

この記事は、インテル® デベロッパー・ゾーンに掲載されている「Getting the Most from OpenCL™ 1.2: How to Increase Performance by Minimizing Buffer Copies on Intel® Processor Graphics」の日本語参考訳です。
ダウンロード
OpenCL* ゼロコピー・サンプルコード [ZIP 22.4KB]
はじめに
この記事は、インテル® プロセッサー・グラフィックスで実行するアプリケーションを最適化するためのガイダンスを OpenCL* を使用する開発者に提供します。特に、アプリケーションのメモリー・フットプリントを最小限に抑え、インテル® システム・オン・チップ (SoC) ソリューションの共有物理メモリーシステムでバッファーのコピー減らす方法をサンプルコードによって説明します。使用するサンプルコードはダウンロードすることができます。
OpenCL* 1.2 仕様には、アプリケーションのメモリー・フットプリントを抑え、パフォーマンスを最大限に引き出すことができるメモリー割り当てフラグと API 関数が含まれています。これは、実行中の余分なコピー処理を排除するゼロコピー動作により実現されます。この記事では、この OpenCL* API 仕様について、インテル® プロセッサー・グラフィックスに注目して詳しく説明します。
概要
ゼロコピー・バッファーを作成するには、次のいずれかを行います。
- CL_MEM_ALLOC_HOST_PTR を指定し、ゼロコピー割り当てバッファーの作成をランタイムに任せます。
- すでにあるデータを OpenCL* バッファー・オブジェクトにロードする場合は、CL_MEM_USE_HOST_PTR を指定し、4096 バイト境界で割り当てられた (つまり、ページとキャッシュライン境界でアライメントされた)、合計サイズが 64 バイト (キャッシュラインのサイズ) の倍数であるバッファーを使用します。
ホストからこれらのバッファーのデータを読み書きする場合は、clEnqueueMapBuffer() を使用し、バッファーを処理したら、clEnqueueUnmapMemObject() を呼び出します。この記事では、サンプルコードを使ってインテル® プラットフォームで最も一般的な手法を説明します。
目的
GPU ドライバーのメモリー管理にはさまざまなメモリー使用シナリオがあり、これらを考慮する必要があります。アプリケーションは、メモリー割り当て時にフラグを指定したり、実行時に特定のメモリーアクセスまたは転送 API を呼び出すことで、ドライバーに使用シナリオを知らせることができます。場合によっては、これらの API 呼び出しが処理されるように、ドライバー実装がメモリーバッファーの内部コピーを作成したり、管理する必要があります。例えば、CPU や GPU に適したメモリー配置をサポートしたり、キャッシュ効率を向上するため、メモリーバッファーの内部コピーが作成されます。この場合パフォーマンスが低下します。このようなコピーを回避するには、デバイス固有の知識が必要になります。
定義
技術的な説明に入る前に、以下はこの記事で使用する用語の定義です。
- ホストメモリー: OpenCL* ホストでアクセス可能なメモリー。
- デバイスメモリー: OpenCL* でアクセス可能なメモリー。
- ゼロコピー: データのコピーを減らすことで、パフォーマンスを向上し、アプリケーション全体のメモリー・フットプリントを減らすため、ホスト (ここでは CPU) とデバイス (ここでは内蔵 GPU) 間でメモリーの同じコピーを使用すること。
- ゼロコピー・バッファー: ゼロコピー・ルールに従って clCreateBuffer() API により作成されたバッファー。ルールは実装依存なので、デバイスにより異なる可能性があります。
- 共有物理メモリー: ホストとデバイスが同じ物理 DRAM を共有すること。ホストとデバイスが同じ仮想アドレスを共有する、共有仮想メモリーとは異なります (共有仮想メモリーはこの記事では取り上げません)。ゼロコピーを有効にするには、CPU と GPU が共有物理メモリーを使用する必要があります。共有物理メモリーと共有仮想メモリーは相互排他ではありません。
- 仮想メモリー: オペレーティング・システムのメモリーモデルにより、プロセスは専用のメモリー空間を与えられます。プログラムで使用されるポインターは物理メモリーアドレスではなく、仮想アドレス空間の仮想アドレスを指します。仮想アドレスと物理メモリーアドレスの変換はプラットフォームによって処理されます。
- インテル® プロセッサー・グラフィックス: 現在のインテル® グラフィックス・ソリューションを指します。SoC 内蔵 GPU には、インテル® Iris™ グラフィックス、インテル® Iris™ Pro グラフィックス、インテル® HD グラフィックスなどがあります。ハードウェア・アーキテクチャーの詳細は、「参考文献」にある「The Compute Architecture of Intel® Processor Graphics Gen7.5」または http://ark.intel.com/ (英語) を参照してください。
