




NEW! iSUS で特別に公開中の日本語版パッケージ & ドキュメントはこちら
-
Transformers による GGUF モデルの高速化
この記事は、The Parallel Universe Magazine 57 号に掲載されている「Accelerating GGUF Models with Transformers」の日本語参考訳…

-
パート 1: CUDA* から SYCL* と oneAPI へ AI コードを移行
この記事は 2024年7月31日に Codeplay のウェブサイトで公開された「Part One – Porting AI codes from CUDA to SYCL and one…

-
Intel Vision 2024 のエンタープライズ AI アート展
この記事は、The Parallel Universe Magazine 57 号に掲載されている「Enterprise AI Art Exhibition at Intel Vision 2024」…

-
インテル® Gaudi® 2 AI アクセラレーター上での Prediction Guard のプライバシー保護 LLM プラットフォームのスケーリング
この記事は、インテルのサイトで公開されている「Scaling Prediction Guard’s Privacy-Conserving LLM Platform on an Intel®…
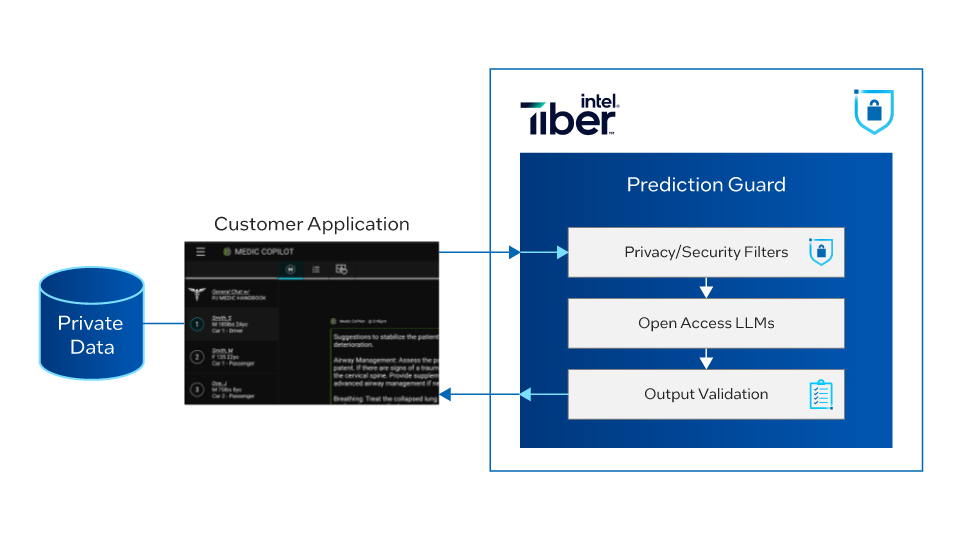
-
低ビットの量子化されたオープン LLM リーダーボード
この記事は、The Parallel Universe Magazine 57 号に掲載されている「Low-Bit Quantized Open LLM Leaderboard」の日本語参考訳です。原…

-
インテル® Gaudi® 2 AI アクセラレーターとインテル® Xeon® プロセッサーを使用したコスト効率の高いエンタープライズ RAG アプリケーションの構築
この記事は、Hugging Face* のサイトで公開されている「Building Cost-Efficient Enterprise RAG applications with Intel Gaud…

-
インテル Parallel Universe 57 号日本語版の公開
インテル Parallel Universe マガジンの最新号 (英語) が公開されました。 注目記事: AI PC により大規模な LLM 開発がデスクトップで可能に 掲載記事 低ビットの量子化され…

-
OpenVINO™ ツールキットの重み圧縮を使用して LLM のフットプリントを削減する
この記事は、Medium に公開されている「Reduce LLM Footprint with OpenVINO™ Toolkit Weight Compression」の日本語参考訳です。原文は更新…

-
インテル® データ・ストリーミング・アクセラレーターを使用したメモリー帯域幅依存カーネルの高速化
この記事は、The Parallel Universe Magazine 57 号に掲載されている「Accelerate Memory-Bandwidth-Bound Kernels Using th…

-
OpenVINO™ ツールキットを使用して高速で小さな LLM をデプロイする理由と方法
この記事は、Medium に公開されている「Why and How to Use OpenVINO™ Toolkit to Deploy Faster, Smaller LLMs」の日本語参考訳です。…

