

この記事は、インテル® ソフトウェア・ネットワークに掲載されている「IIR Gaussian Blur Filter Implementation using Intel® Advanced Vector Extensions」(http://software.intel.com/en-us/articles/iir-gaussian-blur-filter-implementation-using-intel-advanced-vector-extensions/) の日本語参考訳です。
ソースのダウンロード: https://software.intel.com/sites/default/files/m/4/3/7/a/a/gaussian_blur_0311.cpp
gaussian_blur.cpp [36KB]
はじめに
この記事では、インテル® アドバンスド・ベクトル・エクステンション (インテル® AVX) の命令を使用した IIR (Infinite Impulse Response、無限インパルス応答) ガウスぼかしフィルター [1] [2] [3] の実装について説明します。
IIR ガウスフィルター
ガウスフィルターは、ノイズ・リダクション、ぼかし、エッジ検出などのイメージ処理で幅広く利用されているローパスフィルターで、イメージの高周波数ノイズを減衰させます。1 次元のガウス関数は次のように定義されます。
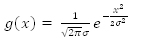
ここで、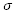 はガウス分布の標準偏差です。
はガウス分布の標準偏差です。
ガウス関数のフーリエ変換もガウス関数です。
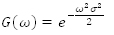

2 次元のガウス関数は次のように定義されます。
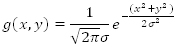
ガウスフィルターは非常に計算負荷が高く、出力ピクセルあたりの演算数は に比例して増加します。ただし、IIR ガウスフィルターとその派生 [1][2][3] は と独立した差分方程式を再帰的に解くため、出力ピクセルあたりの演算数は固定で、 の影響を受けません。この記事では、次の方程式を使用しました。
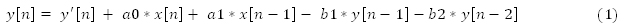

IIR ガウスフィルターは、各ピクセルを横方向および縦方向に処理します。このフィルターは分離可能です。つまり、任意の順序で (横方向を最初に、または縦方向を最初に) フィルターを適用できます。

インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX)
インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) は、インテル® ストリーミング SIMD 拡張命令 (インテル® SSE) の機能を拡張し、新しい豊富な機能のセットによって劇的にソフトウェア・アプリケーションのパフォーマンスを向上させます。インテル® AVX は、次のような機能をサポートしています。
- 256 ビット幅の SIMD レジスター。インテル® SSE (4 つの単精度浮動小数点または 2 つの倍精度浮動小数点要素を並列で処理可能) の倍にあたる、8 つの単精度浮動小数点または 4 つの倍精度浮動小数点要素を並列で処理できます。この結果、電力効率が改善され、演算パフォーマンスが向上します。
- 256 ビット幅のインテル® AVX ロード命令。256 ビットのデータをロードおよび処理できます。
- 3 オペランドおよび 4 オペランドの命令構文をサポートする、効率的な命令エンコーディング・スキーム。従来の 128 ビット SIMD 命令も、新しい命令エンコーディングをサポートするように拡張されています。
- 3 オペランドおよび 4 オペランドの命令構文を含む、効率的でコンパクトな優れたコード生成。
- データの管理と再配置用のさまざまな新しい命令 (broadcast や permute など)。
インテル® AVX は、イメージ処理、ビデオ処理、オーディオ処理、科学アプリケーション、金融アプリケーションなどの、浮動小数点演算が多い処理に最適です。
IIR ガウスぼかしフィルターは計算負荷の高いフィルターです。このフィルターの浮動小数点実装では高品質のぼかされたイメージを生成します。最高の品質とパフォーマンスが得られるようにフィルターを実装するには、インテル® AVX が最適な選択肢です。
インテル® AVX 命令を使用した IIR ガウスぼかしフィルターの実装
IIR ガウスぼかしフィルターは、2 つの連続するパスで各ピクセルに方程式 (1) を適用します。
