

oneAPI を活用して AI ワークロードのエンドツーエンドのパフォーマンスを実現
機能 AI ツールセレクター ドキュメントとサンプルコード トレーニング 仕様 ヘルプ
データサイエンスと AI パイプラインを加速 |
|
インテルの AI ツール (旧称: インテル® AI アナリティクス・ツールキット) は、データ・サイエンティスト、AI 開発者、研究者向けに使い慣れた Python* ツールとフレームワークを提供し、インテル® アーキテクチャー上でエンドツーエンドのデータサイエンスと分析パイプラインを高速化します。 コンポーネントは、低レベルのコンピューティングを最適化するため oneAPI ライブラリーを使用して構築されます。AI ツールは、前処理からマシンラーニングまでのパフォーマンスを最大化し、効率的なモデル開発のための相互運用性を提供します。 AI ツールを利用すると次のことが可能になります。
|
AI ツールをダウンロード最適化されたディープラーニング・フレームワークと高性能 Python* ライブラリーにより、エンドツーエンドのマシンラーニングとデータサイエンスのパイプラインを高速化します。 ツールを入手 (英語) クラウドで開発インテルによって最適化された最新の oneAPI および AI ツールを使用して oneAPI マルチアーキテクチャー・アプリケーションを構築および最適化し、インテルの CPU および GPU 全体でワークロードをテストします。ハードウェアのインストールやソフトウェアのダウンロード、設定などは必要ありません。 |
最新情報 |
|
|
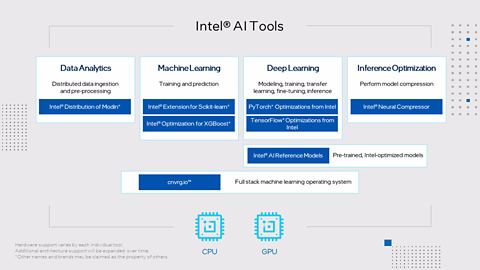
機能最適化されたディープラーニング
|
ハイパフォーマンスな Python*
|
データ解析とマシンラーニングの加速
|
マルチノードのデータフレームにわたるスケーリングを簡素化
