

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「Benefitting Power and Performance Sleep Loops」(http://software.intel.com/en-us/articles/benefitting-power-and-performance-sleep-loops/) の日本語参考訳です。
問題の概要
最新のマルチコア・プロセッサーを最大限に活用するため、開発者は扱いやすいサイズに作業を分割し、スレッドプールを利用して同時に実行する複数のスレッドに分配する手法が一般的になりました。スレッドプールのパフォーマンスと消費電力の問題は、通常、複数のスレッドが作業を要求して作業キューで高い競合が発生している場合か、複数のスレッドがキューで作業を待機している場合に発生します。この問題を解決するアルゴリズムは色々ありますが、ここでは最もよく使用され、実装全体を設計し直すことなく、簡単な変更でパフォーマンスと消費電力を向上できるアルゴリズムについて説明します。
この問題を解決するためによく使用される方法は、スレッドプール内の各スレッドが、キューにある作業を常に確認し、作業が発生したらすぐに処理を開始することです。これは非常に単純な方法ですが、開発者は多くの場合、キューで作業をポーリングする方法やキューで高い競合が発生した場合の対処方法で問題に直面します。次の 2 つの状況で問題が発生します。
- 作業キューに十分な作業がなく、ワーカースレッドが作業を待機している場合。
- 同時にキューから作業を取得しようとしているスレッドが多数あり、キューを保護するロックで競合状態が発生し、それを緩和するためにスレッドがロックの取得を諦めなければならない場合。
この記事は、よく使用されるスレッドプールの実装の落とし穴と、簡単な変更で消費電力とパフォーマンスが大幅に向上する方法を説明します。
ここでは分かりやすくするため、ワークロードとして、均等かつ独立して分割可能な大きなデータセットを想定します。
スリープループのアルゴリズムの詳細
ここで使用する例では、各スレッドが作業キューにアクセスしようとするため、決められた数のスレッドだけが同時に作業を取得できるように、ロックを使用してキューへのアクセスを保護する必要があります。
これらを考慮したシングルスレッドのアルゴリズムのフローは次のようになります。
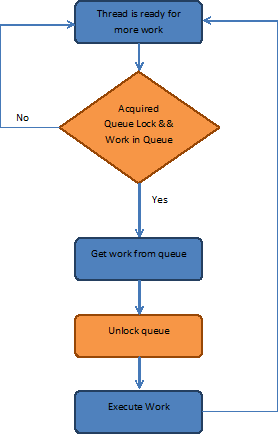
Windows* プラットフォームにおけるこのアルゴリズムの問題点
スレッドプールがどこで動作しなくなるのかは、実装方法にかかっていますが、ここで重要なのは、キューに作業がない場合、またはスレッドがキューに対するロックの取得に失敗した場合にどのように対処するかです。最も簡単な対処方法は、常に確認することで、これは「ビジー・ウェイト」ループと呼ばれます。以下に擬似コードを示します。
while (!acquire_lock() && work_in_queue); get_work(); release_lock(); do_work();
表 1: 「ビジー・ウェイト」ループ
この実装の問題は、スレッドがロックを取得できない場合やキューに作業がない場合に、スレッドがすぐに確認を続行することです。頻繁なポーリングは、利用可能なすべてのプロセッサー・リソースを消費し、パフォーマンスと消費電力の両方に影響を与えます。ただし優れた面もあり、ロックや作業が利用可能になると、スレッドはすぐにキューに入ることができます。
キューや高い競合状態にあるロックの確認を止めるには、Win32 API の Sleep(0) を呼び出します。MSDN のドキュメントでは、Sleep(0) を呼び出すことで、呼び出し側のスレッドより高い優先度を持つスレッドが実行可能な場合のみ、呼び出し側のスレッドは残りのタイムスライスを放棄するとしています。つまり、スレッドは常に確認する代わりに、ほかに有効な作業が保留になっていない場合のみ確認します。より積極的な方法が必要な場合、常に残りのタイムスライスを放棄する Sleep(1) を呼び出し、スイッチアウトします。Sleep(1) を使用すると、スレッドは 1 ミリ秒後にウェイクアップし、確認を再開します。
