
この記事は、インテル® AI Blog に公開されている「Streamline your Intel® Distribution of OpenVINO™ Toolkit development with Deep Learning Workbench」の日本語参考訳です。
2018 年のリリース以降、インテル® ディストリビューションの OpenVINO™ ツールキットは、セルフチェックアウト端末から医療用画像、産業ロボットに至るまで、さまざまな業界で AI を利用したアプリケーションを展開するため、パートナー各社や開発者により広く採用されています。インテル® アーキテクチャー・プラットフォームとの統合の容易さと合理的な導入体験により、ディープラーニングの推論パフォーマンスを向上できることが、このツールキットの人気の理由です。
このツールキットは、使いやすさとすぐに使用できる合理的な体験を開発者に提供することを目標に設計されています。そのため、ユーザーはインストール後数分で最初のサンプルを実行できます。この導入の容易さは、モデルのインポート、モデルの最適化、下位互換性を保持するためのリリース間のシームレスな移行を含む、ツールのあらゆる面に及びます。インテルのユーザー/開発者体験のエキスパートは、製品のあらゆる面を継続的に評価して改善に取り組んでいます。
同時に、インテルではより多くの用途に対応できるように、インテル® ディストリビューションの OpenVINO™ ツールキットの機能拡張にも取り組んでいます。これまでに、INT8 対応プラットフォームをサポートするための量子化、多数のコアを搭載したプラットフォーム向けのスループット・モード、システムを最大限に活用してパフォーマンスを最大化するマルチデバイス推論を追加しました。新機能を利用し細かい設定を可能にするため、追加のツールや設定が導入されていますが、すべてを理解して個々のアプリケーションのパフォーマンスと精度のトレードオフを最適化することは容易ではありません。そのため、最初のリリースから 1 年後の 2019 年に、グラフィカル・ユーザー・インターフェイス (GUI) 拡張ツールのディープラーニング・ワークベンチが追加されました。