|
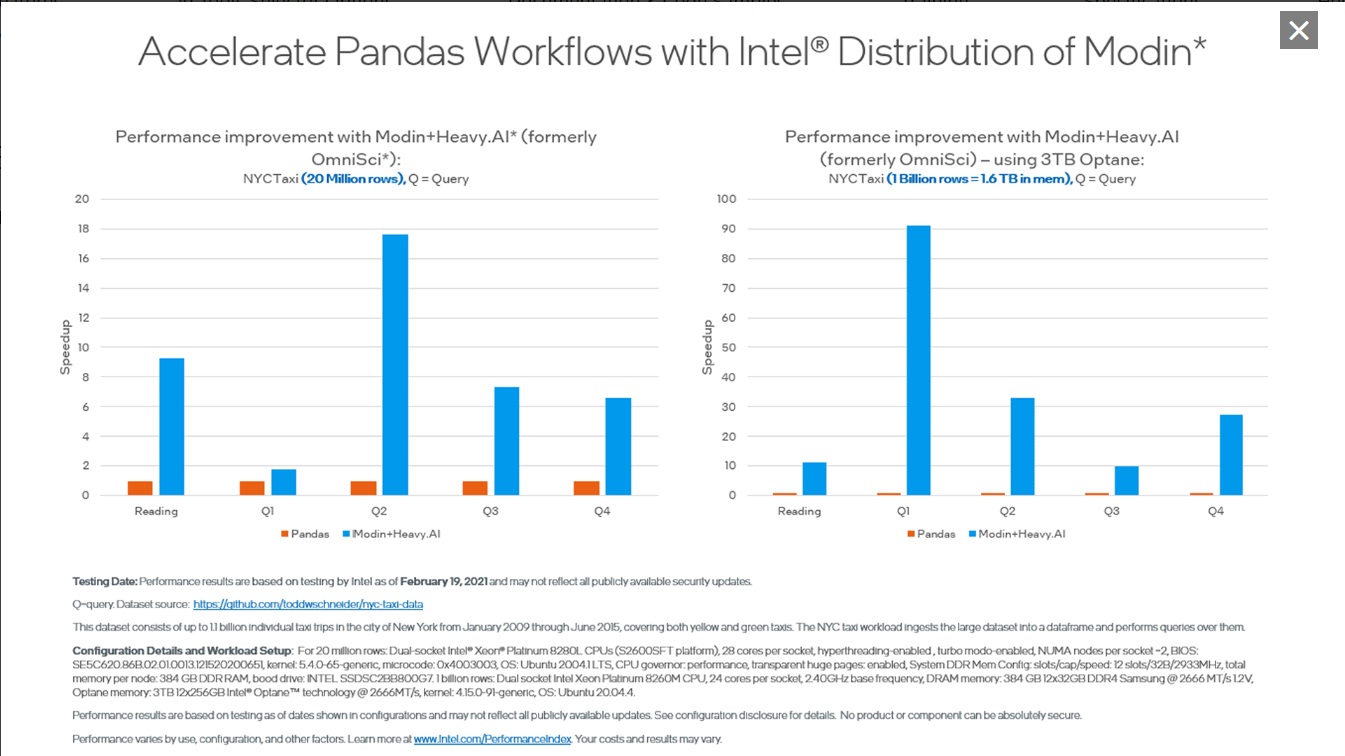
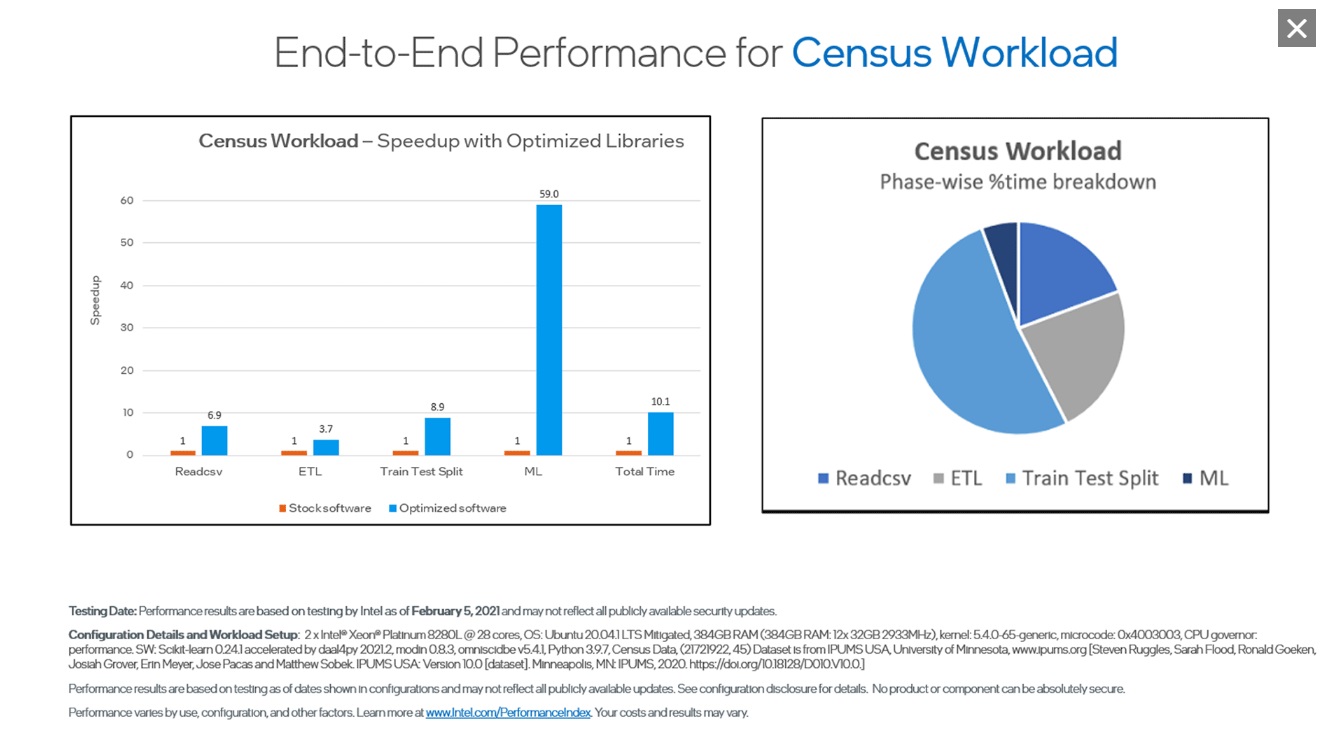
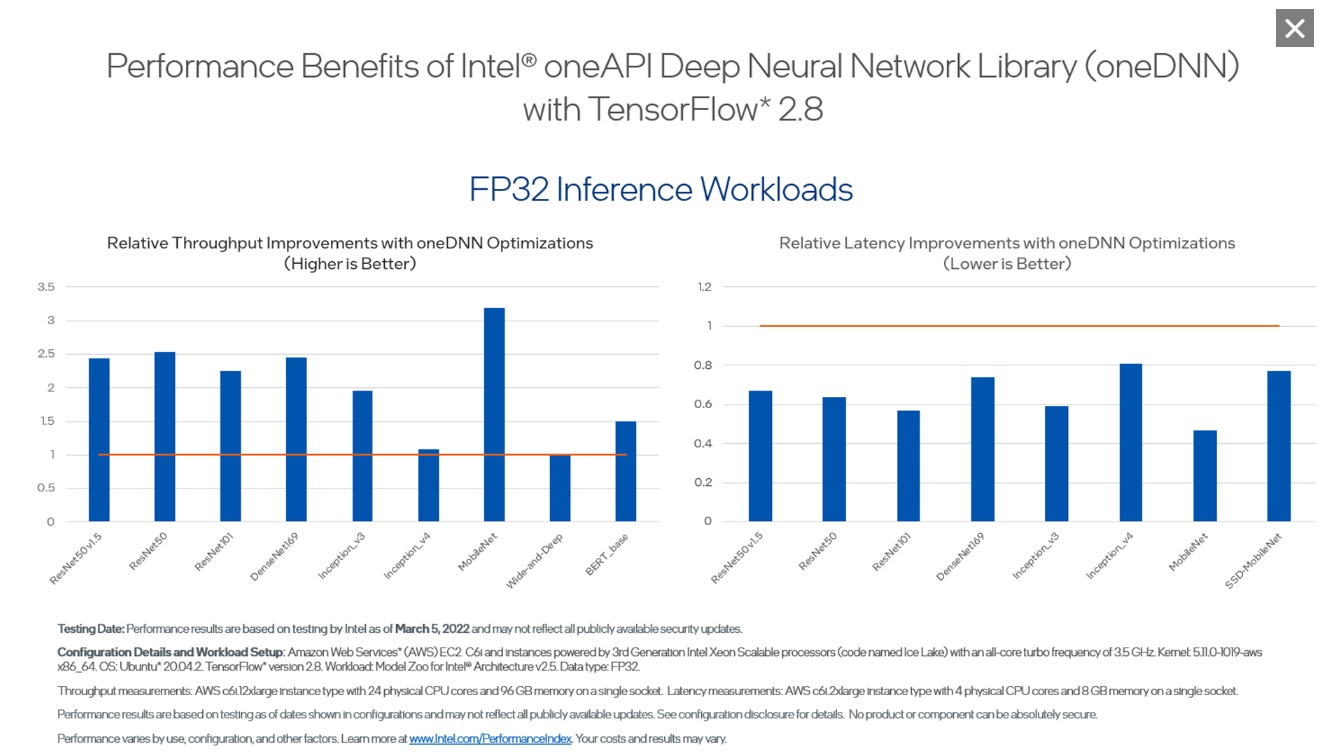
ベンチマークこれらのベンチマークは、インテルの AI ツールのパフォーマンス能力を示しています。クリックして拡大できます。 |
|
|
|
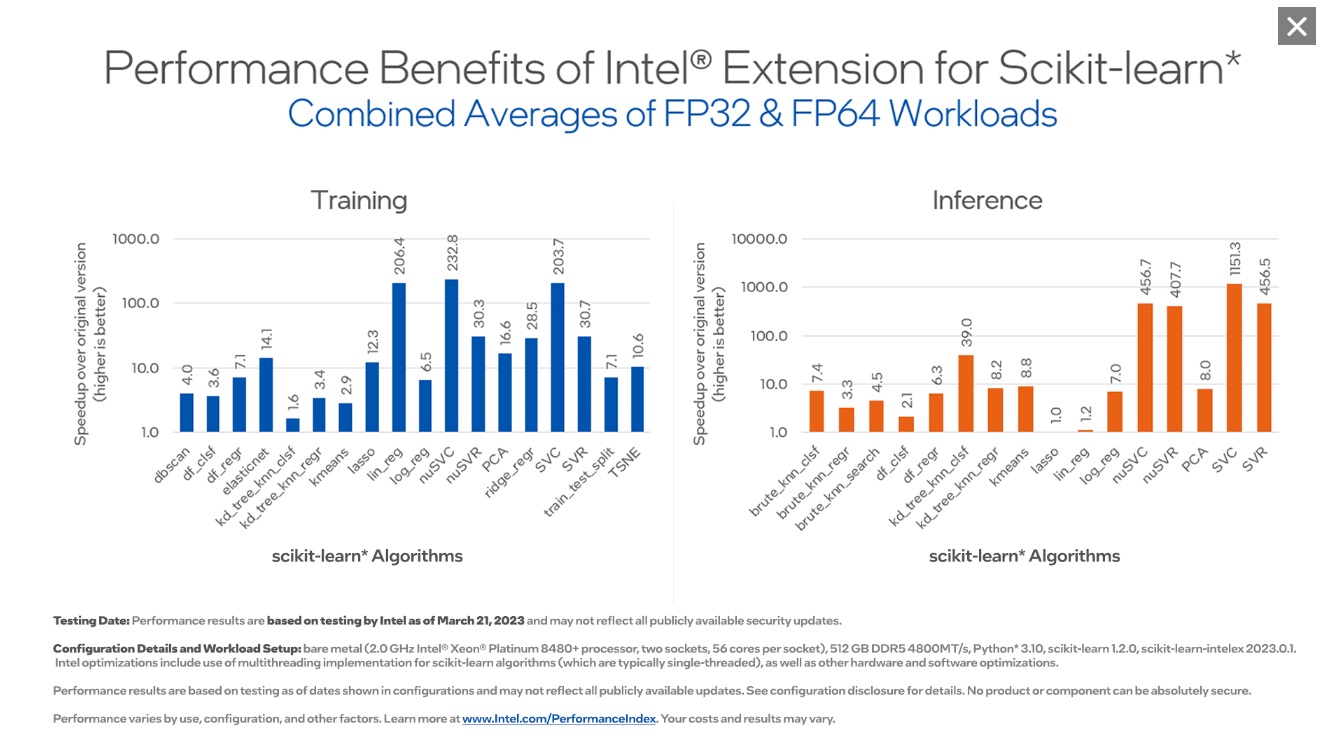
|
デモ |
||
|
Hugging Face と oneAPI を使用した Falcon 70 億パラメーター・モデルの調整 インテルの Hugging Face* API と AI ツールを使用して、インテル® AMX をサポートするインテル® Xeon® プロセッサー上で Falcon 大規模言語モデル (LLM) を最適化する課題に触れてください。 |
言語識別: PyTorch* を使用したエンドツーエンド AI ソリューションの構築 (英語) この詳細なソリューションでは、言語識別を実行し、量子化によってモデルを最適化するようにモデルをトレーニングする方法を示します。 さらに詳しく (英語) |
インテル® AI アクセラレーションによる環境に優しいマシンラーニングの計算 (英語) Anaconda* は、インテルによって最適化された scikit-learn* が AI 環境への影響を 1/7 に軽減し、計算速度を 8 倍向上させることを示しています。 さらに詳しく (英語) |
ケーススタディー |
|
インテルのソフトウェア開発ツールがどのように IBM Watson* NLP ライブラリーを高速化するか (英語) インテルと IBM は、IBM Watson* 自然言語処理ライブラリー (NLP) で協力し、oneAPI ツールを使用して最適化することで最大 165% の改善を達成しました。 さらに詳しく (英語) |