- 横方向のパス: このパスは、入力イメージを左から右 (行方向) に処理した後、右から左に処理します。左から右のパスの出力を右から左のパスに追加します。
- 縦方向のパス: 通常、縦方向のパスは、横方向のパスの出力を上から下 (列方向) に処理した後、下から上に処理します。入力を列方向にアクセスすると、大量のキャッシュブロックが必要になり、フィルターのパフォーマンスに影響を与えます。この問題を回避するため、横方向のパスは、出力バッファーに書き込む前に出力を転置します。この結果、縦方向のパスは横方向のパスと似たものになり、中間出力を左から右に処理した後、右から左に処理します。縦方向のパスは、ぼかされたイメージを書き込む前に最終的な出力を再度転置します。
この記事で説明する実装では、入力が 24 ビット RGB パックドである (各カラーチャンネルが 8 ビットの整数で表現されている) と仮定しています。また、単純に説明するため、フィルターの入力イメージを対称 (高さ == 幅。たとえば、1024×1024) にしています。
フィルターは複数の行を同時に処理し、入力イメージが対称であるため、バンク競合が発生する可能性が高くなります。バンク競合を回避するため、フィルターは各行に 2 つの余分なキャッシュラインを追加します。ただし、フィルターはこれらの余分なキャッシュラインを処理しないで、オリジナルのイメージ幅で処理を行います。
各パスで丸め誤差が発生して、生成されるイメージ品質が劣化するのを防ぐため、フィルターは縦方向のパスと横方向のパスの中間出力を (24 ビットの RGB ピクセル形式に) パック/アンパックしません。これらの中間出力のパック/アンパックを行わないことで、高品質のぼかされたイメージを生成できます。
フィルターは、入力イメージに 8 ビットのアルファチャンネルを追加して、各ピクセルを 32 ビット・パックド (RGBA ピクセル形式) にします。4 つの (32 ビット) ピクセル・コンポーネント (RGBA) を AVX レジスターにアラインするほうが、データをより簡単に処理できるためです。この処理を行わない場合、入力データを再度アラインする余分な命令 (シャッフル) が必要になります。
フィルターは、インテル® C/C++ コンパイラーの組み込み関数を使用して記述されています。
横方向のパス
よりワイドなインテル® AVX 命令を使用すると、4 つの入力要素を並列で処理できます。フィルターは、2 つの 256 ビット幅のレジスターの 4 つの隣接する行から 4 つの入力パックドピクセルをアンパックします。
最初の入力ピクセルを、vpmovzxbd 命令を使用して、YMM レジスターの下位 128 ビットに挿入します。2 つ目の入力ピクセルを、vinsertf128 命令を使用して、YMM レジスターの上位 128 ビットに挿入します。
インテル® AVX で導入された新しい vbroadcastss 命令は、メモリーから YMM レジスターの 8 つの単精度の場所に単精度要素をブロードキャストします。IIR ガウスぼかしフィルターは、vbroadcastss 命令を使用して IIR ガウス係数を YMM レジスターにロードしています。
インテル® AVX の 256 ビット加算命令と乗算命令を使用すると、8 つの単精度浮動小数点値 (2 つのアンパックピクセル) を並列で加算および乗算することができます。
インテル® AVX 命令を使用して 4 つの入力ピクセルを並列で処理し、出力の 64 バイト (1 キャッシュライン) を生成することで、キャッシュ・エビクション (追い出し) やキャッシュブロックを最小限に抑えることができます。横方向の左から右のパスの出力は、フル・イメージ・バッファーではなく小さな一時バッファーにアンパック (float) で格納されるため (幅*ピクセル/ループ*チャンネル*float サイズ: ピクセル/ループ = 4、チャンネル =4)、右から左のパスで使用されるときに、(イメージのサイズによって) この一時バッファーが CPU キャッシュに置かれる可能性があります。出力データの一時バッファーへの書き込みには、インテル® AVX の 256 ビット・ストア命令を使用しています。
横方向のパスは、入力イメージに追加された余分なキャッシュラインを処理しないで、 実際のイメージ幅で処理を行います。
// width - 実際の入力イメージの幅
// Nwidth - 調整後の入力イメージの幅
// id - 入力イメージの符号なし int ポインター
// oTemp - 左から右のパスと右から左のパス間の小さな一時出力バッファー
for (int y = 0; y < width; y++) {
// 隣接する行から 2 つの入力ピクセルをロード