これは、既存のすべてのユーティリティーを組み合わせて、モデルのダウンロード (https://docs.openvinotoolkit.org/latest/_tools_downloader_README.html)、精度のチェック (https://docs.openvinotoolkit.org/latest/_tools_accuracy_checker_README.html)、低精度の量子化 (https://docs.openvinotoolkit.org/latest/_compression_algorithms_quantization_README.html) などのよく使用されるタスクを支援し、開発と展開プロセスをガイドします。
ディープラーニング・ワークベンチの主なツールと機能を見てみましょう。
1. 合理的なユーザー・インターフェイスからすべての開発ステップを実施
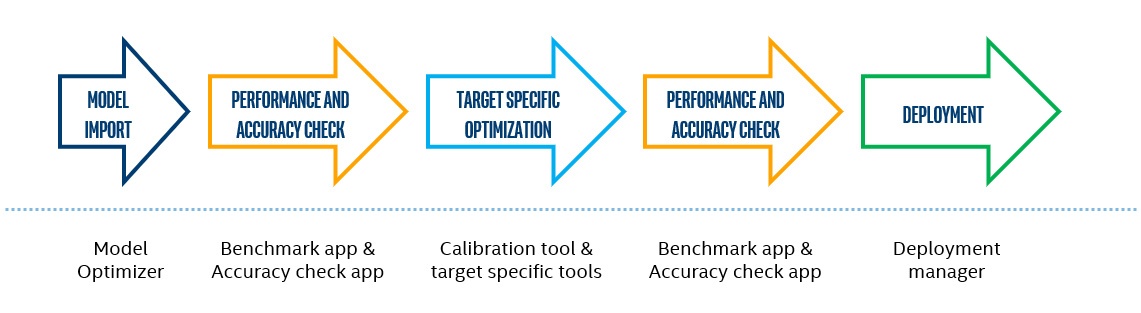
インテル® ディストリビューションの OpenVINO™ ツールキットを使用した開発には、次のステップが含まれます。
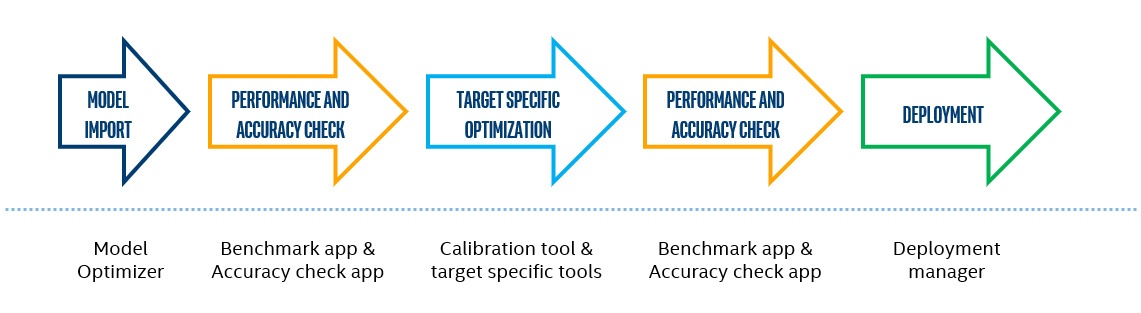
図 1. インテル® ディストリビューションの OpenVINO™ ツールキットを使用した開発の典型的なステップ
各ステップには、コマンドライン・オプションを介してすべての機能にアクセス可能な個別のツールが用意されており、開発者に高度なツール機能 (追加の量子化アルゴリズム設定、モデル・インポート・パラメーターなど) を提供し、柔軟でスケーラブルな開発と展開を可能にします。一部のツールには、すべてのツールで指定する必要がある類似の (または同じ) パラメーターがあります。例えば、特定のデータセットでモデルを検証するには、パスとデータセット・タイプを提供しなければならず、量子化ツールでも同じパスとタイプを提供する必要があります。ディープラーニング・ワークベンチは、シームレスなユーザー・インターフェイスで開発パイプラインを表現して、コマンドライン・ツールを利用して開発タスクを実行し、必要な機能のみを利用することで開発を合理化します。
ディープラーニング・ワークベンチは、以前のステップで入力されたすべての情報を記憶し、それを利用して後続の開発ステップを簡素化します。例えば、モデルインポート時にモデルタイプを指定すると、顧客データセットの精度を測定するアプリケーションでモデルタイプを再度指定する必要はありません。