Netflix でのビデオ配信と推奨 (英語) Netflix のパフォーマンス・エンジニアリング・チームは、インテル® ソフトウェアによる最適化を使用してインテル® ハードウェア機能の利点を最大限に活用することで、クラウドとストリーミングのコストを削減しながら、視聴者のエクスペリエンスを向上させました。 さらに詳しく (英語) |
HippoScreen* は、oneAPI ツールを使用して AI パフォーマンスを 2.4 倍向上 (英語) 台湾を拠点とするニューロテクノロジーのスタートアップ企業は、インテルの AI ツールとインテル® VTune™ プロファイラーを併用して、脳波 AI システムで使用されるディープラーニング・モデルの効率と構築時間を改善しました。 さらに詳しく (英語) |
AI ツールセレクターで利用可能な選択肢 |
|
|
インテルは PyTorch* への最大の貢献者であり、PyTorch* ディープラーニング・フレームワークに定期的なアップストリームの最適化を行い、インテル® アーキテクチャー上で優れたパフォーマンスを提供しています。 AI ツールセレクターには、他のツールとの連携がテストされた PyTorch* の最新バイナリーバージョンと、最新のインテルの最適化機能と使いやすい機能を追加する PyTorch* 向けインテル® エクステンションが含まれています。 TensorFlow* は、Google* と協力してインテル® oneAPI ディープ・ニューラルネットワーク・ライブラリー (インテル® oneDNN) のプリミティブを使用して、インテル® アーキテクチャー向けに直接最適化されています。 AI ツールセレクターは、CPU 向けにコンパイルされた最新のバイナリーバージョンと、ストックバージョンにシームレスに接続して新しいデバイスと最適化のサポートを追加する TensorFlow* 向けインテル® エクステンションを提供します。 