currIn = _mm256_castsi256_ps(_mm256_castsi128_si256(_mm_cvtepu8_epi32(*(__m128i *) (id))));
currIn = _mm256_insertf128_ps(currIn, _mm_castsi128_ps(_mm_cvtepu8_epi32((*(__m128i *)(id+Nwidth)))), 0x1);
currIn = _mm256_cvtepi32_ps(_mm256_castps_si256(currIn));
// 次の 隣接する行からさらに 2 つの入力ピクセルをロード
currInN =_mm256_castsi256_ps(_mm256_castsi128_si256(_mm_cvtepu8_epi32(*(__m128i *) (id+2*Nwidth))));
currInN = _mm256_insertf128_ps(currInN, _mm_castsi128_ps(_mm_cvtepu8_epi32((*(__m128i *)(id+3*Nwidth)))), 0x1);
currInN = _mm256_cvtepi32_ps(_mm256_castps_si256(currInN));
currComp = _mm256_mul_ps(currIn, _mm256_broadcast_ss((float *)a0));
currCompN = _mm256_mul_ps(currInN, _mm256_broadcast_ss((float *)a0));
temp1 = _mm256_mul_ps(prevIn, _mm256_broadcast_ss((float *)a1));
temp1N = _mm256_mul_ps(prevInN, _mm256_broadcast_ss((float *)a1));
temp2 = _mm256_mul_ps(prevOut, _mm256_broadcast_ss((float *)b1));
temp2N = _mm256_mul_ps(prevOutN, _mm256_broadcast_ss((float *)b1));
temp3 = _mm256_mul_ps(prev2Out, _mm256_broadcast_ss((float *)b2));
temp3N = _mm256_mul_ps(prev2OutN, _mm256_broadcast_ss((float *)b2));
currComp = _mm256_add_ps(currComp, temp1);
currCompN = _mm256_add_ps(currCompN, temp1N);
temp2 = _mm256_add_ps(temp2, temp3);
temp2N = _mm256_add_ps(temp2N, temp3N);
prev2Out = prevOut;
prevOut= _mm256_sub_ps(currComp, temp2);
prev2OutN = prevOutN;
prevOutN= _mm256_sub_ps(currCompN, temp2N);
prevIn = currIn;
prevInN = currInN;
//出力データを格納
_mm256_store_ps((float *)(oTemp), prevOut);
_mm256_store_ps((float *)(oTemp+8), prevOutN);
id += 1 ; oTemp += 16; // 次の要素に移動
}
表 1: 横方向の左から右のパスループ
横方向の右から左のパスは左から右のパスに似ていて、イメージを右から左に処理します。インテル® AVX 命令を使用して、隣接する行から 4 つの入力ピクセルをアンパックします。インテル® AVX の 256 ビット・ロード命令を使用して、以前のパスからの出力をロードします。このパスの出力を左から右のパスの出力に追加します。
最終的な出力 (縦方向のパスの入力) をフル・イメージ・バッファーに格納します。出力は転置された形式で (出力イメージの品質を保つためにパックしないで) 書き込まれます。この出力は横方向のパスでこれ以上使用されないため、インテル® AVX の 256 ビット vmovntps 命令を使用して、出力データをキャッシュしないでメモリーに格納します。

// width - 実際の入力イメージの幅
// Nwidth - 調整後の入力イメージの幅
// id - 入力イメージの符号なし int ポインター
// od - 出力バッファーの float ポインター - 縦方向のパスの入力
// oTemp - 左から右のパスと右から左のパス間の小さな一時出力バッファー