同様に、精度解析時にデータセットの場所とパスを指定すると、量子化パスでそれらの情報を再度指定する必要はありません。モデルの量子化 (ディープラーニング・ワークベンチから利用可能な機能の 1 つ) を実行すると、量子化モデルが生成され、データセットのパスを指定しなくても精度が自動的に測定されます。このように、ディープラーニング・ワークベンチは必要なすべての関連情報を 1 カ所に保持して開発を簡素化します。
開発フロー全体を簡素化するだけでなく、ディープラーニング・ワークベンチは各開発ステップにおいてユーザー・インターフェイスで追加の機能も提供します。
2. モデルインポートを支援
ディープラーニング・モデルを使用することでより多くのタスクに対応できるため、新しいアーキテクチャーが追加され、既存のアーキテクチャーの複雑さが増します。インテル® ディストリビューションの OpenVINO™ ツールキットは、モデル・オプティマイザー (英語) と個々のハードウェア・プラグインの定期的なアップデートにより最新の状態に保たれます。これらのアップデートは、モデル・オプティマイザーの複雑さを増し、モデルインポートの選択プロセスが複雑になる可能性があります。
アップデートによる複雑さを軽減するため、ディープラーニング・ワークベンチはさまざまなモデルグラフ解析手法を利用してワークフローを簡素化します。これらの手法は、推論用にモデル・オプティマイザーを使用してモデルを中間表現 (IR) に変換する際のパラメーターの数を減らします。モデルインポート時、ワークベンチは最初にモデルを解析して、インポートを簡素化するためモデルタイプ、入力、出力、その他の特性の識別を試みます。
インテル® ディストリビューションの OpenVINO™ ツールキットの Open Model Zoo (英語) のモデルを使用する場合、便利なインターフェイスを利用してモデルを選択し、オプションを全く指定しないで自動的にインポートできます。
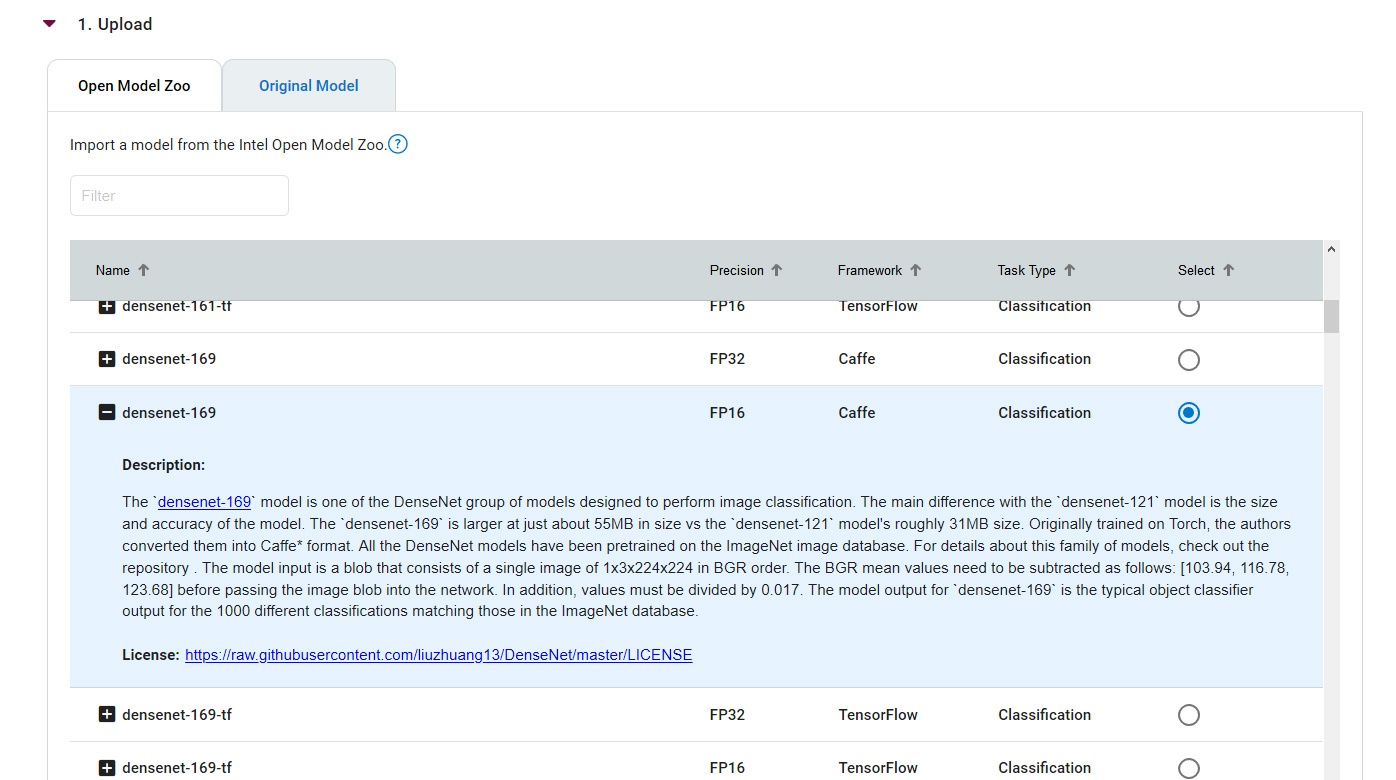
図 2. Open Model Zoo で公開されている事前トレーニング済みモデルのインポート
3. パフォーマンスと精度の詳細情報
モデルインポート後、開発者が最初に確認したいことは、モデルがどれぐらい高速で正確かです。インテル® ディストリビューションの OpenVINO™ ツールキットは、ベンチマークと精度を測定するツールを提供します。ディープラーニング・ワークベンチには、必要なツールがすべて備わっています。