while (!acquire_lock() || no_work_in_queue)
{
Sleep(0);
}
get_work();
release_lock();
do_work();
表 2: スリープループ
このほかにも、OS 内部ではパフォーマンスを大幅に低下させる可能性があるさまざまなことが起こっています。Sleep(0) の呼び出しは、命令パスがかなり長く、約 1,000 サイクルも消費する ring3 から ring 0 への遷移があるため、オーバーヘッドがかかります。プロセッサーは、この “スリープループ” が有効な作業を行っていると思い込んでいます。これらの命令を実行することで、プロセッサーは最大限に活用され、パイプラインに命令を送り、それらを実行し、キャッシュを廃棄します。ここで注意すべきことは、プログラムの役に立たないことに電力が消費されている点です。
さらに、Sleep(1) の呼び出しは、Windows* カーネルのクロックティックがデフォルトの 15.6 ミリ秒の場合、恐らく開発者の意図したとおりに動作しません。デフォルトのクロックティックでは、この呼び出しは 1 ミリ秒よりもはるかに長いスリープと同じで、カーネルがウェイクするまでスレッドはウェイクしないため、15.6 ミリ秒も待機することになります。つまり、このような呼び出しでは、ロックが利用可能になったり、作業がキューに追加されても、スレッドはすぐにアクティブになりません。
また別の問題として、ただちに残りのタイムスライスを放棄することで、実行スレッドがスイッチアウトされます。コンテキスト・スイッチには、約 5,000 サイクルかかるため、スイッチアウトし、スイッチバックすることで少なくとも 10,000 サイクルのオーバーヘッドが発生し、その分ワークロードの完了が遅れます。ほとんどの場合、これらのループは頻繁にコンテキスト・スイッチを発生させます。これは、オーバーヘッドが存在し、パフォーマンス向上の可能性があることを示します。
幸いなことに、このオーバーヘッドを排除し、消費電力を抑え、パフォーマンスを向上できる代替手段があります。
解決方法
ここで推奨する代替手段は、より段階的なバックオフともいえるアルゴリズムです。最初、スレッドに短時間ロックをスピンさせますが、完全にスピンする代わりに、ループに pause 命令を追加します。インテル® SSE2 命令セットで追加された pause 命令は、プロセッサーに呼び出し側のスレッドが “スピン-ウェイト” ループ内にあることを知らせます。
この pause 命令は、SSE2 に対応していない x86 アーキテクチャーでは no-op となり、何の処理も行わない命令が実行されるか、フォルトが発生します。つまり、SSE2 に対応していない古い x86 アーキテクチャーでは、pause 命令を利用できませんが、開発者は全体で 1 つの単純なコードパスを維持することができます。
基本的に、この命令は次の命令の実行を一定時間遅らせます。次の命令の実行を遅らせることで、プロセッサーに要求が送られず、パイプラインの一部は未使用になるため、プロセッサーの消費電力を削減できます。短時間でロックや作業が利用可能になる状況で、pause と Sleep(0) を混在して使用すると指数バックオフのようになり、ring3 のスピンが短くなることでパフォーマンスの向上が見込めます。以下にこのアルゴリズムを示します。
ATTEMPT_AGAIN:
if (!acquire_lock())
{
/* スリープに入る前に pause を max_spin_count 回スピンする */
for(int j = 0; j < max_spin_count; ++j)
{
/* pause 組込み命令 */
_mm_pause();
if (read_volatile_lock())
{
if (acquire_lock())
{
goto PROTECTED_CODE;
}
}
}
/* ループの pause に失敗、スリープに入る */
Sleep(0);
goto ATTEMPT_AGAIN;
}
PROTECTED_CODE:
get_work();
release_lock();
do_work();
表 3: 急激な脱出メカニズムを持つスリープループ
実際のプログラムでの pause の使用