for (int y = width-1; y >= 0; y--) {
// 入力をロード
inNext = _mm256_castsi256_ps(_mm256_castsi128_si256(_mm_cvtepu8_epi32(*(__m128i *) (id))));
inNext = _mm256_insertf128_ps(inNext, _mm_castsi128_ps(_mm_cvtepu8_epi32((*(__m128i *)(id+Nwidth)))), 0x1);
inNext = _mm256_cvtepi32_ps(_mm256_castps_si256(inNext));
inNextN = _mm256_castsi256_ps(_mm256_castsi128_si256(_mm_cvtepu8_epi32(*(__m128i *) (id+2*Nwidth))));
inNextN = _mm256_insertf128_ps(inNextN, _mm_castsi128_ps(_mm_cvtepu8_epi32((*(__m128i *)(id+3*Nwidth)))), 0x01);
inNextN = _mm256_cvtepi32_ps(_mm256_castps_si256(inNextN));
//一時バッファーから現在の出力を取得
output = _mm256_load_ps((float *) (oTemp));
outputN = _mm256_load_ps((float *) (oTemp+8));
currComp = _mm256_mul_ps(currIn, _mm256_broadcast_ss((float *)a2));
temp1 = _mm256_mul_ps(prevIn, _mm256_broadcast_ss((float *)a3));
temp2 = _mm256_mul_ps(prevOut, _mm256_broadcast_ss((float *)b1));
temp3 = _mm256_mul_ps(prev2Out, _mm256_broadcast_ss((float *)b2));
currComp = _mm256_add_ps(currComp, temp1);
temp2 = _mm256_add_ps(temp2, temp3);
prev2Out = prevOut;
prevOut= _mm256_sub_ps(currComp, temp2);
prevIn = currIn;
currIn = inNext;
// 前のパス出力を追加
output = _mm256_add_ps(output, prevOut);
//次のセット
currComp = _mm256_mul_ps(currInN, _mm256_broadcast_ss((float *)a2));
temp1 = _mm256_mul_ps(prevInN, _mm256_broadcast_ss((float *)a3));
temp2 = _mm256_mul_ps(prevOutN, _mm256_broadcast_ss((float *)b1));
temp3 = _mm256_mul_ps(prev2OutN, _mm256_broadcast_ss((float *)b2));
currComp = _mm256_add_ps(currComp, temp1);
temp2 = _mm256_add_ps(temp2, temp3);
prev2OutN = prevOutN;
prevOutN = _mm256_sub_ps(currComp, temp2);
prevInN = currInN;
currInN = inNextN;
// 前のパス出力を追加
outputN = _mm256_add_ps(outputN, prevOutN);
_mm256_stream_ps((float *)(od), output);
_mm256_stream_ps((float *)(od+8), outputN);
id -= 1; od -= 4*height;
oTemp -=16;
}
表 2: 横方向の右から左のパスループ
縦方向のパス
縦方向のパスはイメージを縦に処理するため、より多くのメモリーとキャッシュの問題に取り組む必要があります。ただし、IIR ガウスぼかしフィルターは、横方向のパスの出力 (縦方向のパスの入力) を転置することで、これらの問題を最小限に抑えています。この結果、縦方向のパスは横方向のパスと同じになり、転置された入力を左から右に処理した後、右から左に処理します。
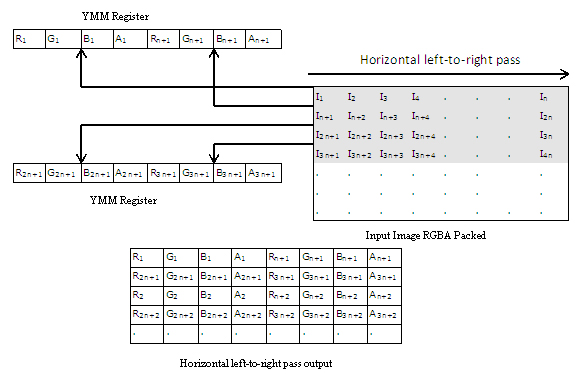