インテル® プロセッサー・グラフィックスと共有物理メモリー
インテル® プロセッサー・グラフィックスは CPU とメモリーを共有します。図 1 にこの関係を示します。この図には示されていませんが、メモリー・サブシステムを拡張するいくつかのアーキテクチャー機能があります。例えば、メモリー・サブシステムのパフォーマンスを最大限に引き出せるように、キャッシュ階層、サンプラー、アトミックサポート、読み取り/書き込みキューなどが利用されます。
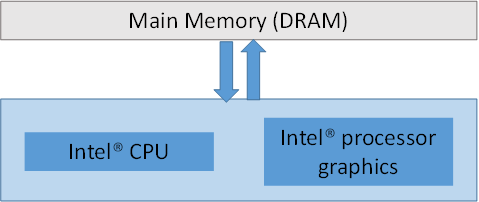
図 1. CPU、インテル® プロセッサー・グラフィックス、メインメモリーの関係。
ドライバーによって管理される専用メモリーがある外付け GPU とは違い、
CPU と GPU で 1 つのメモリープールが共有されているのが分かります。
ゼロコピーの利点
インテル® プロセッサー・グラフィックスでは、ゼロコピーを使用すると、ホスト/デバイスでコピーを作成する場合よりもパフォーマンスが向上します。NUMA を採用するほかのアーキテクチャーと異なり、CPU/GPU どちらからでも共有メモリーに効率良くアクセスできます。
OpenCL* のメモリーバッファー
OpenCL* のバッファー操作のパフォーマンスは、OpenCL* 実装により異なります。ここでは、インテル® プロセッサー・グラフィックスでの動作について説明します。
clCreateBuffer() でバッファーを作成する
OpenCL* の 1 つ目の使用例として、ホストでメモリーに生成済みのデータをデバイスで読み取る場合があります。この場合、CL_MEM_USE_HOST_PTR を指定してバッファーを作成します。既存のコードで OpenCL* を使用する場合などが考えられます。CL_MEM_USE_HOST_PTR フラグを使用する場合、インテル® プロセッサー・グラフィックスでゼロコピー・バッファーを保証するには、デバイス依存のアライメントとサイズのルールに従う必要があります。バッファーは 4096 バイト境界でアライメントされ、バッファーサイズは 64 バイトの倍数でなければなりません。また、このバッファーへ書き込む場合、オリジナルのコンテンツは上書きします。バッファーがこの条件を満たしているかどうかテストするコードを以下に示します。
CL_MEM_USE_HOST_PTR: malloc() の代わりに、_aligned_malloc() によりページ境界でアライメントされ、サイズが 64 バイトの倍数であるバッファーがすでに割り当てられている場合はこのフラグを使用します。
int *pbuf = (int *)_aligned_malloc(sizeof(int) * 1024, 4096);
_aligned_malloc() を使用する場合、_aligned_free() で割り当てを解除する必要があります。Linux*、Android*、Mac OS* では、ドキュメントの mem_align() または posix_memalign() の説明を参照してください。_aligned_malloc() で割り当てたメモリーに free() は使用しないでください。次のコードでバッファーと関連する cl_mem オブジェクトを作成します。
cl_mem myZeroCopyCLMemObj = clCreateBuffer(ctx,…CL_MEM_USE_HOST_PTR…);
OpenCL* の 2 つ目の使用例として、デバイスでデータを生成しホストで読み取る場合があります。この場合、CL_MEM_ALLOC_HOST_PTR フラグを指定してデータを作成します。メモリーがアライメントとサイズのルールに従って適切なベースアドレスに割り当てられているか確認する必要はありません。ランタイムによってチェックされます。
OpenCL* の 3 つ目の使用例として、アプリケーションがバッファーの初期化を制御し、データはホストで生成される場合があります。この場合、バッファーを作成してから初期化します。例えば、ファイルから入力を読み取る場合などが考えられます。このケースと CL_MEM_USE_HOST_PTR を使用するケースの違いは、バッファーにすでにデータが生成されているかどうかです。バッファーを初期化するには、後述の OpenCL* の割り当て/割り当て解除 API 関数を使用します。
CL_MEM_ALLOC_HOST_PTR: このフラグは、まだメモリーを割り当てていないときに OpenCL* でゼロコピー・バッファーを保証する場合に使用します。
buf = clCreateBuffer(ctx, ….CL_MEM_ALLOC_HOST_PTR, ….)