パフォーマンスを測定すると、全体的なパフォーマンスだけでなく、トポロジーの特定の部分が実行全体に与える影響を理解することができます。ディープラーニング・ワークベンチは、層ごとの詳細なタイミング情報、発生した融合に関する情報、完全なランタイムグラフを提供します。この情報に基づいて、開発者はモデルのトレーニング中に特定の層を置換または変更してトポロジーを調整し、パフォーマンスを向上できます。例えば、重い ELU 活性化を軽量の ReLU に置き換えると、パフォーマンスが向上します。
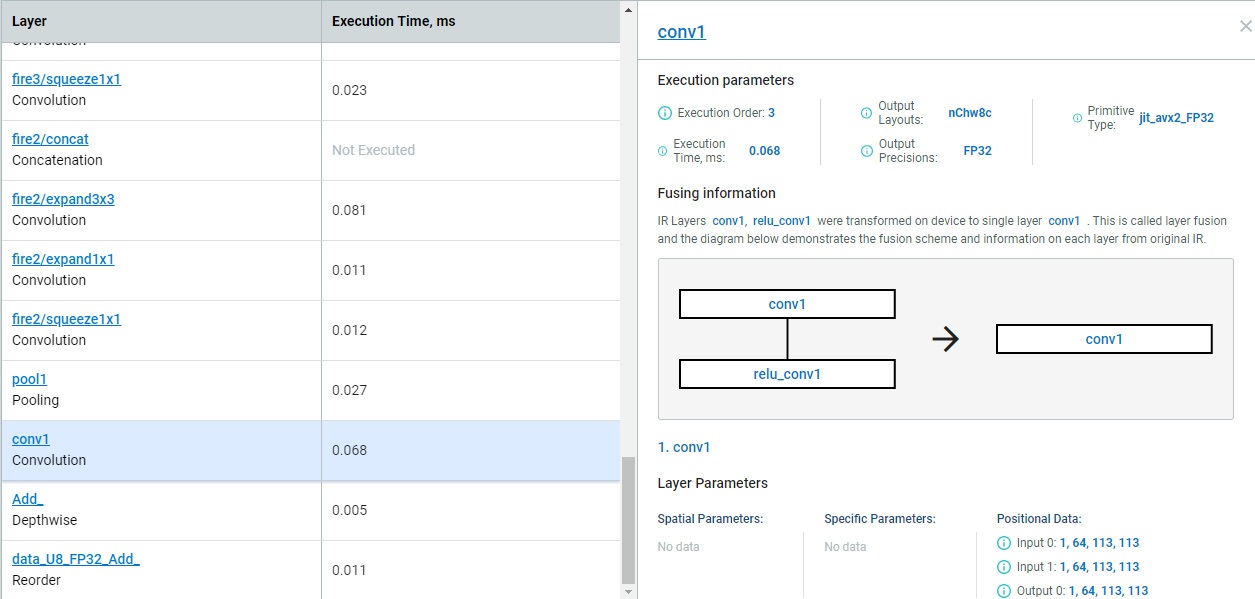
図 3. 層ごとの実行パフォーマンスとグラフの最適化に関する詳細な情報
パフォーマンスが向上した後に、トポロジーが正しく実行していることを確認したい場合があります。トポロジータイプなどの主要パラメーターと必要な前処理を指定して、データセットを提供すると、ディープラーニング・ワークベンチはモデル精度メトリックを出力します。現在は、ImageNet、Pascal VOC、そして最近追加された COCO など、対応するデータセット・タイプを使用した分類およびオブジェクト検出トポロジーをサポートしています。開発を合理化するため、さまざまなタスクに対応するトポロジータイプとデータセットが継続的に追加されています。
4. 容易な低精度の量子化
新しい世代のインテル® ハードウェアには、複数のディープラーニング・アクセラレーション・オプションがあります。例えば、第 2 世代インテル® Xeon® スケーラブル・プロセッサーは、インテル® ディープラーニング・ブースト機能により優れた INT8 パフォーマンスを提供します。インテルは、AI の将来に対する顧客の計算ニーズを満たす機敏性を備えたプラットフォームを提供します。これらの新しい世代の機能を利用するには、まず INT8 などの低精度のデータ型で実行するようにモデルを準備する必要があります。インテル® ディストリビューションの OpenVINO™ ツールキットで利用可能なオプションの 1 つ、INT8 などのデータ型への低精度の量子化を行うトレーニング後の最適化は、精度をあまり損なうことなくパフォーマンスを向上します。