数は、電柱が故障しているかどうかを示すバイナリー・インジケーターです。
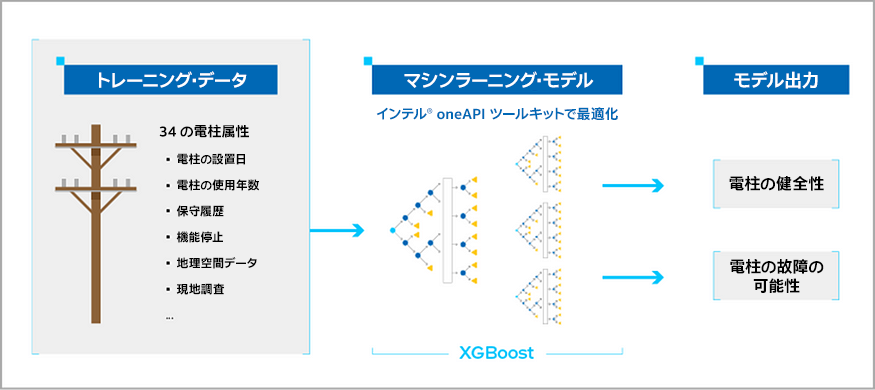
図 1. Predictive Asset Analytics Reference Kit のワークフロー
このリファレンス・キットの主な利点は、コードをほとんどまたは全く変更することなく、ヘテロジニアスな XPU アーキテクチャー全体でモデルのトレーニングと推論を最適化できることです。インテル® AI アナリティクス・ツールキット (AI キット) とインテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) がこれを可能にします。このガイドで使用する AI キットの主なライブラリーは、Modin 向けインテル® ディストリビューション (英語)、scikit-learn* 向けインテル® エクステンション (英語)、XGBoost 向けインテル® オプティマイゼーション (英語) です。これらはすべて、AI キットの一部またはスタンドアロン・ライブラリーとしてダウンロードできます。さらに、インテル® oneDAL の daal4py (英語) を使用して、XGBoost モデルの推論を高速化します。
データ処理
まず、Modin を使用してデータを処理および調査します。Modin は、pandas ワークフローをデータセットのサイズに合わせてスケーリングするように設計された分散型 DataFrame ライブラリーであり、1MB ~ 1TB 以上のデータセットをサポートします。pandas では、一度に 1 つのコアのみが使用されます。Modin の Dask エンジンは、利用可能なすべての CPU コアを利用できるため、非常に大きなデータセットをはるかに高速に処理できます。 図 2 は、2GB のデータセットに対して同じ pandas 操作を実行する Modin (左) と pandas (右) の例です。2 つの例の唯一の違いは、インポート文です。
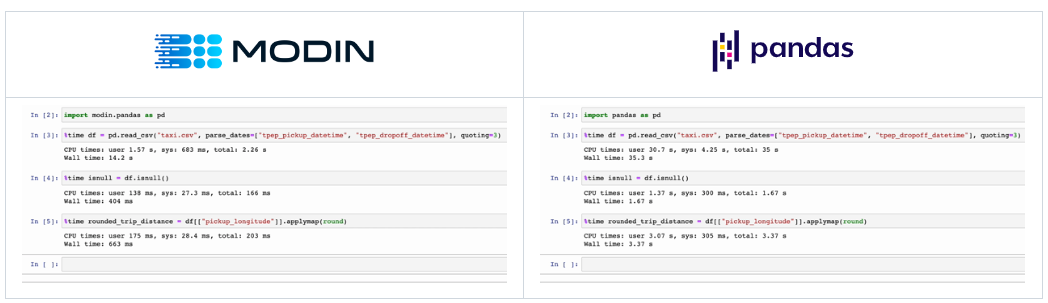
図 2. Modin (左) と pandas (右) のパフォーマンスの比較
Dask エンジンで Modin を使用するには、次のコードセルに示すように、最初に pandas のドロップイン置換をインポートしてから、エンジン呼び出し文で Dask 実行環境を初期化します。
import modin.pandas as pd from modin.config import Engine Engine.put(“dask”)
探索的データ分析
Modin の Dask エンジンが初期化されると、利用可能な CPU コア間で並列に処理される同じ pandas 関数を使用して、データの処理と調査を続行できます。図 3 の State 1 に示すように、データ内の電柱の約 40% に不具合があると識別されました。ターゲット分布のわずかな不均衡を考慮して、交差検証中に層化抽出法を使用します。データをさらに詳しく調べるには、こちらのノートブック (英語) を参照してください。
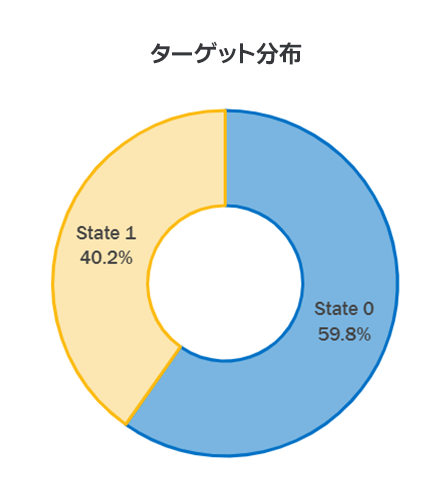
図 3. ターゲット変数 Asset Label の分布
ソリューションの構築
電柱の故障の確率を予測するため、いくつかのマシンラーニング・アルゴリズムを検討しました。データの非線形性のため、サポートベクトル分類器 (SVC) と XGBoost の 2 つのノンパラメトリック・モデルを選択しました。どちらも、特徴とターゲット変数の間の非線形関係を捉えることができる高性能の分類器です。しかし、ハイパーパラメーターをチューニングし、大規模な産業用データセットのモデルをトレーニングするには、長い時間がかかります。ここで、インテル® AI アナリティクス・ツールキットの出番です。
サポートベクトル分類器による分析
SVC モデルのトレーニングと推論を最適化するため、scikit-learn* 向けインテル® エクステンションを利用して、インテルの CPU と GPU の両方で、ベクトル命令、スレッド化、メモリー最適化を使用することで、アルゴリズムの実行時間を短縮します。scikit-learn* 向けインテル® エクステンションは、サポート・ベクトル・マシン、K 近傍法、ランダムフォレストなど、scikit-learn* ライブラリー内の多くの推定器と関数をサポートしています。