縦方向の左から右のパスは、インテル® AVX 命令を使用して、連続する行から 4 つのアンパックされた入力ピクセルを処理します。インテル® AVX の 128 ビット・ロード命令を使用して、最初のピクセルを YMM レジスターの下位半分に挿入します。vinsertf128 命令を使用して、次の行からの 2 つ目のピクセルを YMM レジスターの上位半分に挿入します。
vbroadcastss 命令を使用して、メモリーから IIR ガウスぼかし係数をロードします。新しいインテル® AVX の加算命令と乗算命令を使用して、出力の 4 つのアンパックピクセル (16 SP 要素) を生成します。
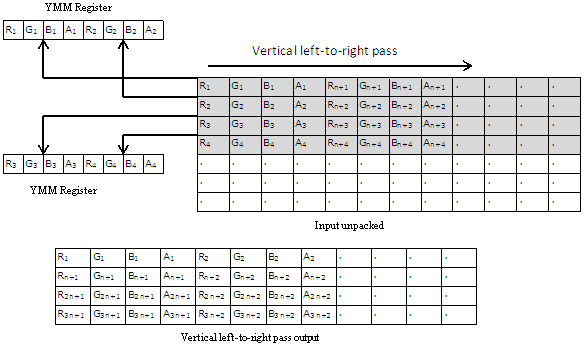
図 5: 縦方向の左から右のパス
インテル® AVX の 256 ビット・ストア命令を使用して、縦方向の左から右のパスの出力を小さな一時バッファーに格納します。出力を再度転置します (イメージ形式)。このパスは出力をイメージ形式でロード、処理、格納するため、縦方向の右から左のパスの処理が簡単になります。
// height -入力イメージの幅
// id - 入力の float ポインター (横方向のパスの出力)
// oTemp - 左から右のパスと右から左のパス間の小さな一時出力バッファー
for (int y = 0; y < height; y++) {
// 2 つの入力ピクセルをロード
currIn = _mm256_castps128_ps256(_mm_loadu_ps((float *) id));
currIn = _mm256_insertf128_ps(currIn, _mm_loadu_ps((float *)(id+4*height)), 0x1);
// さらに 2 つの入力ピクセルをロード
currInN = _mm256_castps128_ps256(_mm_loadu_ps((float *) (id+8*height)));
currInN = _mm256_insertf128_ps(currInN, _mm_loadu_ps((float *)(id+12*height)), 0x1);
//最初の 2 つのピクセルを処理
currComp = _mm256_mul_ps(currIn, _mm256_broadcast_ss((float *)a0));
temp1 = _mm256_mul_ps(prevIn, _mm256_broadcast_ss((float *)a1));
temp2 = _mm256_mul_ps(prevOut, _mm256_broadcast_ss((float *)b1));
temp3 = _mm256_mul_ps(prev2Out, _mm256_broadcast_ss((float *)b2));
currComp = _mm256_add_ps(currComp, temp1);
temp2 = _mm256_add_ps(temp2, temp3);
prev2Out = prevOut;
prevOut= _mm256_sub_ps(currComp, temp2);
prevIn = currIn;
// 出力を一時バッファーに格納
_mm256_storeu_ps((float *)(oTemp), prevOut);
//次の 2 つのピクセルを処理
currComp = _mm256_mul_ps(currInN, _mm256_broadcast_ss((float *)a0));
temp1 = _mm256_mul_ps(prevInN, _mm256_broadcast_ss((float *)a1));
temp2 = _mm256_mul_ps(prevOutN, _mm256_broadcast_ss((float *)b1));
temp3 = _mm256_mul_ps(prev2OutN, _mm256_broadcast_ss((float *)b2));
currComp = _mm256_add_ps(currComp, temp1);
temp2 = _mm256_add_ps(temp2, temp3);
prev2OutN = prevOutN;
prevOutN= _mm256_sub_ps(currComp, temp2);
prevInN = currInN;
_mm256_storeu_ps((float *)(oTemp+8), prevOutN);
id += 4; oTemp += 16; // 次の行に移動
} //height = j ループ
表 3: 縦方向の左から右のパスループ