表 1: インテル® プロセッサー・グラフィックスでゼロコピー・バッファーを有効にするため clCreateBuffer() に渡すフラグとその使用シナリオ
| フラグ | ゼロコピーを有効にするシナリオ |
|---|---|
| CL_MEM_USE_HOST_PTR |
|
| CL_MEM_ALLOC_HOST_PTR |
|
| CL_MEM_ALLOC_HOST_PTR | CL_MEM_COPY_HOST_PTR |
|
インテル® プロセッサー・グラフィックスでは、ほとんどの場合 CL_MEM_ALLOC_HOST_PTR を使用できます。バッファーを初期化する場合は必ず、最初にバッファーを割り当て、バッファーへ書き込みを行ったら、バッファーの割り当てを解除します。アライメントとサイズのルールに従ってデータがすでに生成されている場合は、CL_MEM_USE_HOST_PTR を使用できます。
次の C ショート関数は、ポインターと割り当てサイズがアライメントとサイズのルールに従っているかどうかチェックします。
unsigned int verifyZeroCopyPtr(void *ptr, unsigned int sizeOfContentsOfPtr)
{
int status; // 関数の終了ポイントは 1 つだけ
if((uintptr_t)ptr % 4096 == 0) // ページとキャッシュのアライメント
{
if(sizeOfContentsOfPtr % 64 == 0) // キャッシュサイズの倍数
{
status = 1;
}
else status = 0;
}
else status = 0;
return status;
}
ホストでバッファーにアクセスする
ホストで直接バッファーにアクセスする場合、ゼロコピー・バッファーかどうかに関係なく、OpenCL* 1.2 でバッファーを割り当て/割り当て解除する必要があります。詳細は後述の説明とサンプルコードを参照してください。
デバイスでバッファーにアクセスする
デバイスでバッファーにアクセスする場合、ほかのバッファーと同じようにアクセスでき、コード変更は不要です。ホスト側の処理と割り当て/割り当て解除 API に気を付ければ良いだけです。
clEnqueueMapBuffer() と clEnqueueUnmapMemObject() の使用
clEnqueueReadBuffer()、clEnqueueWriteBuffer()、clEnqueueCopyBuffer() の使用は推奨しません。これらの API はバッファー・コンテンツのコピーが必要になるため、特に大きなバッファーでは使用しないほうが良いでしょう。しかし、場合によっては、これらの API が役立つことがあります。例えば、ダブル・バッファリングを行うため、バッファー・コンテンツを読み取り GPU ですぐに再利用する場合、ホスト側でコピーを作成し、デバイスがオリジナルバッファーを操作できるようにすると便利です。ホストでインテル® プロセッサー・グラフィックスと共有しているメモリーバッファーへの読み取り/書き込みアクセスを行う場合は、clEnqueueMapBuffer() と clEnqueueUnmapMemObject() を使用します。
clEnqueueMapBuffer() の使用例:
mappedBuffer = (float *)clEnqueueMapBuffer(queue, cl_mem_image, CL_TRUE, CL_MAP_READ, 0, imageSize, 0, NULL, NULL, NULL);
clEnqueueUnmapMemObject() の使用例:
clEnqueueUnmapMemObject(queue, cl_mem_image, mappedBuffer, 0, NULL, NULL);
ほかのプラットフォームでの注意事項
すべてのプラットフォームにおいて、ここで説明した動作と同じになるとは限りません。各ベンダーのドキュメントを確認してください。OpenCL* API 仕様は、ゼロコピー・バッファーの作成を可能にします。しかし、常にゼロコピー・バッファーを返すことを保証するわけではありません。実際、仕様にはコピーが作成される可能性があることが明記されています。CL_MEM_USE_HOST_PTR に関するドキュメントからの抜粋を以下に示します。