pause 命令を含む表 3 のアルゴリズムを使用することで、消費電力とパフォーマンスの両方が大幅に向上します。テストでは、3 つのワークロードを使用し、それぞれに時間のかかるアクティブな作業を行いました。粒度が粗いと、作業は比較的広範囲にわたり、スレッドがロックの競合を起こすことはほとんどありません。粒度が細かいと、作業は短く、スレッドはより多くのタスクを終了し、次のタスクに利用可能になります。
以下の測定結果は、6 コア、12 スレッドのインテル® Core™ i7 990X と同等のシステムで測定されました。パフォーマンスの向上は驚くべきものでした。Sleep(0) を使うだけで、8 スレッドでは最大 4 倍、32 スレッドでも約 3 倍もパフォーマンスが向上しました。

表 4: pause を使用した場合のパフォーマンス

表 5: pause を使用した場合のパフォーマンス
前述のとおり、pause 命令を使用することで、スレッドが待機中のプロセッサー・パイプラインの使用を抑え、消費電力を削減することができます。計測器を使って 2 つのアルゴリズムの消費電力の違いを測定してみました。
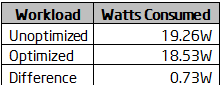
表 6: 最適化あり/なしの場合の消費電力
標準の実装よりも 0.73W ほど省電力であることが分かります。つまり、このようなプログラムはラップトップのバッテリー消耗の原因にはなりにくいでしょう。積極的な省電力対策とパフォーマンスの向上は、ワークロード全体の消費電力を大幅に削減します。
まとめ
ここで紹介したアルゴリズムのように、多くのケースでは、開発者が見落としたり、単に気付かない多数のパフォーマンスに関する問題が隠れています。我々は、数年にわたって調査と測定を行うことで、これらの問題に対処することができました。
皆さんが、ここで紹介したソリューションを既存のソフトウェアへ簡単に組込めるように願っています。このソリューションでは一般的なアルゴリズムを使用し、大きな影響を与える変更を少し加えたものです。携帯機器が広く普及し、バッテリーの寿命がより重要になりつつある中、開発者はさまざまな点を考慮することで、新しい命令を活用し、パフォーマンスと消費電力の両方を向上させることができます。
著者紹介
 Joe Olivas は、インテルのソフトウェア・エンジニアで、他のソフトウェア・ベンダー向けにソフトウェア・パフォーマンスの最適化を行い、また新しい解析ツールの開発にも取り組んでいます。カリフォルニア州立大学サクラメント校でコンピューター・サイエンスの学士号と修士号を取得しています (専門は、暗号プリミティブとパフォーマンス)。ソフトウェアの最適化に取り組んでいないときは、自宅のリフォームをしたり、夫人と一緒に自家製ビールを醸造しています。
Joe Olivas は、インテルのソフトウェア・エンジニアで、他のソフトウェア・ベンダー向けにソフトウェア・パフォーマンスの最適化を行い、また新しい解析ツールの開発にも取り組んでいます。カリフォルニア州立大学サクラメント校でコンピューター・サイエンスの学士号と修士号を取得しています (専門は、暗号プリミティブとパフォーマンス)。ソフトウェアの最適化に取り組んでいないときは、自宅のリフォームをしたり、夫人と一緒に自家製ビールを醸造しています。
 Mike Chynoweth は、インテルのソフトウェア・エンジニアで、ソフトウェア・パフォーマンスの最適化と解析に取り組んでいます。フロリダ大学で化学工学の学士号を取得しています。新しいパフォーマンス解析手法に取り組んでいないときは、ディジュリドゥの演奏、サイクリング、ハイキングなどを楽しんだり、家族と時間を過ごしています。
Mike Chynoweth は、インテルのソフトウェア・エンジニアで、ソフトウェア・パフォーマンスの最適化と解析に取り組んでいます。フロリダ大学で化学工学の学士号を取得しています。新しいパフォーマンス解析手法に取り組んでいないときは、ディジュリドゥの演奏、サイクリング、ハイキングなどを楽しんだり、家族と時間を過ごしています。
コンパイラーの最適化に関する詳細は、最適化に関する注意事項を参照してください。

コメント
[…] ※pause 命令についてはIntelさんによるこちらの記事を参照してください。 […]