縦方向の右から左のパスは左から右のパスに似ています。横方向のパスの出力を、各列の最後のピクセルからその列の最初のピクセルに処理します。256 ビット・ロード命令を使用して、以前のパスの出力をロードします。このパスで計算した出力を縦方向の左から右のパスの出力に追加します。最終的な出力を 32 ビット RGBA 形式にパックします。縦方向の右から左のパスは、それぞれの反復で 4 つのパックドピクセルを書きます。
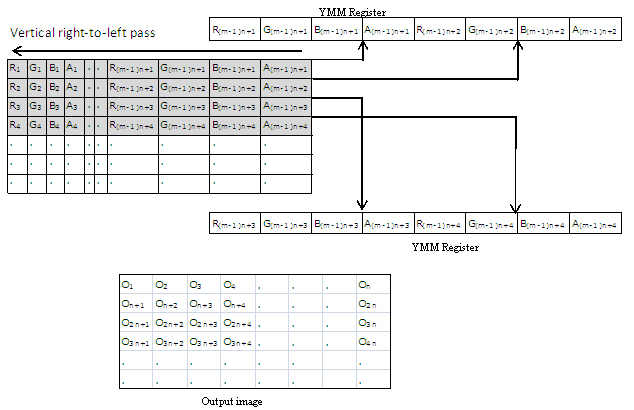
図 6: 縦方向の右から左のパス
// height -入力イメージの幅
// id - 入力の float ポインター (横方向のパスの出力)
// od - 出力バッファーの float ポインター - 縦方向のパスの入力
// oTemp - 左から右のパスと右から左のパス間の小さな一時出力バッファー
for (int y = height-1; y >= 0; y--) {
// 2 つの入力ピクセルをロード
inNext = _mm256_castps128_ps256(_mm_loadu_ps((float *) id));
inNext = _mm256_insertf128_ps(inNext, _mm_loadu_ps((float *)(id+4*height)), 0x1);
// さらに 2 つの入力ピクセルをロード
inNextN = _mm256_castps128_ps256(_mm_loadu_ps((float *) (id+8*height)));
inNextN = _mm256_insertf128_ps(inNextN, _mm_loadu_ps((float *)(id+12*height)), 0x1);
//左から右のパスの出力を取得
output = _mm256_load_ps((float *) (oTemp));
currComp = _mm256_mul_ps(currIn, _mm256_broadcast_ss((float *)a2));
temp1 = _mm256_mul_ps(prevIn, _mm256_broadcast_ss((float *)a3));
temp2 = _mm256_mul_ps(prevOut, _mm256_broadcast_ss((float *)b1));
temp3 = _mm256_mul_ps(prev2Out, _mm256_broadcast_ss((float *)b2));
currComp = _mm256_add_ps(currComp, temp1);
temp2 = _mm256_add_ps(temp2, temp3);
prev2Out = prevOut;
prevOut= _mm256_sub_ps(currComp, temp2);
prevIn = currIn;
currIn = inNext;
//現在の出力を左から右のパスの出力に追加
output = _mm256_add_ps(output, prevOut);
output = _mm256_castsi256_ps(_mm256_cvttps_epi32(output));
__m128i output2 = _mm_castps_si128(_mm256_extractf128_ps(output, 1));
__m128i output1 = _mm_castps_si128(_mm256_castps256_ps128(output));
//左から右のパスの出力を取得
outputN = _mm256_loadu_ps((float *) (oTemp+8));
currComp = _mm256_mul_ps(currInN, _mm256_broadcast_ss((float *)a2));
temp1 = _mm256_mul_ps(prevInN, _mm256_broadcast_ss((float *)a3));
temp2 = _mm256_mul_ps(prevOutN, _mm256_broadcast_ss((float *)b1));
temp3 = _mm256_mul_ps(prev2OutN, _mm256_broadcast_ss((float *)b2));
currComp = _mm256_add_ps(currComp, temp1);
temp2 = _mm256_add_ps(temp2, temp3);
prev2OutN = prevOutN;
prevOutN= _mm256_sub_ps(currComp, temp2);
prevInN = currInN;
currInN = inNextN;
outputN = _mm256_add_ps(outputN, prevOutN);
outputN = _mm256_castsi256_ps(_mm256_cvttps_epi32(outputN));