「OpenCL* 実装では、デバイスメモリーで host_ptr によりポイントされたバッファー・コンテンツのキャッシュが許可されています。キャッシュされたコピーは、デバイスでカーネルを実行する際に使用できます。」
仮想アドレス空間に関する考察
4096 バイト・ページ境界でアライメントされているかチェックするアドレスは、仮想アドレスであって、物理アドレスではないことにお気付きかもしれません。これは問題でしょうか? 理論的には問題になる可能性がありますが、OS は仮想アドレスを物理アドレスに変換できるため、ここで説明した実装では問題になりません。仮想アドレスがページ境界でアライメントされていれば、物理アドレスもページ境界でアライメントされます。これについては、ここでは本題から外れるため詳しく取り上げません。
ゼロコピー動作を確認する
OpenCL* 1.2 API には 1 つ欠点があります。コピーが行われたかどうかを確認するランタイムの仕組みがないことです。例えば、clEnqueueMapBuffer() を実行した場合、コピーが行われたかどうか分かりません。サンプルでは、1024×1024 イメージを使用する簡単なプログラムで、出力バッファーを _aligned_malloc() で宣言した場合と malloc() で宣言した場合の割り当て直前から割り当て解除直後までの実行時間を比較しました。それぞれ複数回実行した結果、アライメントされた割り当てのほうが大幅に高速であることが確認できました。測定時間にはドライバーのオーバーヘッドも含まれています。サンプルコードに時間を測定するためのコードがあるので、実際に試してみてください。
ゼロコピー・サンプルコード
https://code.google.com/p/aobench/ (英語) から入手可能な、良く知られている BSD ライセンス・コードベースのアンビエント・オクルージョン・ベンチマーク (AOBench) を OpenCL*に移植しています。まず、プログラマーが最初に試すであろう方法で OpenCL* に移植しました。次に、計算したアンビエント・オクルージョンのイメージをゼロコピー・バッファーとして作成する 2 つのバージョンを用意しました。1 つはバッファーを割り当て、OpenCL* へ渡します。これは、CL_MEM_USE_HOST_PTR を利用する既存のアプリケーションで一般的な手法と言えるでしょう。もう 1 つは、より簡単で、CL_MEM_ALLOC_HOST_PTR を利用して OpenCL* ランタイムにバッファーの割り当てを任せます。ほかの実装も可能なので、皆さん試してみてください。CL_MEM_ALLOC_HOST_PTR でバッファーを作成し、ポインターを割り当て、ホストでバッファーにデータを生成して、ポインターの割り当てを解除します。これは、単純ですが良い練習になるでしょう。ここでは、出力イメージバッファーに注目していますが、ほかのバッファーも同様に処理することができます。
サンプルファイルとディレクトリー構造
サンプルコードについて説明しましょう。ここでは、製品品質の実装ではなく、単純な C サンプルを作成することを目的としています。コードの多くは、すべてのサンプルに共通です。
ソースファイル:
- Common/host_common.cpp: プログラムを開始し、OpenCL* コンテキストの管理、ソースのコンパイル、キューの作成、一般的なクリーンアップ処理を行います。
- Common/kernels.cl: このサンプル用の OpenCL* カーネルコード。アプリケーションの実行に必要なファイルが含まれています。
- Include/host_common.h : さまざまな初期値、関数と変数宣言を含む host_common.cpp 用のヘッダーファイル。
- Include/scene.h: サンプルで使用されるシーングラフ関数と変数。
- NotZeroCopy/main.c: サンプルコードから移植した関数を含むソースファイル。このファイルで重要な関数は、initializeDeviceData() と runClKernels() です。ゼロコピーをサポートしないように、initializeDeviceData() でアライメントを強制しない標準の malloc() を使用しています。runCLKernels() では、標準の API 呼び出し clEnqueueReadBuffer() を使用しています。このバージョンは、機能的には全く問題ありませんが、パフォーマンスが最適ではありません。