最新バージョン (英語) のインテル® ディストリビューションの OpenVINO™ ツールキットでは、合理化的な開発者体験とハイパフォーマンスのディープラーニングを実現する、トレーニング後の最適化ツール (https://docs.openvinotoolkit.org/latest/_README.html) がディープラーニング・ワークベンチで利用できるようになりました。
精度測定時にインポートしたモデルとデータセットを使用して、トレーニング後の最適化ツールで量子化を実行することができます。完了後、量子化モデルのパフォーマンスと精度を再度測定して、INT8 実行の影響を理解できます。さらに、層ごとのパフォーマンス比較を実行して利点を判断できます。
量子化モデルとオリジナルモデルのパフォーマンスと精度の結果は 1 カ所に表示されます。また、同じモデルとデータセットを使用して、CPU、統合 GPU、その他のサポートされるデバイスでモデルを試して、すべての結果をまとめて確認できます。そのため、ユーザーは十分な情報に基づいて、ハードウェアとソフトウェアの組み合わせを選択できます。さらに、特定のワークロードの実行に最適なハードウェアの決定を支援するため、インテル® デベロッパー・クラウドでは、ハードウェアを購入する前にリモートアクセスで新しいインテル® アーキテクチャーを試したり、エッジ AI ワークロードを実行することができます。
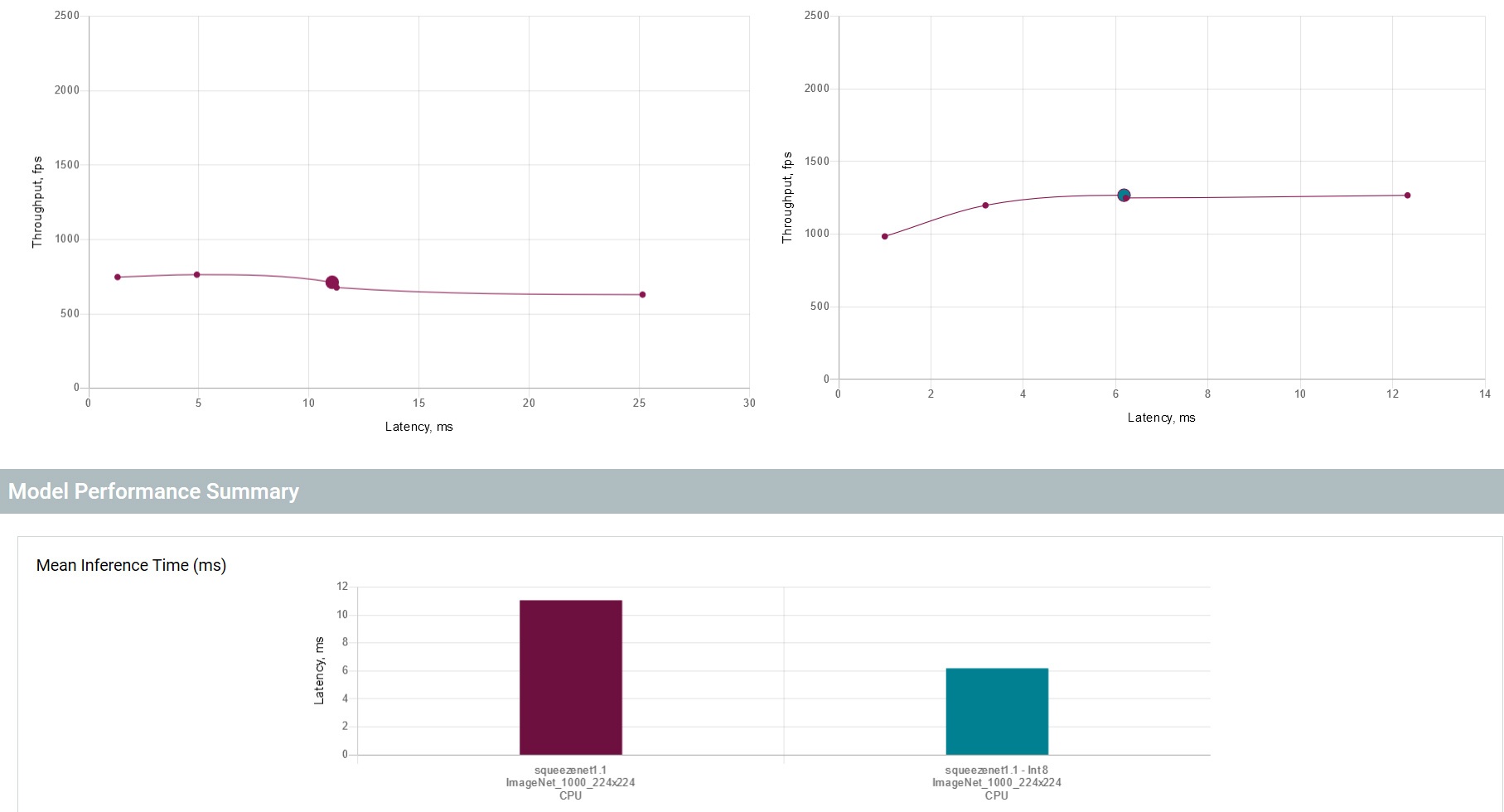
図 4. 最適化されたモデルとオリジナルのモデルのパフォーマンス比較
量子化モデルは、モデル・オプティマイザーを実行して、モデルを中間表現 (IR) に変換 (英語) することで取得できます。
5. バッチ処理するかどうか
ディープラーニングのパフォーマンスは、トポロジーの計算に必要な計算とシステムで利用可能な計算から派生したものと見なされることがよくありますが、この GPU セントリックのアプローチは、パフォーマンスを評価する単純な方法です。入力解像度、計算精度、トポロジー構造、層の種類、ターゲット・ハードウェア・アーキテクチャーを含む多くの要因がモデルの最終的なパフォーマンスに影響します。大きなバッチサイズや複数の並列推論ストリーム (英語) で最適に動作するターゲットとトポロジーの組み合わせもあれば、これらによってパフォーマンスが低下する組み合わせもあります。パフォーマンスの予測は非常に複雑であり、従来の試行錯誤アプローチが最も効果的です。