//RGBA 形式に変換
__m128i output4 = _mm_castps_si128(_mm256_extractf128_ps(outputN, 1));
__m128i output3 = _mm_castps_si128(_mm256_castps256_ps128(outputN));
output1 = _mm_packus_epi32(output1, output2);
output3 = _mm_packus_epi32(output3, output4);
output1 = _mm_packus_epi16(output1, output3);
_mm_store_si128((__m128i *)(od), output1);
id -= 4; od -= width; oTemp -=16; // 前の行に移動
} //height = j ループ
表 4: 縦方向の右から左のパスループ
ツール
IIR ガウスぼかしフィルターは、インテル® C/C++ コンパイラーの組み込み関数を使用して記述されています。インテル® C/C++ コンパイラーの組み込み関数については、『インテル® Advanced Vector Extensions プログラミング・リファレンス』を参照してください。このフィルターは、インテル® C/C++ コンパイラー 11.1 以降を使用してコンパイルできます。
インテル® C/C++ コンパイラーは、自動ベクトル化、プロファイルに基づく最適化をサポートしています。また、インテル® スレッディング・ビルディング・ブロックおよび OpenMP* を利用してマルチスレッド・アプリケーションも作成できます。ここでは、OpenMP API を使用して IIR ガウスぼかしフィルターをスレッド化しています。
インテル® AVX Web サイト (http://software.intel.com/en-us/avx/) では、インテル® AVX 命令を使用して記述されたソフトウェアを支援、発展、エミュレート、解析するためのリンクを提供しています。インテル® ソフトウェア・デベロップメント・エミュレーター (インテル® SDE) を使用すると、新しいインテル® マイクロアーキテクチャー (開発コード名 Sandy Bridge) 以前の、インテル® AVX に対応していないシステムで、IIR ガウスぼかしフィルターをエミュレートすることができます。
品質解析
IIR ガウスぼかしフィルターは、パス間の中間出力のパックおよびアンパックを行わないことで、イメージ品質の劣化を防いでいます。各パスでパックおよびアンパックを行うと、丸め誤差が発生します。各パスの出力をパックして 2048x2048 のぼかされたイメージ ( = 40) を測定したときの二乗平均平方根誤差と SN 比は以下のとおりです。
| R チャンネル | G チャンネル | B チャンネル | |
| 二乗平均平方根誤差 (RMSE) | 1.6 | 1.6 | 1.6 |
| SN 比 (dB) | 38.0 | 36.3 | 36.5 |
パフォーマンス解析
インテル® AVX を使用した場合とインテル® SSE を使用した場合の IIR ガウスぼかしフィルターのパフォーマンスは以下のとおりです。
| イメージサイズ | インテル® SSE (サイクル/ピクセル) | インテル® AVX (サイクル/ピクセル) | インテル® AVX のパフォーマンス向上率 (対インテル® SSE) |
| 512x512 | 7.5 | 5.8 | 1.30 倍 |
| 1024x1024 | 11.5 | 8.5 | 1.35 倍 |
| 2048x2048 | 17.1 | 8.9 | 1.92 倍 |
IIR ガウスぼかしフィルターのパフォーマンスは、メモリーバンド幅、メモリー・レイテンシー、キャッシュの影響 (キャッシュブロック、キャッシュ・エビクション (追い出し)、キャッシュ置換、バンク競合) に依存します。インテル® AVX 命令を使用すると、最小セットの命令で 4 つのピクセルを並列に処理できるため、メモリーとキャッシュの影響が最小限に抑えられます。新しいインテル® AVX の 256 ビット・ロード命令は、CPU により多くのデータを転送します。データの 1 つのキャッシュライン (64 バイト - 4 つのアンパックピクセル) を一度に処理できるため、キャッシュブロックが減ります。
小さなイメージ/フレーム (512x512) では、インテル® AVX のパフォーマンスは 5.8 サイクル/ピクセルで、インテル® SSE 実装よりも 1.3 倍高速です。このケースでは、すべてのデータ (入力/中間/出力) が CPU キャッシュにほぼ収まるため、このパフォーマンス向上は、よりワイドなレジスターと少ない命令数によるものです。