インテル® ニューラル・コンプレッサー (英語) モデルのサイズを削減し、CPU または GPU に展開される推論を高速化します。オープンソース・ライブラリーは、量子化、枝刈り、知識の蒸留などのモデル圧縮技術を実行するためフレームワークに依存しない API を提供します。 cnvrg.io (英語) あらゆるインフラストラクチャー上でモデルを構築、展開、管理する簡単な方法で、再現性を実現します。 cnvrg.io™ は、すべての AI プロジェクトを 1 カ所から管理できるフルサービスのマシンラーニングのオペレーティング・システムです。 cnvrg.io はオプションのコンポーネントであり、別途ライセンスが必要です。 |
scikit-learn* 向けインテル® エクステンション (英語) シングルノードとマルチノードにわたるインテルの CPU および GPU 上の scikit-learn* アプリケーションをシームレスに高速化します。この拡張パッケージは、scikit-learn* エスティメーターに動的にパッチを適用して、インテル® oneAPI データ分析ライブラリー (インテル® oneDAL) をソルバーとして使用すると同時に、マシンラーニング・アルゴリズムの高速化を実現します。AI ツールセレクターには、必要なすべてのパッケージがインストールされた包括的な Python* 環境を提供するストック scikit-learn* も含まれています。 この拡張機能は、scikit-learn* の最新の 4 つのバージョンまでサポートするため、既存のパッケージで使用する柔軟性があります。 XGBoost 向けインテル® オプティマイゼーション (英語) インテルは XGBoost コミュニティーと協力して、インテル® CPU 上で優れたパフォーマンスを提供するために多くの最適化を直接アップストリームしてきました。 