- ZeroCopyUseHostPtr/main.c: NotZeroCopy の関数を変更したソースファイル。NotZeroCopy の initializeDeviceData() で malloc() だった個所を _aligned_malloc() に変更しています。また、clCreateBuffer() の呼び出し時に CL_MEM_USE_HOST_PTR を指定しています。
- ZeroCopyAllocHostPtr/main.c: ランタイムの割り当てメカニズムを使用するのに必要な変更を含むソースファイル。ここでは、ZeroCopyUseHostPtr のように _aligned_malloc() を呼び出す必要がありません。代わりに、CL_MEM_ALLOC_HOST_PTR と割り当てるバッファーのサイズを渡しています。
その他のファイルとディレクトリーは、Microsoft* Visual Studio* IDE により自動生成されます。
Microsoft* Visual Studio* 2012 の設定:
Microsoft* Visual Studio* 2012 ソリューション OpenCLZeroCopy.sln には、次の 3 つのプロジェクトが含まれています: NotZeroCopy.vcxproj、ZeroCopyAllocHostPtr.vcxproj、
ZeroCopyUsedHostPtr.vcxproj。OpenCLZeroCopy.props プロパティー・シートには、cl.h ヘッダーファイルへのシステムパス、リンクする OpenCL.lib ライブラリーへのポインター、ローカルのインクルード・ディレクトリーへのポインターなど、このプロジェクト固有の設定があります。ビルド環境に応じて、これらの設定を変更する必要があるかもしれません。
サンプルをビルドおよび実行する
ビルド要件
最初に、https://software.intel.com/en-us/vcsource/tools/opencl-sdk (英語) からインテル® SDK for OpenCL* Applications をダウンロードし、インストールします。また、Microsoft* Visual Studio* 2012 (MSVC 2012) IDE がインストールされていることを確認します。次に、MSVC 2012 で OpenCLZeroCopy.sln を開きます。
プロパティー・シートのパス
各実行ファイルのビルドごとにプロパティー設定を変更する代わりに、MSVC ではプロパティー・シートをサポートしています。プロパティー・シートを変更すると、ビルド設定でそのプロパティー・シートが指定されたすべてのビルドに変更が適用されます。参考までに、以下にいくつかのスクリーンショットを示します。スクリーンショットではテストマシンのパスが使用されているので、必要に応じて変更してください。パスの代わりに環境変数 $(INTELOCLSDKROOT) を使用することもできます。この場合、C:\Program Files (x86)\Intel\OpenCL SDK\3.0\ が使用されます。3.0 はバージョン番号なので、インストールされているバージョンに応じて異なります。このサンプルコードでは、すべての実行ファイルで使用されるインクルード・ファイルの相対パスとインテル® SDK for OpenCL* Applications のデフォルトのインストール・パスを指定します。プロパティー・シートの詳細は、MSDN ドキュメント (http://msdn.microsoft.com/ja-jp/library/z1f703z5(v=vs.90).aspx) を参照してください。
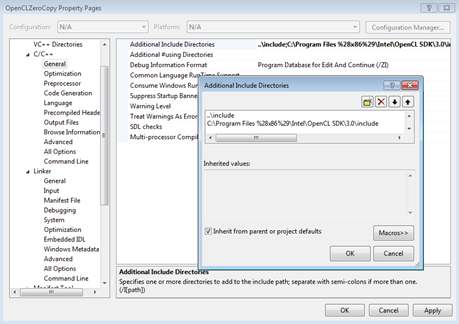
図 2. このサンプルコードで使用する追加のインクルード・ディレクトリー
プロパティー・マネージャーは、[表示]< > [プロパティー マネージャー] メニューを選択すると表示されます。
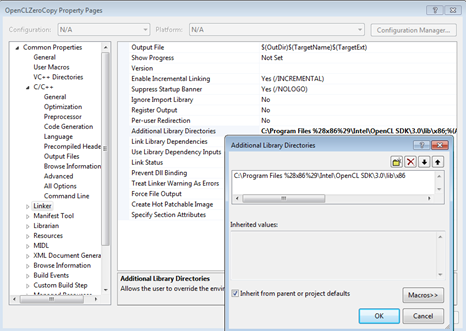