解像度の高いイメージ (2048x2048) では、インテル® AVX のパフォーマンスは、インテル® SSE 実装よりも 1.92 倍高速です。このパフォーマンス向上は、インテル® AVX 実装では (256 ビット・レジスターと 256 ビット命令を使用して) 2 倍のデータをロード、処理、格納できることで、キャッシュブロックが少なくなり、メモリーバンド幅が効率的に使用されるという事実によるものです。
まとめ
インテル® AVX ベースの IIR ガウスぼかしフィルターは、インテル® SSE ベースの実装よりも優れたパフォーマンスを提供します。インテル® AVX の主な機能 - 256 ビット幅のレジスター、256 ビット・ロード、(3 オペランド形式の) より少ない命令、効率的なエンコーディング - を活用することで、より優れたパフォーマンスを得ることができます。この実装は、既存の浮動小数点コードをインテル® AVX に簡単に移植できることも示しています。
その他の実装
以下のようにインテル® AVX ベースの IIR ガウスフィルターの実装を変更して、より優れたパフォーマンスを得ることができます。
中間データのパック/アンパック
最初に説明した実装では、丸め誤差が発生しないようにパス間の出力をパック/アンパックしないことで、イメージ品質の劣化を防いでいます。縦方向のパスと横方向のパスの間の出力は、フルサイズのアンパックイメージです。イメージ品質が多少劣化してもかまわない場合、パス間でパックした出力を渡すことで、パフォーマンスを向上させることができます。メモリーバンド幅がボトルネックになる高解像度のフレーム/イメージでは、パスにパック/アンパック処理を追加しても、全体的なパフォーマンスは向上します。
小さなフレーム/イメージ (512x512) での処理
最初に説明した実装は小さなフレームイメージ (512x512) で最適なパフォーマンスが得られるように設計されているため、大きなフレーム/イメージは、小さなフレーム/イメージに分割して並列で処理することでパフォーマンスを向上させることができます。IIR アルゴリズムの性質により、各フレームの入力に余分なピクセルが必要です。余分なピクセルを追加で処理する必要がありますが、このオーバーヘッドは高くありません。
参考文献 (英語)
[1] Rachid Deriche - "Recursively implementing the Gaussian and its derivatives", http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.35.5904, 1993.[2] Lucas J. van Vliet, Ian T. Young and Piet W. Verbeek - "Recursive Gaussian derivative Filters", http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.75.1458&rep=rep1&type=pdf, 1998
[3] Dave Hale, "Recursive Gaussian Filters", http://www.cwp.mines.edu/Meetings/Project06/cwp546.pdf, CWP-546
[4] Luis Alvarez, Rachid Deriche, Francisco Santana - "Recursivity and PDE's in Image Processing", http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.32.5804, 2000
インテル® ソフトウェア製品のパフォーマンス/最適化に関する詳細は、最適化に関する注意事項 (英語) を参照してください。
編集部追加
本記事では、実践的なアプリケーションに対してインテル® AVX による実装が効果を発揮することを説明しています。サンプルコードには比較用に SSE での実装についても含まれます。まだインテル® コンパイラーをお持ちでない方は、是非ともインテル® C++ Composer XE Windows 版の評価版をご利用いただき、インテル® AVX によるパフォーマンス向上を実感してください。評価版のダウンロード、お問い合わせはエクセルソフト株式会社まで。
なお、本記事にてダウンロードできるサンプルコードは Windows 用です。Linux / Mac OS X 環境でお試しいただきたい場合には、ヘッダーファイル、関数、コンパイラーオプションを適切なものに置き換える必要があります。