そのため、ディープラーニング・ワークベンチは、パフォーマンスの詳細を提供するだけでなく、モデルとターゲットのさまざまな組み合わせに対して異なる実行オプションを試すことができます。異なるパラメーターを使用する複数の試行を自動化し、各シナリオのパフォーマンスとレイテンシーを示すグラフを生成します。ユーザーは、使用するパラメーターの範囲を選択して、便利な方法ですべてのパラメーターの結果を確認できます。
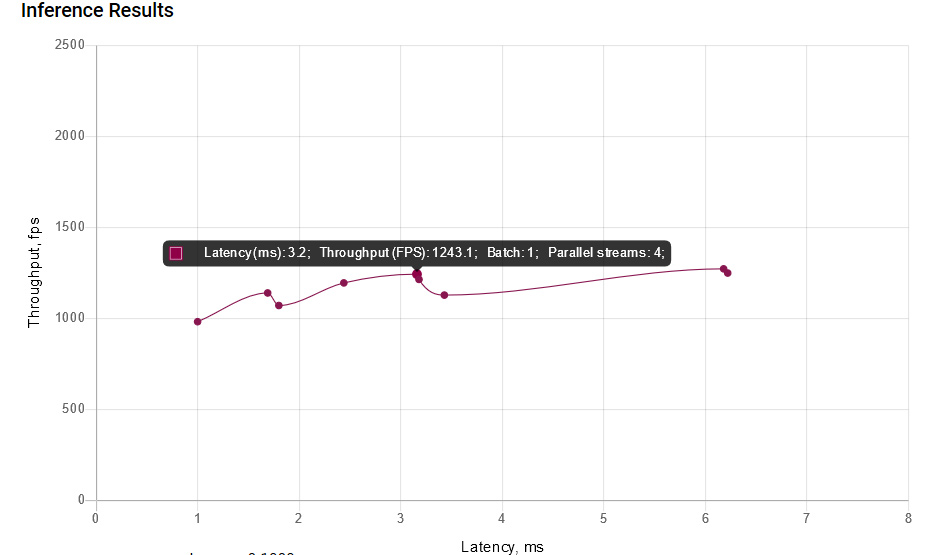
図 5. 最適な実行パラメーターの選択を支援するパフォーマンス・グラフ
まとめ
インテル® ディストリビューションの OpenVINO™ ツールキットは、リリースのたびにツールと機能が強化されており、トレーニング済みモデルの使用からさまざまなインテル® アーキテクチャーへの展開に至るまで、合理的なエンドツーエンドの開発体験を可能にします。インテル® ディストリビューションの OpenVINO™ ツールキットに含まれるディープラーニング・ワークベンチは、便利なユーザー・インターフェイスとカスタマイズ機能のセットによりこのワークフローをさらに簡素化します。モデルインポートからキャリブレーション/量子化、モデルの最適化、その他の測定に至るまで、ディープラーニング・ワークベンチは開発を容易に行えるように設計されています。インテルは、継続的な改善に取り組んでいます。ディープラーニング・ワークベンチを試して、フィードバック (英語) をお寄せください。
ディープラーニング・ワークベンチの YouTube* 動画 (英語) も併せてご覧ください。
法務上の注意書き
最適化に関する注意事項
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。
絶対的なセキュリティーを提供できる製品またはコンポーネントはありません。
実際の費用と結果は異なる場合があります。
© Intel Corporation. Intel、インテル、Intel ロゴ、OpenVINO は、アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です。* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