図 3. このサンプルコードで使用する追加のライブラリー・ディレクトリー
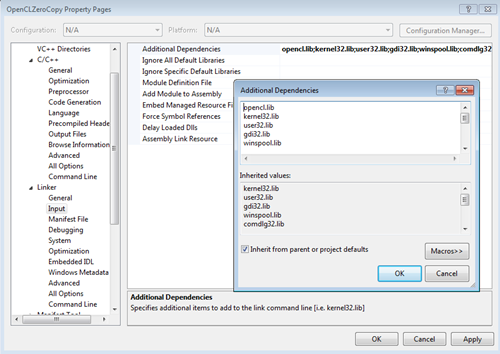
図 4. 追加のライブラリーとして opencl.lib ファイルを指定
サンプルの実行
メインメニューから [ビルド] > [ソリューションのビルド] を選択してサンプルコードをビルドすると、すべての実行ファイルが生成されます。実行ファイルは、Visual Studio* ディレクトリーから実行することも、OpenCLZeroCopy ソリューション・ファイルと同じ場所にある Debug/Release ディレクトリーから実行することもできます。
今後予定されている OpenCL* 2.0 機能: 共有仮想メモリー (SVM)
この記事では、インテル® プロセッサーとインテル® プロセッサー・グラフィックスのように、共有物理メモリー (SPM) をサポートするプラットフォームでの共有可能なバッファーの使用法について紹介しました。OpenCL* 2.0 では、共有仮想メモリーをサポートするアーキテクチャーで仮想メモリーの共有を可能にする API が追加される予定です。これにより、書き込み用の共有バッファーだけでなく、CPU と GPU 間で仮想アドレスも共有できるようになります。例えば、SVM を利用して CPU で物理シミュレーションによりシーングラフを更新し、GPU で最終イメージを計算することが可能です。
謝辞
この記事と関連資料を準備する過程で、多くの方々にアドバイスをいただいたり、助けていただきました。Stephen Junkins、Murali Sundaresan、David Blythe、Aaron Kunze、Allen Hux、Mike Macpherson、Pavan Lanka、Girish Ravunnikutty、Ben Ashbaugh、Sergey Lyalin、Maxim Shevstov、Arnon Peleg、Vadim Kartoshkin、Deepti Joshi、Uri Levy、Shiri Manor に感謝します。
参考文献 (英語)
- OpenCL* 1.2 仕様: https://www.khronos.org/registry/cl/specs/opencl-1.2.pdf
- OpenCL* 2.0 仕様 (OpenCL* C Language Specification、OpenCL* Runtime API Specification、OpenCL* Extensions Specification の 3 つで構成される): https://www.khronos.org/registry/cl/specs/
- AOBench: https://code.google.com/p/aobench/
- Stephen Junkins のホワイトペーパー「The Compute Architecture of Intel® Processor Graphics Gen7.5」: https://software.intel.com/sites/default/files/managed/f3/13/Compute_Architecture_of_Intel_Processor_Graphics_Gen7dot5_Aug2014.pdf。インテル® プロセッサー・グラフィックスで OpenCL* を使用する場合は必読。
著者紹介
Adam Lake – 標準化団体 Khronos* Group のビジュアル・プロダクト・グループのシニア・グラフィックス・アーキテクトで、議決権保有メンバーです。12 年以上の GPGPU プログラミング経験があり、これまで VR、3D、グラフィックス、ストリーム・プログラミング言語コンパイラーに関わってきました。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
OpenCL および OpenCL ロゴは、Apple Inc. の商標であり、Khronos の使用許諾を受けて使用しています。
© 2014 Intel Corporation. 無断での引用、転載を禁じます。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。