勾配ブースト・デシジョン・ツリー向けのよく知られたマシンラーニング・パッケージには、インテル® アーキテクチャー向けのシームレスなドロップイン・アクセラレーションが含まれており、モデル・トレーニングを大幅に高速化し、精度を向上させて予測を改善します。 Modin 向けインテル® ディストリビューション (英語) Pandas と同一の API を備えたこのインテリジェントな分散データ・フレーム・ライブラリーを使用して、pandas ワークフローを高速化し、マルチノード間でデータ前処理を拡張します。 このライブラリーは、ヘテロジニアス・データ・カーネル (HDK)、Dask*、Ray、または HEAVY.AI* 計算エンジンと統合されており、コードを記述することなくデータを分散できます。 |
|
インテルは、AI ツールセレクターで利用可能なツールに加えて、AI ソフトウェア・ツールの完全なスイートを提供しています。 |
|
ドキュメントとサンプルコード |
|
ドキュメント
すべてのドキュメントを表示 (英語) |
サンプルコード
|
トレーニング |
仕様プロセッサー
言語
|
オペレーティング・システム
開発環境
分散環境
|
|
サポート状況はツールによって異なります。 詳細については、システム要件を参照してください。 |
|
ヘルプ (フォーラム)皆さんの成功は私たちの成功です。サポートが必要な場合は、次のサポートリソースにアクセスしてください。 |
コードに関連するすべての情報を常に把握サインアップすると、CPU、GPU、FPGA、およびその他のアクセラレーター (スタンドアロンや任意の組み合わせ) に最適化され、優れたコードを作成するのに役立つ最新のトレンド、チュートリアル、ツール、トレーニングなどを受けることができます。 |
